

Before Reading
Understand how heap allocates memory will be the most important and fundanmental part of heap exploitation—we cannot exploit the memory until we clearly know how it works. The mechanism and structure of the 'heap beast' can sometimes be ultra sophisticated and ambiguous, so that it requires us to dive into it with long-term and persistant effort. Therefore, I will keep this post updated by time when I have new thoughts or verify new standpoints during debugging in real-life project.
Many articles on the internet about Heap Exploitation are obsolete—the glibc source code constantly updates and there are many new security checks in nowaday inplementation. So some of the attack techniques are NOT working in modern programs. I will explain the new knowledge by analyzing the newest version of glibc source code.
Introduction
Ptmalloc (i.e. pthreads malloc) is the malloc implementation, aka GNU Allocator which includes malloc/free/realloc inplementations. It allows us to allocate memory depending on size and certain parameters that are controlled by users. It is one of the fastest dynamic memory allocators and upgraded to Ptmalloc2 from GNU glibc 2.3.3.
We consider such keywords regarding to a good general-purpose allocator: fast, space-conserving, portable, tunable, etc. We need to evaluate consistent balance across these factors in malloc-intensive programs. The keywords for Ptmalloc are fast & dynamic, which are vital important when comes to managing memory data structure like heap.
Heap is essentially a list of memory regions that a running program uses to store data dynamically. When we access memory through heap with CRUD operation (create, retrieve, update, delete), the speed is naturally slower than the stack structure—because in a stack frame, data/instruction is simply pushed & pulled into memory one by one. So we don't need to care about looking up specific memory addresses.
Since stack is much faster than heap, then why we would need it? Because sometimes we need to allocate memory dynamically in the program. Therefore heap is designed to cope with our need. The data stored in heap regions are requested during runtime. This also means when we don't use functions like malloc() in the program, heap will not be initiated in the memory zone.
To figure out how the Ptmalloc works, we will need to have a deep understanding of Heap Structure in advance:
- Arena
- Chunk
- Tcache
- Fast bins
- Unsorted bins
- Small bins
- Large bins
- Mmap
- etc.
Most of these structures locates at malloc_state in glibc source code. Though I will not explain them in this post, I will write other articles specifically for them and add a link for above list in the future. On the other hand, I highly recommend a channel on Youtube called Deep Linux that wonderfully explains these concepts. And I have had some discussion with the author in where I had different findings on the content.
Glibc Version
The details can be vary through different versions of glibc—it's constantly improving the inplementation and fixing vulnerabilities and bugs. Great changes happen on glibc 2.2.6, 2.3.1, etc., like adding tcache structure and enforcing safe linking. The version of glibc we are analyzing here will be 2.3.9, which is the newest release at the time I write this post.
Malloc
I use malloc the word to represent the concept/operation of requesting memory dynamically in a running program. In C, we use malloc functions (e.g. malloc(), realloc(), calloc(), etc.) for implementation. But when we have a look at the glibc source code, there's no function called malloc—it is only an alias for the function __libc_malloc that we actually call. Further, the __libc_malloc encapsulates the core function for the malloc inplementation—_int_malloc. We will analyze it like slicing an onion!
strong_alias (__libc_malloc, __malloc) strong_alias (__libc_malloc, malloc)
strong_alias (__libc_calloc, __calloc) weak_alias (__libc_calloc, calloc)
strong_alias (__libc_realloc, __realloc) strong_alias (__libc_realloc, realloc)
...__libc_malloc
Older versions of glibc check a hook function *(*hook)(size_t, const void *) at the very beginning of __libc_malloc. We used to corrupt the namely __malloc_hook function with system function to get shell in a heap exploitation. But apparently we can see that it is removed from the glibc 2.3.9 source code—so this is now no longer a practical way to attack. I will use '//' to add comments of my personal notes in the following source code (and in all future code snippets in this article):
/*
malloc(size_t n)
Returns a pointer to a newly allocated chunk of at least n bytes, or null
if no space is available. Additionally, on failure, errno is
set to ENOMEM on ANSI C systems.
If n is zero, malloc returns a minimum-sized chunk. (The minimum
size is 16 bytes on most 32bit systems, and 24 or 32 bytes on 64bit
systems.) On most systems, size_t is an unsigned type, so calls
with negative arguments are interpreted as requests for huge amounts
of space, which will often fail. The maximum supported value of n
differs across systems, but is in all cases less than the maximum
representable value of a size_t.
*/
void* __libc_malloc(size_t);
libc_hidden_proto (__libc_malloc)
void *
__libc_malloc (size_t bytes)
{
mstate ar_ptr;
void *victim;
// Check to prevent overflows when dealing with pointer arithmetic or differences. Because ptrdiff_t is signed, while size_t is unsigned. Guarantee no overflow happens when we cast a ptrdiff_t to a size_t.
_Static_assert (PTRDIFF_MAX <= SIZE_MAX / 2,
"PTRDIFF_MAX is not more than half of SIZE_MAX");
// Set up the main_arena. We can see here that the main_arena (heap) will up only when we first call _int_malloc.
if (!__malloc_initialized)
ptmalloc_init ();
#if USE_TCACHE
/* int_free also calls request2size, be careful to not pad twice. */
size_t tbytes = checked_request2size (bytes);
if (tbytes == 0)
{
__set_errno (ENOMEM);
return NULL;
}
size_t tc_idx = csize2tidx (tbytes);
MAYBE_INIT_TCACHE ();
DIAG_PUSH_NEEDS_COMMENT;
if (tc_idx < mp_.tcache_bins
&& tcache != NULL
&& tcache->counts[tc_idx] > 0)
{
victim = tcache_get (tc_idx);
return tag_new_usable (victim);
}
DIAG_POP_NEEDS_COMMENT;
#endif
// Single-thread situation will apply certain optimizations or simplifications.
if (SINGLE_THREAD_P)
{
victim = tag_new_usable (_int_malloc (&main_arena, bytes));
// check victim is indeed allocated, and it's not allocated by mmap()
assert (!victim || chunk_is_mmapped (mem2chunk (victim)) ||
// check to ensure victim actually belongs to the main_arena.
&main_arena == arena_for_chunk (mem2chunk (victim)));
return victim;
}
// Look for an arena to allocate memory.
arena_get (ar_ptr, bytes);
// This is where the 'malloc' actually happens
victim = _int_malloc (ar_ptr, bytes);
/* Retry with another arena only if we were able to find a usable arena
before. */
if (!victim && ar_ptr != NULL)
{
LIBC_PROBE (memory_malloc_retry, 1, bytes);
ar_ptr = arena_get_retry (ar_ptr, bytes);
victim = _int_malloc (ar_ptr, bytes);
}
// If we manage to allocate, we will then have to unlock (futex) the arena.
if (ar_ptr != NULL)
__libc_lock_unlock (ar_ptr->mutex);
victim = tag_new_usable (victim);
// 3 Results: fail to allocate; allocated by mmap; allocated in arena (heap).
assert (!victim || chunk_is_mmapped (mem2chunk (victim)) ||
ar_ptr == arena_for_chunk (mem2chunk (victim)));
return victim;
}Click here to see more code illustration
PTRDIFF_MAX: a macro defined in stddef.h and represents the maximum value that can be held by a ptrdiff_t type. The ptrdiff_t type is used to store the difference between two pointers. Essentially, it measures how far apart two pointers can be in the memory.
SINGLE_THREAD_P: a macro that determines whether multiple threads are active. If only one thread is in use, certain optimizations or simplifications can be applied because there is no need for locking or other concurrency mechanisms.
Inside this part of source code, we find out that it's actually performing checks and then returns a pointer (victim) to the allocation—and it always does even when the parameter n is 0 (returns a chunk in size of 24 or 32 bytes in x64 system). And it's actually calling the function _int_malloc inside to complete the actual 'malloc'. Now we are going to dive deeper in this function.
_int_malloc
There are 643 lines (from line 3844 to 4487) of source code for the _int_malloc. So we won't post all the codes to analyze here. But it happens to probably be the most important function regarding to heap exploitation. We should really look into it when we have time. And the following declared properties are vital important through the process:
static void *
_int_malloc (mstate av, size_t bytes)
{
INTERNAL_SIZE_T nb; /* normalized request size */
unsigned int idx; /* associated bin index */
mbinptr bin; /* associated bin */
mchunkptr victim; /* inspected/selected chunk */
INTERNAL_SIZE_T size; /* its size */
int victim_index; /* its bin index */
mchunkptr remainder; /* remainder from a split */
unsigned long remainder_size; /* its size */
unsigned int block; /* bit map traverser */
unsigned int bit; /* bit map traverser */
unsigned int map; /* current word of binmap */
mchunkptr fwd; /* misc temp for linking */
mchunkptr bck; /* misc temp for linking */I will post the summary of the _int_malloc function about the parts we hackers cybersecurity researchers need to care for now:
- The function allocates differently depending on the size of requested chunk and the frequency of use for bins (fastbin chunk, small request, large request); It's decided by the variable nb = checked_request2size (bytes);
- As tcache always will be enabled nowadays, _int_malloc will trigger tcache stashing—when small-request related bins (fastbin, smallbin) are not empty, chunks in the bins will be stashed into tcache bins. We will dive into more detailed source code in later part;
- The function scans through all bins with free'd chunks inside them in a sequence from smallest to biggest. It tries hard to utilize free'd chunks inside bins as many as possible. So Ptmalloc designs an iteration process to loop around, which I would like to call it the Big Loop. This could be very sophisticated and will be the most important part for this post in our following analysis;
- When free'd chunks inside bins are eventually not availble for our request, the function _int_malloc will try to request allocation from top chunk;
- When top chunk does not satisfy our request, it will call for sysmalloc to allocate memory from system.
This is a short summary for the core inplementation defined by _int_malloc. We are now going to dive deeper with more source code to analyze the order when malloc is called. It has a great impact on our future Heap Exploitation as we always need to manage an arbitary allocation to complete the attack.
Malloc Algorithms
We need to have a very clear mindmap over how all those bins work when we use malloc() to request a specific size of memory. Because we will utilize these rules defined by _int_malloc to abuse the heap. For better understanding, here I will denote the rules as Malloc Algorithms, while we will discuss the Free Algorithms in the next subsequent chapter.
To better illustrate the rules, I will also denote some keywords for our convenience in the future analysis:
- malloc_arg: the argument when we call functions like malloc(malloc_arg), namely the requested size of memory from user demand.
- chunk_size: the actual size of a chunk. In x64 system, when we malloc(malloc_arg), the chunk_size here will always be added the size metadata (malloc_arg + 0x10).
- chunk_ptr: the pointer returned to us after the functions like malloc() returns (*chunk_ptr = malloc(malloc_arg)). It points to the entrance of the user-data-input filed for the chunk.
- chunk_hdr: the pointer points to the real entrance of a chunk. It's always (chunk_ptr + 0x10) in x64 system.
As I mentioned before, I may update the following analysis during life-long research on glibc or after it has an updated version. Now let's begin:
Step 1: As we can see in the source code of __libc_malloc, the heap will only be initialized after the first call of the malloc-family functions. Otherwise we won't see any heap structure via commands like vmmap in gdb.
Step 2: Then we will first look up tcache for a free'd chunk that suits for our request size, in range of 0x20 to 0x410. By default, there are maximun 7 chunks inside each tcache bin. This amount is important for future heap exploitation.
#define TCACHE_MAX_BINS 64 // Number of tcache bins based on different chunk sizes
#define TCACHE_FILL_COUNT 7 // Maximum chunks in each tcache bin
struct tcache_perthread_struct
{
uint16_t counts[TCACHE_MAX_BINS];
tcache_entry *entries[TCACHE_MAX_BINS];
};To be notice, tcache bins are managed by a struct in glibc called tcache_perthread_struct. It does NOT belong to main_arena—it is maintained independently for each thread.
When tcache is enabled, we will see a memory region in size of 0x290 by default, which will be allocated as the heap is initialized. It stores values related to the tcache bins. We usually leverage them in heap exploitation:
- For example, this region starts from the heap base. So we will use it to calculated heap base address in some cases;
- At the location with offet of 0x90, it records the entry chunk of tcache_bin[0x20], and the next of tcache_bin[0x30], and so forth; This could be leveraged to perform Safe Link Double Protect attack;
- The above 0x90 region will record values in other ways. For example, when we manage to free two chunks in size of 0x3e0, 0x3f0 into the tcache bins, the data at the offset of 0x88 in this structure will become 0x10001. Then later we can utilize it as our fake chunk size. This is the House of Water attack that I will discuss in other future posts.
Click to see more details about tcache bins
The number of chunks allowed per tcache bin is determined by the constant TCACHE_MAX_BINS and the array tcache->counts[tc_idx]. Specifically, TCACHE_MAX_BINS defines the number of different bin sizes, and for each bin size, there's an associated count in tcache->counts[tc_idx] which keeps track of the current number of chunks in that bin.
The actual limit for chunks in each tcache bin is usually set by the constant TCACHE_FILL_COUNT, which is typically defined in the malloc.c in the glibc source code. This constant sets a limit on how many chunks can be stored in a single bin before the allocator stops adding new free'd chunks to the tcache and instead returns them to the central heap or arena mechanism.
Step 3: If tcache bins cannot satify our request, Ptmalloc will check for the main_arena. Before getting in the main_arena, we need first obtain lock for the allocation area to prevent multi-threaded conflicts. It's namely the mutex at the very first position of main_arena. By default, its value equals 1. And now we will call the futex function to unlock it making mutex=0.
The futex function will take time which costs us in a running program. And that's why tcache is fast for one main reason.
Step 4: If the chunk_size is less than the maxiumun of fast bins within size of 0x80 (128 bytes), namely the malloc_arg less than 0x78, Ptmalloc will try to find a suitable chunk in the fast bins. If one is found, allocation is complete. Otherwise, proceed to the next step.
Step 5: If the chunk_size is less than the maximum of small bins within size of 0x400 (1024KB), search the small bins for a suitable chunk. If one is found, allocation is complete. Otherwise, proceed to the next step.
⚠ Step 4 and Step 5 are relatively easy and fast. The chunk_size range covers these bins is denoted as small request in glibc:
/*
If a small request, check regular bin. Since these "smallbins"
hold one size each, no searching within bins is necessary.
(For a large request, we need to wait until unsorted chunks are
processed to find best fit. But for small ones, fits are exact
anyway, so we can check now, which is faster.)
*/When the malloc functions are called, and small-request related bins (fast bins, small bins—size from 0x20 to 0x410) are not empty, chunks in these bins will be stashed into tcache bins by the function tcache_put, which we have talked about above. This code snippiet lies at the very beginning of _int_malloc:
#if USE_TCACHE
/* While we're here, if we see other chunks of the same size,
stash them in the tcache. */
size_t tc_idx = csize2tidx (nb);
if (tcache != NULL && tc_idx < mp_.tcache_bins)
{
mchunkptr tc_victim;
/* While bin not empty and tcache not full, copy chunks over. */
while (tcache->counts[tc_idx] < mp_.tcache_count
&& (tc_victim = last (bin)) != bin)
{
if (tc_victim != 0)
{
bck = tc_victim->bk;
set_inuse_bit_at_offset (tc_victim, nb);
if (av != &main_arena)
set_non_main_arena (tc_victim);
bin->bk = bck;
bck->fd = bin;
tcache_put (tc_victim, tc_idx);
}
}
}
#endifThis mechanism is also important in the Malloc Algorithms that we will further discuss its inplementation in Tcache Stashing Unlink Attack, Fastbin Reverse into Tcache Attack, etc.
Step 6: If above procudure cannot satify our request, Ptmalloc will search unsorted bin. It triggers the function malloc_consolidate(av) to try to consolidate adjacent free'd chunks in fast bins and remove all of them to unsorted bins—but only under certain condition that I will introduce later. Then it starts the so-called the Big Loop I mentioned before. If there's now an exact-fit chunk in the unsorted bin, the target chunk will be returned to us. After this, all the other chunks remaining in the unsorted bin will be allocated to corresponding small/large bins (won't go to fast bins but only small bins even the chunk is small enough)—This will be the only step that Ptmalloc inserts chunks into S/L bins. This part could be the most sophisticated section for the Malloc Algorithms. I will now analyze it and explain other situations step by step along with some debugging!
Firstly, we will talk about malloc_consolidate. As we introduced above, it consolidates adjacent free'd chunks, then releases both the consolidated & unconsolidated chunks and moves them to unsorted bin. It will only be triggered at this section (it does work in some other procedures differently) when we malloc a large request, i.e. the malloc_arg must be greater than 0x400 (1024 bytes) when we call malloc(). It aims to reduce fragmentation caused by fastbin chunks (with PRE_INUSE bit always set to 1, it's sticking on the memory).
/*
If this is a large request, consolidate fastbins before continuing.
While it might look excessive to kill all fastbins before
even seeing if there is space available, this avoids
fragmentation problems normally associated with fastbins.
Also, in practice, programs tend to have runs of either small or
large requests, but less often mixtures, so consolidation is not
invoked all that often in most programs. And the programs that
it is called frequently in otherwise tend to fragment.
*/
else
{
idx = largebin_index (nb);
if (atomic_load_relaxed (&av->have_fastchunks))
malloc_consolidate (av);
}Therefore, this won't be triggered if we make a small request. I have done a test on this: we free 10 small chunks in size of 0x50—7 in tcache_bin[0x50] and 3 in fast_bin[0x50]. Then we use malloc() to request a chunk in size of 0x80. Those 3 free'd adjacent chunks in fast bin has not been consolidated or moved to unsorted bin. We got the returned allocation directly from top chunk.

In conclusion, malloc_consolidate will be triggered if we make a large request. Following I will continue to talk about the situation when we make a small request.
Secondly, how would Ptmalloc do when it's a small request at this stage? The glibc explains for this:
/*
If a small request, try to use last remainder if it is the only chunk in unsorted bin. This helps promote locality for runs of consecutive small requests. This is the only exception to best-fit, and applies only when there is no exact fit for a small chunk.
*/It states quit a situation here. My understanding is that when there're multiple chunks inside the unsorted bin, the Big Loop will continue looping and Ptmalloc will try to find a suitable chunk with other mechanisms (like the spilting we are going to introduce). And when there's only one last remainder chunk inside the unsorted bin—typically when a chunk got spilted in bins and the last remainder will be placed to unsorted bin, the following chunk-splitting procedure will be triggered to execute inside the unsorted bin.
Before further step into this, I will need to make some statement on the concept of exact-fit and best-fit that we mentioned above. An exact-fit is easy to understand. It means there's free'd chunk in size of what we exactly want. When there's it in the unsorted bin or S/L bins, it will be returned to us for our request.
While the best-fit refers to the free'd chunk which is larger than our request size, and it has the closest size regarding to our application inside the unsorted bin & S/L bins. There's also a bitmap property, which I am not going to further discuss in this section. It allows Ptmalloc to scan chunks inside the bins from small to big. When it first meet the smallest matched free'd chunk, i.e. the best-fit chunk, it spilts this chunk into two parts—returns one for our request; and if the remaining one is larger than the MINSIZE (0x20), it becomes the namely last remainder and will be moved to unsorted bin.
I had some doubts for where (what bins) the splitting will happen? My answer now is that it happens in unsorted bin, small bins, large bins. Some articles claim that this won't be executed inside the unsorted bin or others, that I don't think so at the moment. I have also done some test debug to prove my opinion.
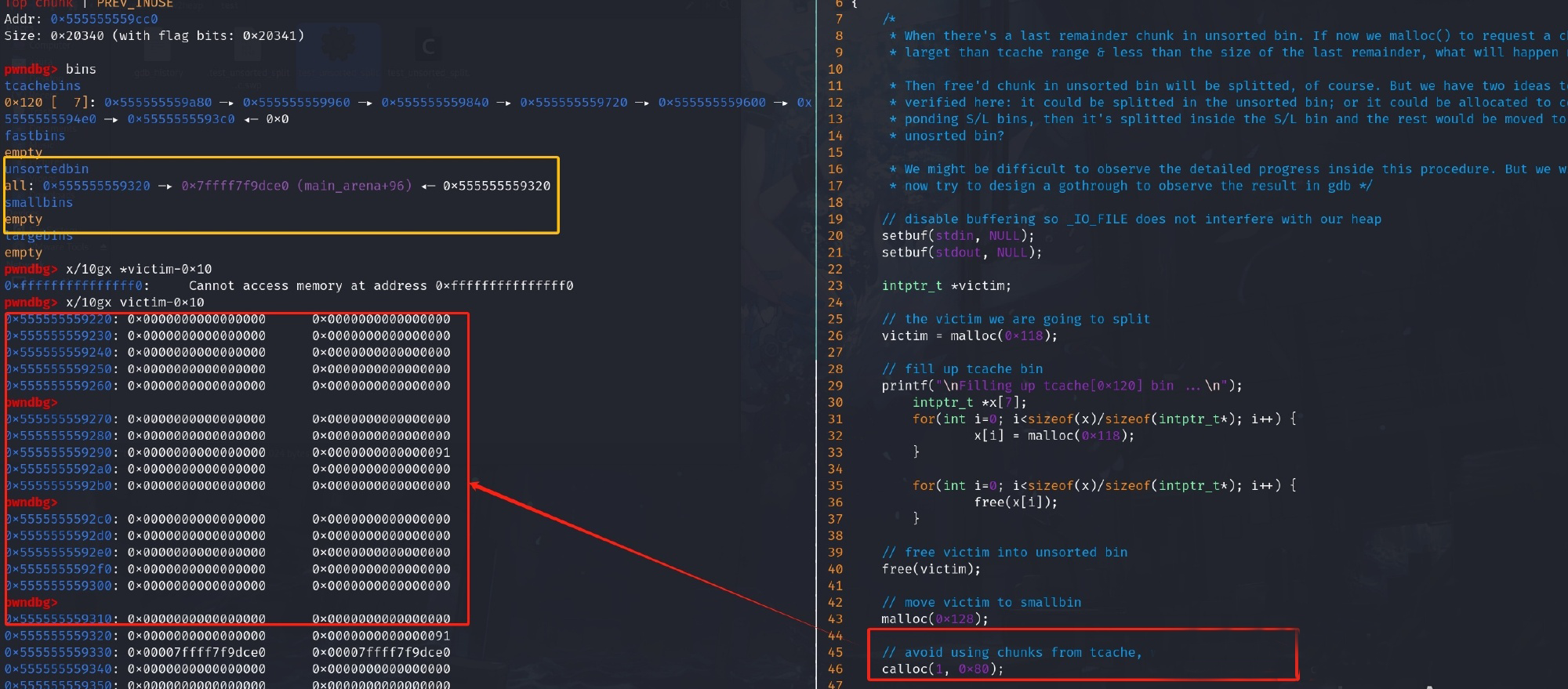
In above exam, I make a way to put the victim chunk into smallbin. Then using calloc to make a request that is smaller than our victim in smallbin (won't allocate chunks from tcache using calloc). We found out that victim is indeed split and the last remainder has been moved to unsorted bin.
In terms of the splitting process in unsorted bin, we can refer to the source code in glibc:
/*
If a small request, try to use last remainder if it is the
only chunk in unsorted bin. This helps promote locality for
runs of consecutive small requests. This is the only
exception to best-fit, and applies only when there is
no exact fit for a small chunk.
*/
if (in_smallbin_range (nb) &&
bck == unsorted_chunks (av) &&
victim == av->last_remainder &&
(unsigned long) (size) > (unsigned long) (nb + MINSIZE))
{
/* split and reattach remainder */
remainder_size = size - nb;
remainder = chunk_at_offset (victim, nb);
unsorted_chunks (av)->bk = unsorted_chunks (av)->fd = remainder;
av->last_remainder = remainder;
remainder->bk = remainder->fd = unsorted_chunks (av);
if (!in_smallbin_range (remainder_size))
{
remainder->fd_nextsize = NULL;
remainder->bk_nextsize = NULL;
}
set_head (victim, nb | PREV_INUSE |
(av != &main_arena ? NON_MAIN_ARENA : 0));
set_head (remainder, remainder_size | PREV_INUSE);
set_foot (remainder, remainder_size);
check_malloced_chunk (av, victim, nb);
void *p = chunk2mem (victim);
alloc_perturb (p, bytes);
return p;
}
/* remove from unsorted list */
unsorted_chunks (av)->bk = bck;
bck->fd = unsorted_chunks (av);
// Won't trigger any other mechanism if it's exact-fit. Return to us immediately!
/* Take now instead of binning if exact fit */
if (size == nb)
{
set_inuse_bit_at_offset (victim, size);
if (av != &main_arena)
set_non_main_arena (victim);
#if USE_TCACHE
/* Fill cache first, return to user only if cache fills.
We may return one of these chunks later. */
if (tcache_nb > 0
&& tcache->counts[tc_idx] < mp_.tcache_count)
{
tcache_put (victim, tc_idx);
return_cached = 1;
continue;
}
else
{
#endif
check_malloced_chunk (av, victim, nb);
void *p = chunk2mem (victim);
alloc_perturb (p, bytes);
return p;
#if USE_TCACHE
}
#endif
}
/* place chunk in bin */
if (in_smallbin_range (size))
{
victim_index = smallbin_index (size);
bck = bin_at (av, victim_index);
fwd = bck->fd;
}
else
{
victim_index = largebin_index (size);
bck = bin_at (av, victim_index);
fwd = bck->fd;
...By analyzing above code, we can see that after splitting in unsorted bin, the last remainder will be reattached and unlinked then placed into corresponding S/L bins. Surprisingly, the one of our request size will be moved to tcache first when corresponding tcache bin is not filled. Then Ptmalloc will return us for our request from the cached ones—this tcache-related proccess seems to happen only when the splitting process is executed in the unsorted bin.
#if USE_TCACHE
/* If we've processed as many chunks as we're allowed while
filling the cache, return one of the cached ones. */
++tcache_unsorted_count;
if (return_cached
&& mp_.tcache_unsorted_limit > 0
&& tcache_unsorted_count > mp_.tcache_unsorted_limit)
{
return tcache_get (tc_idx);
}
#endif
#define MAX_ITERS 10000
if (++iters >= MAX_ITERS)
break;
}
#if USE_TCACHE
/* If all the small chunks we found ended up cached, return one now. */
if (return_cached)
{
return tcache_get (tc_idx);
}
#endifAs for the splitting process in large bins, it of course will be done properly. And we will discuss more about large bins in the next step.
/*
If a large request, scan through the chunks of current bin in
sorted order to find smallest that fits. Use the skip list for this.
*/Step 7: Searching for large bins should have been part of step 6. However, it deals only with large requests for our application. Besides, large bins are special—they store large chunks of different sizes inside each large bin. Therefore I list it in step 7 to discuss separately.
I have done quite a lot researches on the large bins in the notes stored at my local machine. But I won't illustrate this knowledge now for it's not our point when talking about Ptmalloc. I will post a link here after I manage to post other articles related to large bins in this blog.
The point I want to declare is that the free'd chunks are in descending order in the large bin sorted by the sorted linked list. But the search order of Ptmalloc is in opposite—it searches suitable chunk in ascending order, from the smallest to the biggest. It also works with the exact-fit and other splitting mechanisms. The last remainder after splitting process will also be placed back in the unsorted bin.
Now the Big Loop will iter. It will try hard to utilize the free'd chunks in different bins. There's an iter-related macro in glibc that defines the counts of iteration:
#define MAX_ITERS 10000
if (++iters >= MAX_ITERS)
break;
}Step 8: After all this effort, if Ptmalloc still cannot find a suitable chunk for our request, it will now has to consider the top chunk to be used for allocation. When the top chunk is larger than the memory requested by the us, it will be split into two parts: one for the chunk matched our request, and the other one for the remainder chunk. The remainder chunk will then become the new top chunk.
There're some attack methods against the top chunk as well, like the famous House of Force. But it has been patched for the new version glibc. We will further introduce more in other posts.
Step 9: If top chunk even cannot satisfy our request, that means we are requesting a quite large memory. We will need other functions rather than malloc to help us with the allocation.
Regarding to 'small' & 'large' description, here's the official comment in glibc:
/*
The main properties of the algorithms are:
* For large (>= 512 bytes) requests, it is a pure best-fit allocator,
with ties normally decided via FIFO (i.e. least recently used).
* For small (<= 64 bytes by default) requests, it is a caching
allocator, that maintains pools of quickly recycled chunks.
* In between, and for combinations of large and small requests, it does
the best it can trying to meet both goals at once.
* For very large requests (>= 128KB by default), it relies on system
memory mapping facilities, if supported.
*/ We will talk about allocation for the very large requests (>= 128KB by default). Besides, there's the situation that our request is not larger than 128KB (the mp_.mmap_threshold), but the top chunk don't have enough space on it. Now we are going to need the new function sysmalloc in glibc, while sbrk is the traditional way. We are going to look into both of them repectively.
Traditionally, we need the help of the glibc function sbrk to extend top chunk (heap). Regarding to the sbrk() in glibc (to inplement brk() in linux), the video of Deep Linux (from 30:00 - Seeing how sbrk creates heap) explains well.
In this case, sbrk will extend the top chunk by the requested amount—the brk_base is connected with data section in memory layout, which is a solid rock; sbrk will extend heap (main_arena) upward (toward higher addresses) to increase the size of top chunk.
There is an attack inplementation for this called House of Orange, which is special & famous in heap exploitation. Unluckily, it has also been patched now. But we will discuss this attack mindset and learn something from it in the future. I will first post an image here to illustrate the mindmap for us to better understand this specific Malloc Algorithms.
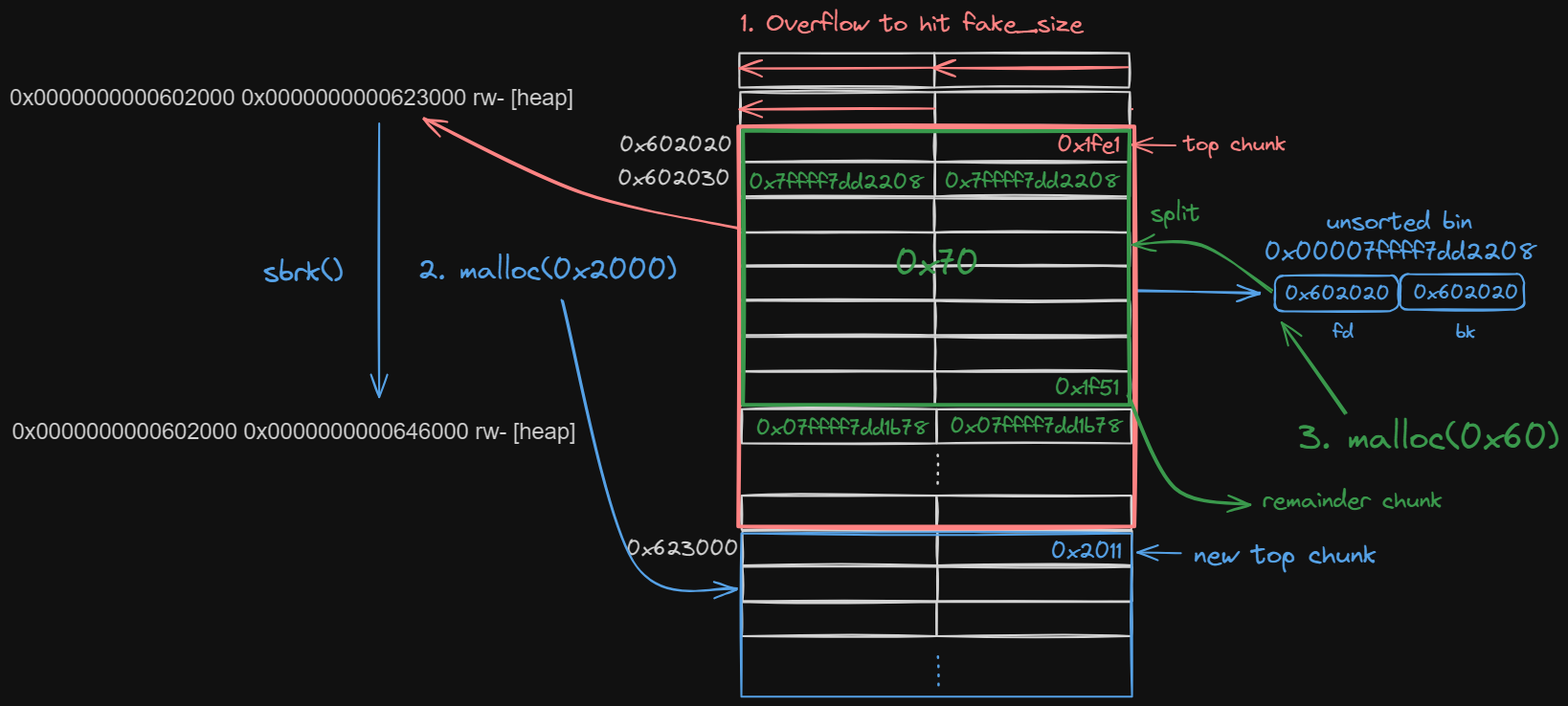
In this example, we can see that when Ptmalloc calls sbrk(), the heap_end is extended from 0x623000 to 0x646000 as we call malloc(0x2000). It returns us a chunk which I marked blue. It locates at where sbrk starts to break—and it has to be 4KB page aligned. Then the old top chunk marked in red will be placed in unsorted bin—it's the Malloc Algorithms that we leverage to perform House of Orange.
⚠ I will expand the topic a bit about sbrk for the main_arena—__malloc_trim and pad. Pad refers to the property mp_.top_pad in glibc. Its default value is 0x20000 (131072 bytes). This is exactly the size of the main_arena that we observe in gdb. When we use sbrk to extend heap, the main_arena grows bigger. If the allocated memory is then free'd after use, the function __malloc_trim will step in and gives back the excessive memory over mp_.top_pad to system.
Nowaday, The glibc tends to use sysmalloc, i.e. mmap in many cases. The primary purpose of sysmalloc_mmap is to allocate large blocks of memory directly from the system's virtual memory. This is typically used for large allocations to avoid fragmenting the heap managed by sbrk.
static void *
sysmalloc_mmap (INTERNAL_SIZE_T nb, size_t pagesize, int extra_flags, mstate av)
{
long int size;
/*
Round up size to nearest page. For mmapped chunks, the overhead is one
SIZE_SZ unit larger than for normal chunks, because there is no
following chunk whose prev_size field could be used.
See the front_misalign handling below, for glibc there is no need for
further alignments unless we have have high alignment.
*/
if (MALLOC_ALIGNMENT == CHUNK_HDR_SZ)
size = ALIGN_UP (nb + SIZE_SZ, pagesize);
else
size = ALIGN_UP (nb + SIZE_SZ + MALLOC_ALIGN_MASK, pagesize);
/* Don't try if size wraps around 0. */
if ((unsigned long) (size) <= (unsigned long) (nb))
return MAP_FAILED;
char *mm = (char *) MMAP (0, size,
mtag_mmap_flags | PROT_READ | PROT_WRITE,
extra_flags);
if (mm == MAP_FAILED)
return mm;
#ifdef MAP_HUGETLB
if (!(extra_flags & MAP_HUGETLB))
madvise_thp (mm, size);
#endif
__set_vma_name (mm, size, " glibc: malloc");
/*
The offset to the start of the mmapped region is stored in the prev_size
field of the chunk. This allows us to adjust returned start address to
meet alignment requirements here and in memalign(), and still be able to
compute proper address argument for later munmap in free() and realloc().
*/
INTERNAL_SIZE_T front_misalign; /* unusable bytes at front of new space */
// The function ensures that the returned memory address meets the alignment requirements.
if (MALLOC_ALIGNMENT == CHUNK_HDR_SZ)
{
/* For glibc, chunk2mem increases the address by CHUNK_HDR_SZ and
MALLOC_ALIGN_MASK is CHUNK_HDR_SZ-1. Each mmap'ed area is page
aligned and therefore definitely MALLOC_ALIGN_MASK-aligned. */
assert (((INTERNAL_SIZE_T) chunk2mem (mm) & MALLOC_ALIGN_MASK) == 0);
front_misalign = 0;
}
else
front_misalign = (INTERNAL_SIZE_T) chunk2mem (mm) & MALLOC_ALIGN_MASK;
mchunkptr p; /* the allocated/returned chunk */
if (front_misalign > 0)
{
// If the alignment is not correct, it corrects this by adjusting the starting point of the allocated chunk.
ptrdiff_t correction = MALLOC_ALIGNMENT - front_misalign;
p = (mchunkptr) (mm + correction);
set_prev_size (p, correction);
// Set IS_MMAPED bit to 1.
set_head (p, (size - correction) | IS_MMAPPED);
}
else
{
p = (mchunkptr) mm;
set_prev_size (p, 0);
// Set IS_MMAPED bit to 1.
set_head (p, size | IS_MMAPPED);
}
/* update statistics */
int new = atomic_fetch_add_relaxed (&mp_.n_mmaps, 1) + 1;
atomic_max (&mp_.max_n_mmaps, new);
unsigned long sum;
sum = atomic_fetch_add_relaxed (&mp_.mmapped_mem, size) + size;
atomic_max (&mp_.max_mmapped_mem, sum);
check_chunk (av, p);
return chunk2mem (p);
}The function sysmalloc_mmap directly allocates memory from the system via mmap, bypassing the usual malloc arenas and heap managed by sbrk. This is particularly useful for large allocations to ensure that large blocks of memory are managed more efficiently and do not fragment the normal heap.
It plays a crucial role in memory management for applications requiring large blocks of memory. By using mmap, it also ensures that these large blocks can be individually returned to the system upon deallocation (munmap), which can be more efficient than trying to coalesce and manage these within the normal free lists.
The function does not manipulate the heap via sbrk; rather, it allocates memory outside of the normal heap area managed by sbrk. This approach is used specifically to avoid the limitations and potential fragmentation issues associated with extending the heap for large allocations.
In comparison, The function sysmalloc_mmap does not manipulate the heap via sbrk; rather, it allocates memory outside of the normal heap area managed by sbrk. This approach is used specifically to avoid the limitations and potential fragmentation issues associated with extending the heap for large allocations.
- In modern memory management within operating systems like Linux, the decision between using sbrk and mmap() for memory allocation is based on the size of the allocation and the specific requirements and configurations of glibc used in many Linux systems.
- Traditionally, sbrk was used for smaller, more frequent allocations because it simply extends the heap in a linear fashion without involving the kernel's memory management capabilities beyond adjusting the program break.
- Over time, the use of sbrk has become less common in favor of mmap(), especially in multithreaded applications. Modern implementations of memory allocators like glibc use sbrk less frequently, primarily due to its limitations in handling memory efficiently in concurrent environments and its tendency to cause fragmentation.
- In multithreaded applications, mmap() is favored due to its ability to handle memory in a way that minimizes contention among threads.
- As the comment in glibc source code, it recommends mmap over sbrk. Because mmap integrates better with modern operating system capabilities, such as paging and virtual memory management.
Step 10: At last, we need to lock the main_arena again if the allocation is done inside main_arena, seting the mutex back to 1 (If the allocation is done via tcache or mmap, we don't need to lock process which boost program efficiency).
Free
Ptmalloc includes memeory-released implementation of the free functions in the GNU C Library (glibc). This part will be less sophisticated than the malloc part. But there are many security check involving the free procedure. We need to have a clear understanding on it to bypass all the checks during a heap exploitation.
Just like the malloc functions, there is actually no so-called free function in glibc. It's an alias for the __libc_free function which we are going to analyze:
strong_alias (__libc_free, __free) strong_alias (__libc_free, free)__libc_free
Just like the malloc, older version of the function __libc_free will first check if there's an hook function with effective values, which would allow us to overwrite it with a location of some dangerous function like system to pwn:
// Obsolete old version
void (*hook)(void *, const void *) = atomic_forced_read(__free_hook);
if (__builtin_expect(hook != NULL, 0)) {
(*hook)(mem, RETURN_ADDRESS(0));
return;
}Since it is now Obsolete, we can see the following new glic source code has removed this part for safety. This attack method will be no longer practical in most cases (some programs would still set to activate hook functions, but they are now banned by default). Let's then look closely into the __libc_free function. I will also use '//' as the way to add my personal comments:
void
__libc_free (void *mem)
{
mstate ar_ptr;
mchunkptr p; /* chunk corresponding to mem */
// 0 is allowed to free. Sometimes we can ustilize this.
if (mem == 0) /* free(0) has no effect */
return;
/* Quickly check that the freed pointer matches the tag for the memory.
This gives a useful double-free detection. */
// Check if memory tagging (mtag) is enabled. Memory tags are a mechanism that can be used to track and verify the integrity of memory allocations and deallocations.
// By checking the tag associated with the memory being free'd, the system can verify whether the operation is legitimate or if it is attempting to free memory that has already been freed.
if (__glibc_unlikely (mtag_enabled))
*(volatile char *)mem;
int err = errno;
// turn mem into chunk status.
p = mem2chunk (mem);
// If it is an Mmap'ed chunk, release it in this special way.
if (chunk_is_mmapped (p)) /* release mmapped memory. */
{
/* See if the dynamic brk/mmap threshold needs adjusting.
Dumped fake mmapped chunks do not affect the threshold. */
if (!mp_.no_dyn_threshold
&& chunksize_nomask (p) > mp_.mmap_threshold
&& chunksize_nomask (p) <= DEFAULT_MMAP_THRESHOLD_MAX)
{
mp_.mmap_threshold = chunksize (p);
mp_.trim_threshold = 2 * mp_.mmap_threshold;
LIBC_PROBE (memory_mallopt_free_dyn_thresholds, 2,
mp_.mmap_threshold, mp_.trim_threshold);
}
// Release the chunk back to system by using munmap.
munmap_chunk (p);
}
else
{
MAYBE_INIT_TCACHE ();
/* Mark the chunk as belonging to the library again. */
// New to modern version of glibc.
(void)tag_region (chunk2mem (p), memsize (p));
// Get the pointer of allocation according to the chunk properties.
ar_ptr = arena_for_chunk (p);
// The place where we actually execute free.
_int_free (ar_ptr, p, 0);
}
__set_errno (err);
}
libc_hidden_def (__libc_free)Click here to see more code explaination
- Memory Tagging:
mtagis a security feature aimed at enhancing memory safety by adding metadata, or "tags," to chunks of memory. - Allocation Tag: By associating a unique tag with each allocated memory block, the system can verify the integrity of memory operations. This check ensures that each memory operation (like free or read/write) corresponds to a block with a matching tag, thus confirming that the operation is legitimate and safe. Tag is usually stored in a way that it remains closely linked with the memory block, such as in the header of the allocation or in a separate tag storage area.
- Deallocation Tag: When memory is freed, the tag can be checked again to ensure the block has not been corrupted or already freed. After freeing, the tag might be cleared or marked as inactive to prevent reuse-after-free errors.
_int_free
Again, just like malloc, we can discover that _int_free is the actual core function encapsulated inside __libc_free. So we will focus on it when analyzing the Free Algorithms.
Well, the code snippet of function _int_free is not as long as _int_malloc, but it still has a length of 205 lines (from line 4493 to 4698). I wasn't planning to analyze all of it. But then I eventually decide to put some comments in an overall view for the source code. Because we will need to really understand the security checks to figure out the bypass technique:
static void
_int_free (mstate av, mchunkptr p, int have_lock)
{
// Old versions declare much more variables at this part.
INTERNAL_SIZE_T size; /* its size */
mfastbinptr *fb; /* associated fastbin */
// Get size of the chunk retrieved using chunksize(p), which reads the size from the chunk’s metadata.
size = chunksize (p);
/* Little security check which won't hurt performance: the
allocator never wraps around at the end of the address space.
Therefore we can exclude some size values which might appear
here by accident or by "design" from some intruder. */
// Chunk pointer cannot point to an illegal address. And it must smaller or equal to -size (?).
// Chunk pointer must be properly aligned. These checks help prevent common vulnerabilities such as double-free or wild pointers.
if (__builtin_expect ((uintptr_t) p > (uintptr_t) -size, 0)
|| __builtin_expect (misaligned_chunk (p), 0))
malloc_printerr ("free(): invalid pointer");
/* We know that each chunk is at least MINSIZE bytes in size or a
multiple of MALLOC_ALIGNMENT. */
// Basic integrity checks to ensure the chunk was allocated by malloc and is being managed correctly.
if (__glibc_unlikely (size < MINSIZE || !aligned_OK (size)))
malloc_printerr ("free(): invalid size");
check_inuse_chunk(av, p);
#if USE_TCACHE
{
size_t tc_idx = csize2tidx (size);
if (tcache != NULL && tc_idx < mp_.tcache_bins)
{
/* Check to see if it's already in the tcache. */
tcache_entry *e = (tcache_entry *) chunk2mem (p);
/* This test succeeds on double free. However, we don't 100%
trust it (it also matches random payload data at a 1 in
2^<size_t> chance), so verify it's not an unlikely
coincidence before aborting. */
// The chunk is treated as a tcache_entry and its key is compared against the tcache_key to determine if it's already present.
if (__glibc_unlikely (e->key == tcache_key))
{
tcache_entry *tmp;
size_t cnt = 0;
LIBC_PROBE (memory_tcache_double_free, 2, e, tc_idx);
for (tmp = tcache->entries[tc_idx];
tmp;
tmp = REVEAL_PTR (tmp->next), ++cnt)
{
if (cnt >= mp_.tcache_count)
malloc_printerr ("free(): too many chunks detected in tcache");
if (__glibc_unlikely (!aligned_OK (tmp)))
malloc_printerr ("free(): unaligned chunk detected in tcache 2");
// If the key matches, further validate by iterating through the tcache entries for the given size index (tc_idx). It ensures that the chunk is not already in the tcache, which would indicate a double-free scenario.
if (tmp == e)
malloc_printerr ("free(): double free detected in tcache 2");
/* If we get here, it was a coincidence. We've wasted a
few cycles, but don't abort. */
}
}
// If the chunk is not already in the tcache and there is still room in the relevant tcache bin,
if (tcache->counts[tc_idx] < mp_.tcache_count)
{
// Add the chunk to tcache.
tcache_put (p, tc_idx);
return;
}
}
}
#endif
/*
If eligible, place chunk on a fastbin so it can be found
and used quickly in malloc.
*/
if ((unsigned long)(size) <= (unsigned long)(get_max_fast ())
#if TRIM_FASTBINS
/*
If TRIM_FASTBINS set, don't place chunks
bordering top into fastbins
*/
// By default, #define TRIM_FASTBINS 0. So the following codes won't be execute in normal situation.
// If the current chunk is a fastbin chunk, and the next chunk happens to be the top chunk, free'd chunk cannot be inserted into fastbin—well, normally this won't be executed.
&& (chunk_at_offset(p, size) != av->top)
#endif
) {
// Next chunk size cannot be smaller than SIZE_SZ*2 && bigger than system_mem (132KB by default)—detection for fake chunk insertion to fastbin! We need to BYPASS this for House of Spirit.
if (__builtin_expect (chunksize_nomask (chunk_at_offset (p, size))
<= CHUNK_HDR_SZ, 0)
|| __builtin_expect (chunksize (chunk_at_offset (p, size))
>= av->system_mem, 0))
{
bool fail = true;
/* We might not have a lock at this point and concurrent modifications
of system_mem might result in a false positive. Redo the test after
getting the lock. */
if (!have_lock)
{
__libc_lock_lock (av->mutex);
fail = (chunksize_nomask (chunk_at_offset (p, size)) <= CHUNK_HDR_SZ
|| chunksize (chunk_at_offset (p, size)) >= av->system_mem);
__libc_lock_unlock (av->mutex);
}
if (fail)
malloc_printerr ("free(): invalid next size (fast)");
}
// Set the mem part within the chunk to perturb_byte.
free_perturb (chunk2mem(p), size - CHUNK_HDR_SZ);
// Set up fastchunks. It is different from the old version.
atomic_store_relaxed (&av->have_fastchunks, true);
// Get corresponding fastbin head pointer. It will be 0 after initialization.
unsigned int idx = fastbin_index(size);
fb = &fastbin (av, idx);
/* Atomically link P to its fastbin: P->FD = *FB; *FB = P; */
mchunkptr old = *fb, old2;
if (SINGLE_THREAD_P)
{
/* Check that the top of the bin is not the record we are going to
add (i.e., double free). */
// Detection for Double Free! Make sure chunk being free'd isn't already the top of the bin. We need to BYPASS this (like by inserting another chunk in between)!
if (__builtin_expect (old == p, 0))
malloc_printerr ("double free or corruption (fasttop)");
p->fd = PROTECT_PTR (&p->fd, old);
*fb = p;
}
else
do
{
/* Check that the top of the bin is not the record we are going to
add (i.e., double free). */
if (__builtin_expect (old == p, 0))
malloc_printerr ("double free or corruption (fasttop)");
old2 = old;
p->fd = PROTECT_PTR (&p->fd, old);
}
// The chunk P is linked into the fastbin using an atomic compare-and-exchange operation to handle potential concurrency in multi-threaded scenarios.
while ((old = catomic_compare_and_exchange_val_rel (fb, p, old2))
!= old2);
/* Check that size of fastbin chunk at the top is the same as
size of the chunk that we are adding. We can dereference OLD
only if we have the lock, otherwise it might have already been
allocated again. */
// Make sure fastbin keeps the same before and after insertion.It's different from the old version check here.
if (have_lock && old != NULL
&& __builtin_expect (fastbin_index (chunksize (old)) != idx, 0))
malloc_printerr ("invalid fastbin entry (free)");
}
/*
Consolidate other non-mmapped chunks as they arrive.
*/
// When a chunk that was not allocated via mmap is freed, it goes through a process to potentially consolidate it with adjacent free chunks. This consolidation helps in reducing fragmentation within the heap.
// If the chunk is a regular heap chunk, it proceeds with the consolidation process.
else if (!chunk_is_mmapped(p)) {
/* If we're single-threaded, don't lock the arena. */
// Meaning the arena lock (av->mutex) does not need to be acquired because there's no risk of concurrent access.
if (SINGLE_THREAD_P)
have_lock = true;
// In multi-threaded scenarios, where other threads might concurrently modify the heap, the lock is required to safely perform the consolidation. The lock is acquired before starting the consolidation and released afterward if it wasn’t already locked (have_lock is false).
if (!have_lock)
__libc_lock_lock (av->mutex);
// The _int_free_merge_chunk function is called with the arena (av), the pointer to the chunk (p), and its size (size). This function will attempt to merge the free'd chunks with adjacent free chunks both before and after it in memory. Reduce fragmentation and potentially make larger allocations possible without needing to request more memory from the system.
// We will utilize this to perform chunk overlapping. But we need to BYPASS other restrictions like the checks in unlink().
_int_free_merge_chunk (av, p, size);
if (!have_lock)
__libc_lock_unlock (av->mutex);
}
/*
If the chunk was allocated via mmap, release via munmap().
*/
// returns chunk back to operating system.
else {
munmap_chunk (p);
}
}I have added a lot of comments in the code snippet. It shoule explain all free mechanisms if we carefully go through the code. Besides, we discover that there is one very important function at then end of _int_free. And it is _int_free_merge_chunk! We leverage this to result in chunk overlapping frequently after we gain some write primitives on the memory—so that we could overwrite pointers or data/instruction. I will then dive deeper into this function in next chapter.
_int_free_merge_chunk
The _int_free_merge_chunk function consolidates free'd chunks when _int_free is called automatically. As we have described above, it is to reduce fragmentation and potentially make larger allocations possible without needing to request more memory from the system. Before diving into the code, there are some important points we need to make clear before:
- Fastbin chunks won't be unlinked at anytime (so as tcachebin chunks of course).
- It consolidates lower-address free'd chunks first.
- Then it consolidates higher-address free'd chunks afterwards.
- After consolidation, the pointer of the new chunk will point to the orginal one with lower-address.
Besides, the part of Consolidate Backward is encapsulated into this function, which plays a critical part in the famous House of Einherjar attack.
OK. Let's now take a look at the source code and I will add my comments in it:
/* Try to merge chunk P of SIZE bytes with its neighbors. Put the
resulting chunk on the appropriate bin list. P must not be on a
bin list yet, and it can be in use. */
static void
_int_free_merge_chunk (mstate av, mchunkptr p, INTERNAL_SIZE_T size)
{
mchunkptr nextchunk = chunk_at_offset(p, size);
/* Lightweight tests: check whether the block is already the
top block. */
// The chunk we are going to free cannot be the top chunk.
if (__glibc_unlikely (p == av->top))
malloc_printerr ("double free or corruption (top)");
/* Or whether the next chunk is beyond the boundaries of the arena. */
// The next chunk of the chunk we are going to free (namely the victim chunk) cannot beyond the boudaries of arena.
if (__builtin_expect (contiguous (av)
&& (char *) nextchunk
>= ((char *) av->top + chunksize(av->top)), 0))
malloc_printerr ("double free or corruption (out)");
/* Or whether the block is actually not marked used. */
// The PRE_INUSE bit of the chunk we are going to free cannot be set to 1. Otherwise it's a situation like the fastbin chunk Double Free.
if (__glibc_unlikely (!prev_inuse(nextchunk)))
malloc_printerr ("double free or corruption (!prev)");
// Get the size of next chunk from its metedata. We can always fake it!
INTERNAL_SIZE_T nextsize = chunksize(nextchunk);
// Next chunk size valid check.
// Next chunk size must within range of SIZE_SZ*2 to system_mem.
if (__builtin_expect (chunksize_nomask (nextchunk) <= CHUNK_HDR_SZ, 0)
|| __builtin_expect (nextsize >= av->system_mem, 0))
malloc_printerr ("free(): invalid next size (normal)");
// Set the mem part of the pointer to be perturb_byte.
free_perturb (chunk2mem(p), size - CHUNK_HDR_SZ);
/* Consolidate backward. */
// Causion: this means when we free a chunk, the victim above the free'd chunk will be consolidated (if it's free'd of course)—then this is so called backward consolidation!
// It will be utilized in many scenarios, like House of Einherjar.
if (!prev_inuse(p))
{
INTERNAL_SIZE_T prevsize = prev_size (p);
size += prevsize;
p = chunk_at_offset(p, -((long) prevsize));
if (__glibc_unlikely (chunksize(p) != prevsize))
malloc_printerr ("corrupted size vs. prev_size while consolidating");
unlink_chunk (av, p);
}
/* Write the chunk header, maybe after merging with the following chunk. */
size = _int_free_create_chunk (av, p, size, nextchunk, nextsize);
_int_free_maybe_consolidate (av, size);
}The function is over. But we always applies other related functions to continue—We will need to insert the consolidated free'd chunk into unsorted bin usually. Let's talk about it subsequently at once.
_int_free_create_chunk
The Consolidate Forward is the opposite direction than the Consolidate Backward. They used to be written in the same code block. However, in the new version of glibc, it's defined here in the function _int_free_create_chunk. It's usually a subsequent part with the use of function _int_free_merge_chunk.
/* Create a chunk at P of SIZE bytes, with SIZE potentially increased
to cover the immediately following chunk NEXTCHUNK of NEXTSIZE
bytes (if NEXTCHUNK is unused). The chunk at P is not actually
read and does not have to be initialized. After creation, it is
placed on the appropriate bin list. The function returns the size
of the new chunk. */
static INTERNAL_SIZE_T
_int_free_create_chunk (mstate av, mchunkptr p, INTERNAL_SIZE_T size,
mchunkptr nextchunk, INTERNAL_SIZE_T nextsize)
{
// Make sure the next chunk is not the top chunk.
if (nextchunk != av->top)
{
/* get and clear inuse bit */
// Get the status of next chunk with its PRE_INUSE bit.
bool nextinuse = inuse_bit_at_offset (nextchunk, nextsize);
/* consolidate forward */
// If the chunk is not in use.
if (!nextinuse) {
// Unlink and consolidate
unlink_chunk (av, nextchunk);
size += nextsize;
} else
clear_inuse_bit_at_offset(nextchunk, 0);
// Or just clear PRE_INUSE bit of the current free'd chunk.
/*
Place the chunk in unsorted chunk list. Chunks are
not placed into regular bins until after they have
been given one chance to be used in malloc.
*/
// Place the chunk at the head of unsorted bin—sometimes we use this mechanism to leak the unsorted bin address, which is a libc related location.
mchunkptr bck = unsorted_chunks (av);
mchunkptr fwd = bck->fd;
// Simple check here. It looks like the unlink check but it's not.
if (__glibc_unlikely (fwd->bk != bck))
malloc_printerr ("free(): corrupted unsorted chunks");
p->fd = fwd;
p->bk = bck;
// If it is a large chunk, set the nextsize pointers to be both NULL.
if (!in_smallbin_range(size))
{
p->fd_nextsize = NULL;
p->bk_nextsize = NULL;
}
bck->fd = p;
fwd->bk = p;
set_head(p, size | PREV_INUSE);
set_foot(p, size);
check_free_chunk(av, p);
}
else
{
/* If the chunk borders the current high end of memory,
consolidate into top. */
// If it's adjacent to top chunk, just consolidate it into the top chunk.
size += nextsize;
set_head(p, size | PREV_INUSE);
av->top = p;
check_chunk(av, p);
}
return size;
}_int_free_maybe_consolidate
We introduce the __malloc_trim before in the malloc part. This mechanism in this function is one of its inplementation. The function _int_free_maybe_consolidate will be triggered if following situation is met:
/* If freeing a large space, consolidate possibly-surrounding
chunks. Then, if the total unused topmost memory exceeds trim
threshold, ask malloc_trim to reduce top. */
static void
_int_free_maybe_consolidate (mstate av, INTERNAL_SIZE_T size)
{
/* Unless max_fast is 0, we don't know if there are fastbins
bordering top, so we cannot tell for sure whether threshold has
been reached unless fastbins are consolidated. But we don't want
to consolidate on each free. As a compromise, consolidation is
performed if FASTBIN_CONSOLIDATION_THRESHOLD is reached. */
// If the consolidated chunk size is greater than FASTBIN_CONSOLIDATION_THRESHOLD (0x10000)
// Which always does—consolidated top chunk tends to be huge.
// Then it returns the excessive memory to system.
if (size >= FASTBIN_CONSOLIDATION_THRESHOLD)
{
if (atomic_load_relaxed (&av->have_fastchunks))
// Fastbin chunk will be consolidated here (I will need to examine how exactly it works via testing in gdb).
malloc_consolidate(av);
if (av == &main_arena)
{
#ifndef MORECORE_CANNOT_TRIM
// If consolidated top chunk is greater than mp_.trim_threshold
if (chunksize (av->top) >= mp_.trim_threshold)
// Trim the top chunk back to its pad value.
systrim (mp_.top_pad, av);
#endif
}
else
{
/* Always try heap_trim, even if the top chunk is not large,
because the corresponding heap might go away. */
// Non main_arena, just trim the heap staight forward.
heap_info *heap = heap_for_ptr (top (av));
assert (heap->ar_ptr == av);
heap_trim (heap, mp_.top_pad);
}
}
}Here's a weird global variable FASTBIN_CONSOLIDATION_THRESHOLD in the beginning of the above code. It looks like it's been set up for casual/heuristic and I cannot see any relationship between it and the fastbin except its function name. It's defined as 0x10000 (65536) by default. Just used to perform some conditional comparison in the _int_free_maybe_consolidate function.
/*<br> FASTBIN_CONSOLIDATION_THRESHOLD is the size of a chunk in free()<br> that triggers automatic consolidation of possibly-surrounding<br> fastbin chunks. This is a heuristic, so the exact value should not<br> matter too much. It is defined at half the default trim threshold as a<br> compromise heuristic to only attempt consolidation if it is likely<br> to lead to trimming. However, it is not dynamically tunable, since<br> consolidation reduces fragmentation surrounding large chunks even<br> if trimming is not used.<br> */<br><br>#define FASTBIN_CONSOLIDATION_THRESHOLD (65536UL)At last, if the chunk was allocated via mmap, just release it back to the system:
} else {
// If the chunk was allocated via mmap, release via munmap().
munmap_chunk(p);
}Free Algorithms
When a program calls free in an environment using Ptmalloc, the function will handle the deallocated memory in several specific ways, depending on the size and type of the memory block being free'd. I would name it the Free Algorithms. It would be less sophisticated than the Malloc Algorithms. Let's dive straight forward into it:
- Small Blocks:
- If the block is small enough to fit into a thread cache (tcache), Ptmalloc will try to put it back into the appropriate tcache bin for the thread that is freeing the memory. This allows for fast reallocation of small blocks of memory that are frequently used and released.
- If the thread cache is full or if tcaches are not enabled, the block will be returned to a fastbin or smallbin (depending on the configuration and size).
- Large Blocks:
- Larger blocks that do not fit into tcache or fastbins/smallbins are typically managed through largebins, which are designed to handle bigger chunks of memory. When a large block is free'd, Ptmalloc integrates it back into the arena from which it was allocated, attempting to merge it with adjacent free blocks to minimize fragmentation (this process is known as coalescing or consolidation).
- Mmap'ed Blocks:
- Blocks that were allocated directly using mmap (usually very large blocks) are returned directly to the system using munmap. This deallocation is straightforward because each mmap'd block is handled independently of the normal heap structures.
These should make all the free procedure crystally clear with all the analysis with the functions and algorithms.
Summary
When we perform heap exploitation, we need to consider all these rules in glibc to forge a delicately designed attack. It could be difficult for us to remember all details of the source code, but we will have a better understanding for Ptmalloc along with this analysis when performing a penetration test. I know this post is looooong and can be hard to understand. Anyway, it's the heap beast we need to face and beat it.
If you are patient enough to read until here, I am welcome to discuss for the potential misunderstanding in this article and your wonderful thoughts. As I mentioned in the beginning, I will update this post along with life-long learning on the updates of glibc versions. Finally, nice to meet you at the end of the post!

References (Click to view)
https://www.gnu.org/software/libc/manual/html_node/The-GNU-Allocator.html
https://blog.k3170makan.com/2018/12/glibc-heap-exploitation-basics.html
https://ctf-wiki.org/pwn/linux/user-mode/heap/ptmalloc2/implementation/malloc
Understanding the Heap - a beautiful mess (jackfromeast.site)
Ptmalloc - The GNU Allocator: A Deep Gothrough on How Malloc & Free Work by Axura is licensed under CC BY-NC-SA 4.0![]()
![]()
![]()
![]()
Comments | 3 comments
hi
@jayeshkaithwas Hi. Cool guy shows up
@axura Hola brodr